 夜雨聆风
夜雨聆风





「AI健自习室原创」重磅 Software 4.0:当代码变成对话,工作变成调度——从一个铃声工具看见未来 10 年
字数 7408,阅读大约需 38 分钟
🚀「AI健自习室原创」重磅 Software 4.0:当代码变成对话,工作变成调度——从一个铃声工具看见未来 10 年

微信公众号:[AI健自习室]关注Crypto与LLM技术、关注
AI-StudyLab。问题或建议,请公众号留言。
Info
这是一篇可能值得你重读 5 年的文章。关键词:Software 4.0 · Agentic Stack · Skills × MCP × LLM × 神经网络本文基于 Andrej Karpathy YC 2025 演讲、Anthropic / OpenAI / Cursor / Cognition 公开数据,结合作者本周开源的 ringtone-forge[1] v2.4 实战,提炼出一个可落地的工程范式。
上周末我做了一件小事:让一个 30 秒铃声生成工具里的 LLM 真正参与了处理决策。
跑完之后,我盯着那段 verify 失败、Claude 自动诊断、修参数、重跑、通过的日志看了很久。突然有种很强的感觉 —— 这不是个铃声工具,这是未来软件的最小验证。
未来 10 年的软件长什么样?商业模式怎么变?工程师做什么?产品给谁用?我把这些问题想清楚了,写下这篇文章。
文章很长,但每一段都是干货。如果你只看一段,请看 第三章「Software 4.0 五层范式」——那是核心。
🎵 一、从一首歌的 30 秒,看见软件的 30 年
事情是这样的。
我维护一个开源工具叫 ringtone-forge[1],做的事情很简单:喂一首歌进去,30 秒后吐出一段 AI 自动找的副歌做的铃声。从 v2.0 到 v2.3,它已经跑得很稳了 —— Demucs 神经网络分离人声、librosa 启发式找最响段、ffmpeg 做音量曲线,整套流程是经典的”AI + 工程”组合。
但是我的对外宣传里有句话一直让我心里发虚:「LLM Agent × 神经网络」。
事实上,v2.3 时代的”LLM Agent”只是外层 —— 用户在 Claude Code 里说「做铃声」,Skill 触发命令行,命令行跑完,LLM 解读结果。LLM 从未真正进入处理管线。
这周末我做了 v2.4。给 CLI 加了两个旗子:
# 用户说自然语言,LLM 翻译成参数ringtone-forge song.mp3 --tune "开头再轻一点"# LLM-in-the-loop: 自动跑、看、改、再跑ringtone-forge song.mp3 --agent --max-retries 3第二条命令,让真实的 Claude Sonnet 4.6 去跑了一首电子音乐 Brainiac_Maniac。第一次跑完,verify 报告 3 项失败。Claude 看了报告,给了一段诊断:
“起始振幅从 0.30 降到 0.15 以加深开头与高潮的对比(约 -16dB),并将渐入延长到 14 秒、sustain 缩短到 13 秒,使中段能稳定停留在接近高潮的响度。”
第二次跑完,7/7 全过。
那一刻我突然意识到 —— 这不是一个 feature。这是软件范式的换代。
LLM 不是被叫来用一下工具的”助手”,它是工程节点上真正在做推理判断的智能层。它读了我写的工程语言(dB、振幅、sustain),用工程语言回我(”加深对比度”、”稳定停留”),并给出可执行的参数。
我开始往后想。如果 ringtone-forge 是这样,那音乐生成、视频剪辑、文档处理、客服对话、数据分析、代码审查……所有 AI 落地的场景都会是这样。
那未来软件长什么样?这就是这篇文章要回答的问题。
🧬 二、Karpathy 的三个范式:我们在哪一站?
要看清未来,先要看懂演化。Andrej Karpathy 2025 年 6 月在 YC AI Startup School 做了一次演讲,叫 “Software Is Changing (Again)”[2]。这场演讲在科技圈被反复引用,因为它给了一个公认的演化框架:

|
|
|
|
|---|---|---|
| Software 1.0 |
|
|
| Software 2.0 |
|
|
| Software 3.0 |
|
|
Karpathy 的核心观察是:“Software 3.0 is eating Software 1.0 and 2.0”。LLMs 不再只是工具,它们开始扮演新的操作系统——你的代码运行在 OS 上,而 OS 运行在 LLM 上。
这个观察非常有力。但它还没说完。
在 ringtone-forge v2.4 里,我看到的是另一个层次的现象:
-
• LLM 在外层做 Agent(”做铃声”触发整个流程) -
• LLM 在内层做精细决策(看 verify 失败、提建议) -
• 神经网络(Demucs)做专业计算 -
• Skills(SKILL.md)封装可复用的领域经验 -
• MCP 协议连接外部工具(@upic 上传 CDN、@lark-cli 同步飞书) -
• 工程层(ffmpeg + Python)做确定性执行
这不是 Software 3.0,因为 3.0 的核心是”提示词即程序”,但这里的程序由多种”程序”协同构成:自然语言提示 + 神经网络权重 + Skill 文档 + MCP 协议调用 + 传统代码。
我把这种范式叫做 Software 4.0:Agentic Stack。
它不是在替代 1.0 / 2.0 / 3.0,而是把它们编织成一个完整的协作系统。每一层做它最擅长的事,LLM 在其中扮演调度者和决策者。
支撑这个判断的,是几个无法忽视的数据点:
📊 Anthropic 内部 70-90% 的代码是 AI 写的(Dario Amodei 公开承认)📊 OpenAI 内部 80% 的代码是 AI 写的(Greg Brockman, 2026)📊 Cursor 估值 $50B,3 年内做到 $2B ARR(一家做 IDE 的)📊 MCP 协议:97M 月度下载、10000+ 服务器、已捐给 Linux Foundation📊 AI 自主解决 70%+ 的软件 issues(12 个月前还不到 20%)📊 Anthropic IPO 据传估值 $900B
每一个数据点单独看都很惊人。把它们放一起看,规律一清二楚 —— 不是单个公司、单个工具的成功,是一整个范式正在成型。
下面我把这个范式拆开讲清楚。
🏛 三、Software 4.0:五层范式架构(核心)
我画了一张图,把这个范式的五层结构描述清楚:
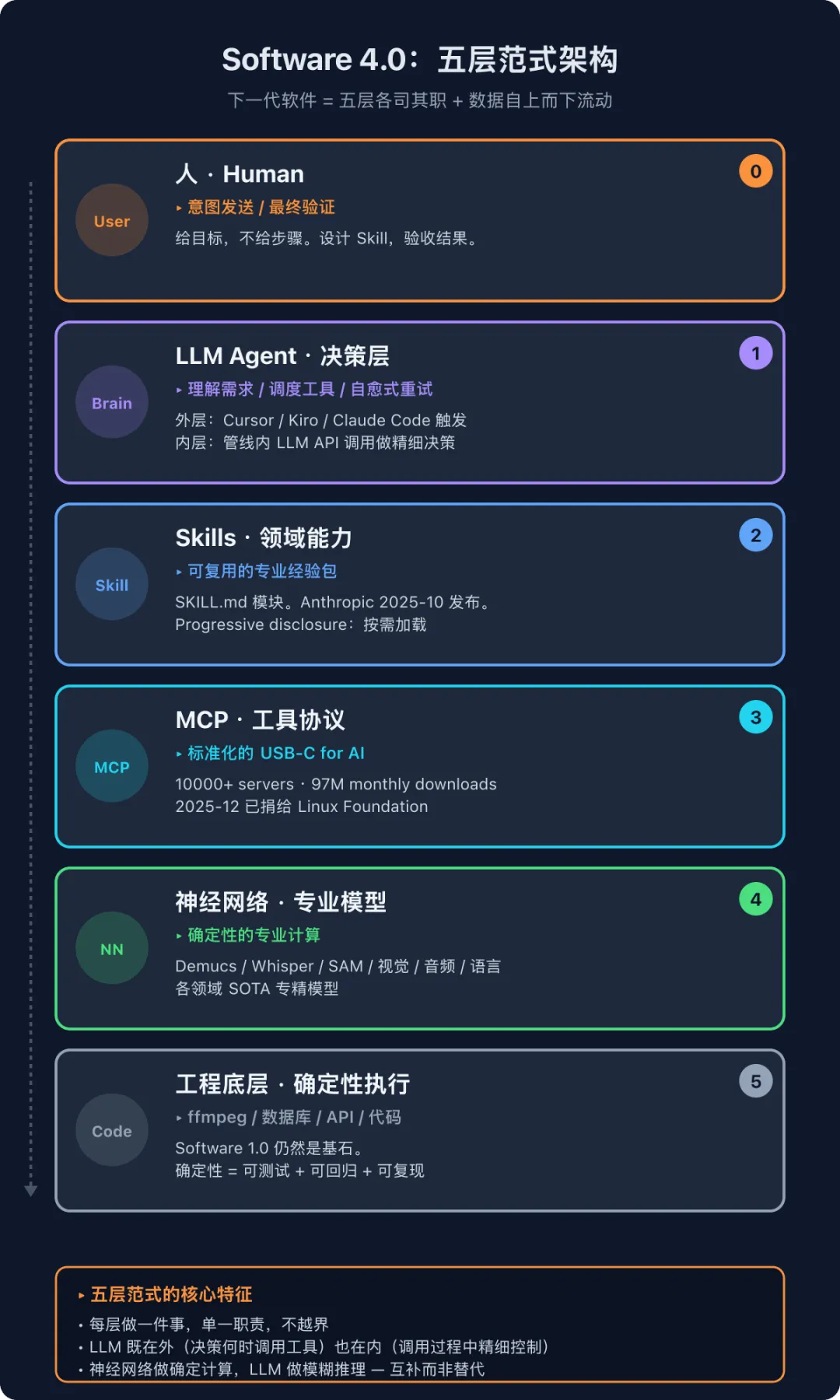
从上到下五层,每一层做一件不可替代的事:
Layer 0 · 人(Human)
角色:意图发送方 + 最终验证者
关键转变:人不再写代码、不再操作 GUI,而是给目标 / 设计 Skill / 验收结果。具体怎么实现,交给下面四层。
这是一个根本性的角色转移。在 Software 1.0 时代,人是”指令书写员”;在 4.0 时代,人是”意图设计师”和”质量审查员”。
Layer 1 · LLM Agent(决策层)
角色:理解需求 → 调度工具 → 自愈式重试
两个位置:
-
• 外层 Agent:在用户对话端,由 Cursor / Kiro / Claude Code 等触发。读你的自然语言,决定要不要调用工具、调用哪个工具、传什么参数。 -
• 内层 LLM:在管线内部,由工具自身发起 LLM API 调用做精细决策。比如 ringtone-forge 的 --tune把”更带感”翻译成rise=3, start_amp=0.65。
关键创新:v2.4 之前我以为 LLM 只在外层;做完才发现,双层 LLM 才是成熟形态。外层负责”何时触发 + 怎么解读”,内层负责”具体参数 + 失败自愈”。
Layer 2 · Skills(领域能力)
角色:可复用的专业经验包
Anthropic 在 2025 年 10 月发布了 Claude Skills[3] —— 文件式的能力模块,每个 Skill 是一个文件夹,包含 SKILL.md(指令)+ 可选脚本 + 可选资源。
关键设计:Progressive disclosure。Claude 启动时只加载每个 Skill 的 metadata(名称 + 描述),只有当任务匹配时才加载完整内容。这意味着你可以装一万个 Skill,上下文窗口也不会爆。
ringtone-forge 的 SKILL.md 现在是 265 行,包含了:
-
• 4 个可调维度(rise / sustain / drop / start_amp) -
• 11 条意图 → 参数的映射表 -
• 5 个对话示例 -
• LLM 后端选择指南
任何外部 Agent 看到这份文档,都能像专业音频工程师一样思考。
Layer 3 · MCP(工具协议)
角色:标准化的”USB-C for AI”
Model Context Protocol[4] 是 Anthropic 2024 年 11 月开源的协议,把 AI 应用连接外部工具/数据/服务的方式标准化。
两年时间发生了什么:
-
• 2024-11: Anthropic 发布 -
• 2025: 被 OpenAI / Google / Microsoft / Salesforce 采纳 -
• 2025-12: 捐给 Linux Foundation -
• 2026 早: 97M 月度下载、10000+ 服务器、行业事实标准
它的意义 类比就是 USB-C —— 在 USB-C 之前,每种设备都有独家接口;之后,”一根线连一切”。MCP 之前,每个 AI 工具都得自己写集成;之后,连一次写一次,所有 AI 都能用。
ringtone-forge 自己不直接用 MCP,但 ringtone-forge 运行在用 MCP 的环境里:上传 CDN 用 @upic MCP,同步飞书用 @lark-cli MCP,搜代码用 @builder-mcp。
Layer 4 · 神经网络(专业模型)
角色:确定性的专业计算
LLM 擅长模糊推理,但专业领域的精确计算还是要专业模型:
-
• 音频 → Demucs / Whisper -
• 视觉 → SAM / YOLO -
• 3D → Gaussian Splatting -
• 代码 → CodeLlama / Codestral
ringtone-forge 用 Demucs(Hybrid Transformer,ICASSP 2023 SOTA)把音乐分离成 4 个 stems(鼓 / 贝斯 / 其他 / 人声)。为什么不让 LLM 做这件事?因为 LLM 不擅长”听音频”。让神经网络做它擅长的,让 LLM 做它擅长的。这个分工原则,在 4.0 范式里被反复印证。
Layer 5 · 工程底层(确定性执行)
角色:ffmpeg / 数据库 / API / 代码
Software 1.0 的代码并没有消失,而是变成了最底下的基石。
为什么? 因为确定性 = 可测试 + 可回归 + 可复现。ringtone-forge 跑同一首歌应该总是给同样的输出 —— 这件事 LLM 做不到(输出有随机性)、神经网络做不到(不可解释),只有传统代码能保证。
工程层是 LLM 时代的”地心引力” —— 它定义了产品的下限。
这五层怎么协作?
回到那段 Brainiac_Maniac 的处理日志:
Layer 0 人: "做铃声 --agent --tune '前奏短一点'"Layer 1 LLM: 外层 Cursor 触发;内层 Claude 看 SKILL.md 决定参数Layer 2 Skills: 11 条映射表里命中"前奏短" → rise=8sLayer 3 MCP: 暂未触发(这步可选)Layer 4 NN: Demucs MPS 加速找出副歌位置 32.0s-62.0sLayer 5 Code: ffmpeg 裁剪 + envelope filter + alimiter 防爆音↓Layer 5 → 4 → 3 → 2 → 1 → 0 :返回 30 秒铃声 + verify 报告↓Layer 1 LLM: 报告说 3 项失败 → Claude 诊断 → 调整参数↓重新跑一遍 Layer 5 → 0:7/7 全过 ✓这就是未来软件的样子。
来看 ringtone-forge 的具体映射:

每一层做一件不可替代的事。如果你试图让 LLM 做神经网络的工作(让 GPT 直接听音频找副歌),你会得到一个慢 100 倍且不可靠的产品。如果你试图让神经网络做 LLM 的工作(用 ML 模型决定”温柔”对应什么参数),你需要标注 10 万条数据。让对的层做对的事,是 4.0 范式的核心智慧。
🛠 四、Skills + MCP + Agents:Anthropic 三件套
五层范式里最容易混淆的是 Layer 1-3。Anthropic 给了一套清晰的概念:

类比一下:
-
• Skills = 脑 — 知道怎么做 -
• MCP = 手 — 能够触达 -
• Agents = 身 — 自主完成
举一个具体例子让你秒懂:写一个自动 Code Review 的 Agent
任务:每个 PR 自动 reviewSkills(脑): - team-coding-style.skill.md(团队代码规范) - security-review.skill.md(安全检查清单)MCP(手): - GitHub MCP server(读 PR diff、写 comment) - Brave Search MCP server(查 CVE 数据库)Agents(身): - pr-reviewer subagent(独立上下文、只读权限) - 自主跑完整个流程,最后返回 review 评论没有 Skills,subagent 不知道你团队的规范没有 MCP,subagent 摸不到 GitHub没有 Agents 抽象,主对话上下文会被海量 PR 数据淹没
三个一起用,每层做不可替代的事。这就是 Anthropic 在 2025-2026 推出的三件套,也是 4.0 范式的具体实现。
🌊 五、四维变革:开发、商业、工作、交互
五层范式不只是一个技术架构图。它同时改写了软件行业的四个维度。每一个维度都在以肉眼可见的速度变化,而且这些变化彼此咬合 —— 你不可能只接受其中一个。
5.1 开发模式:从「写代码」到「写 Skill」

旧范式的开发流程是确定的:需求 → 架构 → 任务 → 代码 → 测试 → 上线。每一步都有人做。
新范式的流程是这样的:
-
1. Spec 对话 — 你和 LLM 对话,把意图变成可执行的 spec(不是 PRD,是更结构化的输入) -
2. 写 SKILL.md — 把领域经验外置化。不是写规范文档给人看,是写决策手册给 LLM 看 -
3. 选 / 写专业模型 — 需要 OCR 用 Tesseract、需要分离音源用 Demucs、需要分割图像用 SAM -
4. Agent 写代码 — 70-90% 的代码 AI 写。人 review、push back、调方向 -
5. Verify Gate — 不只是单元测试,还有”LLM 看 verify 报告自愈”那种推理式验证 -
6. Agent 运维 — Pager 响了,先让 agent 看 metric、查 log、提建议;不够再喊人
这不是渐进改变,是阶跃。
Andrej Karpathy 在 2025 年 2 月造了一个词:Vibe Coding[5] —— 用自然语言描述、看 AI 生成代码、不细看实现。这个词火了,但也被用滥了。2026 年 Forbes 的文章给出了更精确的概念:Vibe Engineering / Context Engineering[6] —— 不是不读代码,是把工程师的角色从”编码者”变成”上下文设计者”。
✦ 核心洞察:未来代码会越写越多(Anthropic 90% AI 写已经是事实),但 写代码的人会越来越少。多出来的产能去哪了?去给 LLM 做更好的 SKILL、更准的 verify、更复杂的 orchestration 了。
5.2 商业模式:per-seat 已死,outcome-based 上来

Microsoft 365、Salesforce、Slack、Zoom……过去 20 年统治软件世界的 SaaS 商业模式,全部基于一个假设:每个用户一个账号。
这个假设被 AI Agent 一击击穿。
理由很简单:Agent 不需要账号。如果你的产品 5 个员工每人 250;现在他们 1 个人加 5 个 agent 同时干活,但只有 1 个人登录 —— 这 5 个 agent 凭什么不付费?
Editorialge 2026 年的报告[7] 直接说:「per-seat 模式在 2026 年事实上已经死亡」。Forrester 同期说一样的话:“per-seat is being squeezed from both ends”。
那钱怎么收?三种新模式正在抢占主流:
|
|
|
|
|---|---|---|
| Per-Task |
|
|
| Outcome-based |
|
|
| Hybrid |
|
|
真实数据:
-
• Cursor:2B ARR。靠的是按用量+订阅复合定价 -
• Cognition (Devin):20 -
• AnyReach 报告:BPO 公司用 outcome-based 实现 200-300% ROI
✦ 核心洞察:如果你的 SaaS 还在按 seat 收费,你的同业可能已经在试水 outcome-based。每年同样收入,对方的客户增长更快、留存更高、续费率更稳。这场迁移已经开始,只是不一定在新闻头条上。
5.3 工作模式:从写代码到调度 Agent

这一节最敏感,但也最重要。
2020 年的工程师团队是正金字塔:少数架构师在顶端定方向,大量初级中级开发者在底部写代码。这是过去 60 年的常态。
2026 年起,金字塔在倒转。
数据已经在告诉我们这件事:
📊 70-90% 的代码在 Anthropic 内部由 AI 写📊 80% 在 OpenAI(Greg Brockman 公开承认)📊 84% 的开发者在用 AI 工具(Stack Overflow 2025)📊 70%+ 的软件 issues 由 AI 自主解决(12 个月前 < 20%)📊 Gartner:2028 前 90% 的工程师有 AI 助手📊 Fed NY 2025:CS 毕业生失业率 6.1-7.5%,是生物 / 艺术史毕业生的 2 倍
最后一个数据点最值得警觉。它在告诉我们:AI 对开发者的冲击不是”未来”,是”现在”。最先被冲击的不是高级工程师,是写第一行代码的初学者 —— 因为他们做的事,AI 做得最快、最便宜。
但工程师总数仍在增长(BLS 预测 2033 年前 +17.9%,是平均岗位增速的 5 倍)。这意味着:总盘子在涨,但分布在变。
新分布的金字塔顶端是这些角色:
-
• Spec / Skill 设计师 — 把意图、流程、领域知识写成 LLM 能消费的格式 -
• Agent Orchestrator — 编排多个 agent 协作完成复杂任务 -
• Verifier / 领域专家 — 用专业判断验证 agent 的输出 -
• Code Reviewer — 不写代码,但要看懂 AI 写的代码 -
• Coder(少数) — 仍然有人写底层、写关键路径、写 agent 都搞不定的部分
✦ 核心洞察:如果你今天还在以”打字快、记得多 API”为竞争力,未来 3 年会很被动。如果你以”理解业务、设计流程、判断质量”为竞争力,未来 10 年会越来越值钱。Karpathy 说,”This is the Decade of Agents” —— 那意味着这十年最稀缺的,是会”调度智能”的人。
5.4 交互模式:从 GUI 到 Agent-native
最后一个维度:你的产品给谁用?
过去 30 年的产品哲学:Build for Humans。漂亮的 UI、流畅的动效、好用的快捷键。
Karpathy 在他的演讲里指出,现在有第三类消费者出现了:
1. Humans → GUI(Graphical User Interface)2. Computers → APIs3. Agents → ???(agent-native interface) ← NEWAgents 不是人也不是程序。它们像人一样要读文档(不能直接读你的数据库),像程序一样不耐烦(不会等你 hover 鼠标)。它们读你的网页、解析你的 API、试错你的 SDK。
这意味着工具开发者要做一件新事:为 agent 设计接口。
-
• ❌ 你的文档全靠 hover 提示?agent 看不懂 -
• ❌ 你的 API 错误信息只有 “400 Bad Request”?agent 没法 retry -
• ❌ 你的功能藏在三层菜单里只有快捷键能开?agent 找不到
最简单的开始: 在你的网站根目录放一个 llms.txt。这是给 LLM 看的”网站地图”。
更深的实现 Every.to 提出过一个原则[8],叫 Parity:
“Whatever the user can do through the UI, the agent should be able to achieve through tools.”
UI 能做的,agent 都能做。这个原则一旦认真执行,会重新定义你产品的所有功能边界。
✦ 核心洞察:如果你的 SaaS 没有 agent-native API,过两年你的客户会用「经过竞品 agent 化的产品」。这不是替代,是新增长 —— 谁先支持 agent,谁先吃到 agent 经济的红利。
🛡 六、反思与边界:什么不会被 LLM 化
读到这里你可能觉得我在过度乐观。所以这一节专门讲 LLM 不能做什么、不该做什么。
6.1 Iron Man Suit:放大不是替代
Karpathy 在演讲里反复用了一个比喻:Iron Man 的钢铁侠战衣。
战衣给 Tony Stark 两件东西:
-
• Augmentation — 力量、传感器、信息(人能力的放大) -
• Autonomy — 战衣有时会自己动(独立的判断)
但 Tony 始终是穿着战衣的人,不是被战衣替代的人。
LLM 也是这样。它的最佳形态是放大人,不是替代人。 那些试图把人完全踢出循环的产品(”完全自主 agent”、”无人化客服”),普遍效果差,因为 LLM 有它的”参差性”。
OpenAI 前 CTO Mira Murati 在 Wired 最近的访谈[9] 里说:
“At some point we will have super-intelligent machines. But we think the best way to actually have many possible futures—good futures—is to keep humans in the loop for as long as possible.”
留住人。在循环里留住人,越久越好。 这是行业里最清醒的声音。
6.2 Demo-Product Gap:works.any() ≠ works.all()
Karpathy 的另一个金句:
“Demo is
works.any(), product isworks.all().”
意思是:演示只要任何一次能跑通就行;产品要每一次都跑通。 中间的差距,是过去 5 年所有 AI 公司从 demo 到 product 走过的最难一段路。
Tesla 自动驾驶就是经典案例:2014 年 Karpathy 坐过一次 demo(零人工干预),那时大家以为自动驾驶就要量产了。实际花了 10+ 年才到 L4。
ringtone-forge –agent 也跑过失败案例。同一首歌,跑 10 次有 1 次 LLM 给出了不合理的参数(rise=20s,铃声前 2/3 都是渐入)。这就是为什么 --max-retries 3 之外,最终 verify 失败的话,工具会退化到默认参数。
✦ 设计原则:永远给 LLM 一个 fallback。永远给人一个 escape hatch。Demo 阶段炫技,product 阶段稳定。
6.3 Jagged Intelligence:参差的智能
Karpathy 还造了一个词,叫 “Jagged Intelligence” —— 参差的智能。意思是 LLM 在不同任务上的能力像锯齿一样不均匀:
-
• ✓ 解奥数题:能拿 90 分 -
• ✗ 比大小:”9.11 比 9.9 大”(错)
“Some things work extremely well (by human standards) while some things fail catastrophically (again by human standards).”
人类的能力是渐进的:会识字的人通常会算简单加减;会算微积分的人通常能写人话。LLM 不是这样 —— 它在某些维度超越博士,在另一些维度低于小学生。
这意味着:你不能像信任同事一样信任 LLM。你要把它当成「有时是博士、有时是醉汉的同事」,给它配 verify gate、给它配 fallback、给它的关键决策配人审核。
6.4 Anterograde Amnesia:失忆症
LLM 的另一个固有缺陷:没有长期记忆。每次对话都是新的,上下文窗口一关,全忘。
Karpathy 把这比作电影 《记忆碎片》(Memento)[10] 的主角 —— 短期记忆完整、长期记忆被切断。
这意味着两件事:
-
1. 关键信息要外置化 —— 写 SKILL.md,写 docs,写 CLAUDE.md。不要指望 LLM “记住” -
2. 复杂任务要工程化 —— 长流程拆成短步骤,每步独立可恢复
这也是为什么 Anthropic 的 Skills 设计是 progressive disclosure —— Claude 只先看 metadata,关键时才看完整内容。这是给”失忆症患者”开的药方。
🎯 七、实战指引:今天能做的 5 件事
读到这里,你可能想问:「好,那我今天能做什么?」
我把过去一周做 ringtone-forge v2.4 学到的,浓缩成 5 条具体动作。任何角色都能从今天开始做。
1️⃣ Skill-first 思维
改变:先写 SKILL.md,再写代码。
每次开始新功能 / 新任务,先问自己:「如果让一个外部 LLM 替我执行这件事,它需要知道什么?」把这些写下来,就是你的 SKILL.md。
它会强迫你:
-
• 把”隐性经验”显性化 -
• 把决策规则结构化 -
• 把意图 → 参数的映射写清楚
结果:你的代码会更清楚(因为你想清楚了),你的 LLM 会更好用(因为有了可消费的上下文)。
实操:去 github.com/anthropics/skills[3] 看官方 skills 怎么写的。
2️⃣ 把”专业经验”externalize 给 LLM
改变:不要把工程师的判断锁在脑子里。
ringtone-forge 的 verify 模块原来是规则引擎:”如果 RMS@29.7s[11] 大于 -40 dB 就 fail”。v2.4 做了什么?让 LLM 看 verify 报告,自己想办法修。
这件事的精髓不是”把规则换成 LLM”,是把工程师在 oncall 时做的诊断推理外置到 LLM:
原来:人 oncall + 规则引擎检测 → 出问题人来调现在:规则引擎检测 → LLM 当一线 oncall → 修不好再升级到人效果:把工程师的”工程经验”变成可复用的”软件资产”。
3️⃣ 多层 verify gate
改变:从”通过/失败”二元判断,变成”多层渐进验证”。
Layer 1: 基础规则检测(duration / format / size)Layer 2: 启发式质量检测(RMS / peak / LUFS)Layer 3: LLM 推理式验证("这段听起来像副歌吗?")Layer 4: 人最终验收(重要发布的最终守门)关键:不要让 LLM 替代规则、也不要让规则替代 LLM。叠在一起,互相补充。
4️⃣ 给你的产品加 Agent-native API
改变:从”为人设计”扩展到”为 agent 设计”。
最低成本:根目录放 llms.txt。这是给 LLM 看的网站地图,告诉它你的服务是什么、有哪些核心 endpoint、文档在哪。
中等成本:写 MCP server。让你的 SaaS 能被 Cursor / Kiro / Claude Code 直接调用。这个事 Anthropic、OpenAI、Cursor 都在大力推 —— 跟着趋势做。
高成本:做 Parity。每个 UI 功能都暴露成 agent 可调用的 tool。这是大改造,但回报极高 —— 你的客户会发现,他们的 agent 流程开始离不开你。
5️⃣ 重新审视你的商业模式
改变:哪怕你今天还是 per-seat,也至少在某个产品线试 outcome-based。
最小尝试:选一个高价值场景(比如客服转化、销售线索、文档处理),加一个 outcome-based 的定价档位。让客户选。
预期发现:愿意按 outcome 付费的客户,单价会更高、留存会更稳、续费会更顺。原因很简单 —— 他们买的是结果,不是工具。
✦ 关于这 5 条:你不需要全做。但如果一条都没做,你大概率正在被范式转换甩开。先做 1️⃣ —— 它最便宜,也最改变思维方式。
🔮 八、未来 5 年图景
把所有线索汇总,我画了一条时间线:
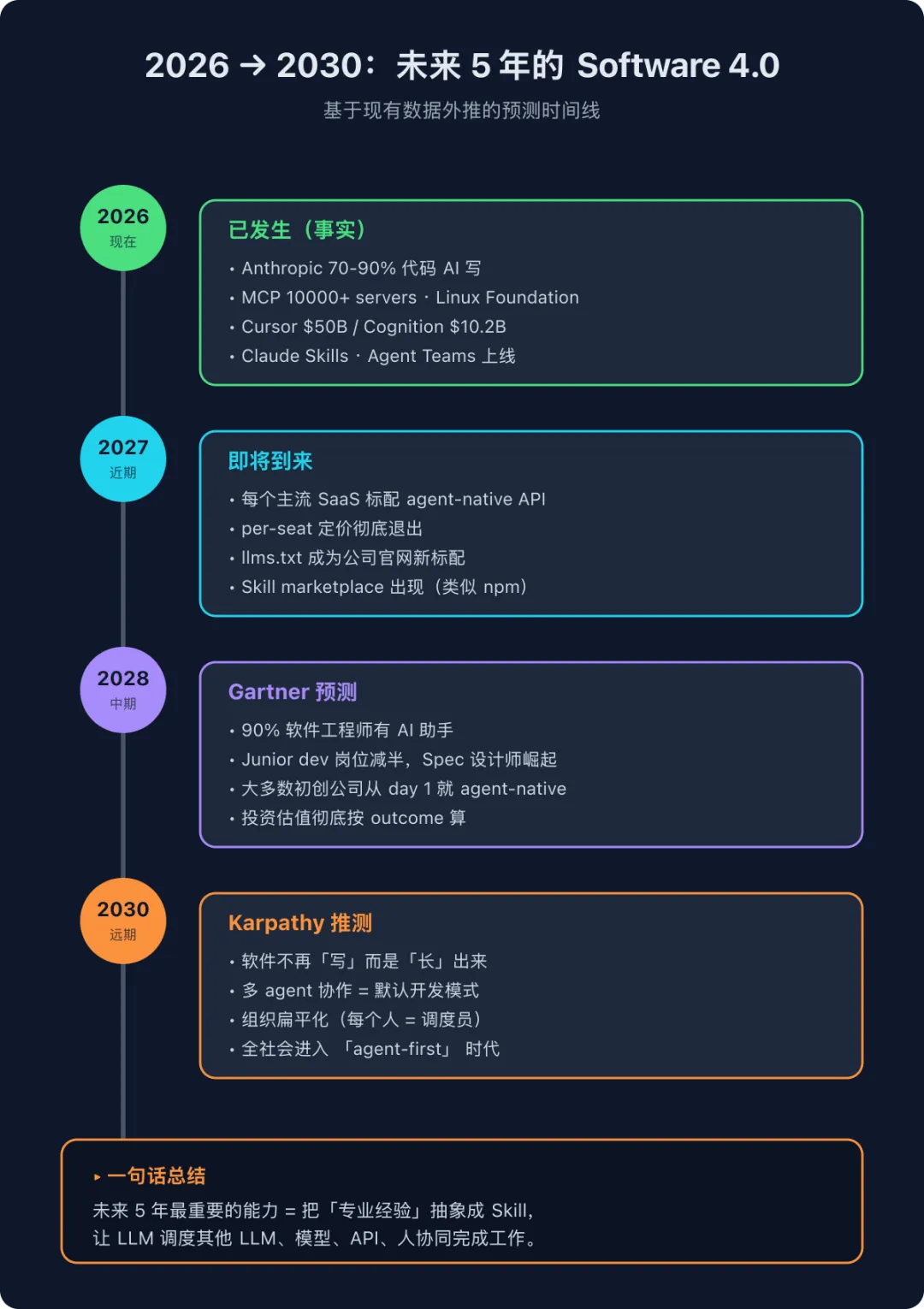
2026(现在)—— 这些已经发生:
-
• Anthropic 70-90% 代码 AI 写(CEO 公开承认) -
• MCP 10000+ servers,已捐给 Linux Foundation -
• Cursor 10.2B -
• Claude Skills / Agent Teams 上线 -
• per-seat 模式开始崩塌
2027(近期)—— 这些即将到来:
-
• 每个主流 SaaS 标配 agent-native API -
• per-seat 定价彻底退出(变成可选项) -
• llms.txt成为公司官网新标配 -
• 出现类似 npm 的 Skill marketplace
2028(中期)—— Gartner 已预测:
-
• 90% 软件工程师有 AI 助手 -
• Junior dev 岗位减半,Spec 设计师崛起 -
• 大多数初创公司从 day 1 就 agent-native -
• 投资估值彻底按 outcome 算
2030(远期)—— Karpathy 推测:
-
• 软件不再”写”而是”长”出来 -
• 多 agent 协作 = 默认开发模式 -
• 组织扁平化(每个人 = 调度员) -
• 全社会进入 「agent-first」 时代
✦ 一句话总结:未来 5 年最重要的能力 = 把「专业经验」抽象成 Skill,让 LLM 调度其他 LLM、模型、API、人协同完成工作。
🎵 九、回到那首歌的 30 秒
写到这里我想回到开头那首歌。
ringtone-forge 不是个特殊案例。任何 AI 落地应用都会经历:
-
1. 工程层做工具(Software 1.0) -
2. 加神经网络做计算(Software 2.0) -
3. 加 LLM 做决策(Software 3.0) -
4. 加 Skills 做复用(Software 4.0 第一步) -
5. 加 MCP 做连接(Software 4.0 第二步)
这就是 Software 4.0 的样子。它不只是技术变革,是整个行业的重新洗牌:
-
• 开发者:你的代码会被 agent 写 -
• 创业者:你的 SaaS 商业模式会被重构 -
• 产品经理:你的用户可能是 agent -
• 投资人:估值逻辑被颠覆(Cursor 12 个月 12x) -
• 从业者:你的角色金字塔位置会上移
5 年后回头看,可能会发现:那个 30 秒铃声工具,是你看见未来的第一扇窗户。
不是因为它特别 —— 而是因为它普通。它做的事情简单到不能再简单(找副歌 + 切片),但它的范式适用于所有 AI 落地应用。
每一个值得做的产品都有一段「Brainiac_Maniac 时刻」—— 你的工具第一次失败、LLM 看着失败报告说「这样改」、改完之后真的成了。
那一刻,不是工具变得更智能。是「智能」第一次进入了你的工程链路。
📚 参考资料
核心来源
-
1. Andrej Karpathy: Software Is Changing (Again)[2] — YC AI Startup School 2025 演讲 -
2. Verdent: Skills vs MCP vs Agents[12] — 三层架构权威解读 -
3. Every.to: Agent-Native Architectures[8] — Parity 原则 -
4. Anthropic Skills 官方仓库[3] — Skill 标准实现
数据来源
-
5. CIO: AI coding agents[13] — Anthropic 70-90% 代码 AI 写 -
6. Forbes: Software Engineering Cooked?[14] — Fed NY 失业率数据 -
7. Editorialge: Per-seat is Dead[7] — 商业模式变革 -
8. Bessemer: AI Pricing Playbook[15] — Outcome-based 实战 -
9. Forrester: AI Workforce[6] — Vibe Engineering
实战项目
-
10. ringtone-forge[1] — 我的项目,本文的灵感起点(MIT 开源) -
11. Model Context Protocol[4] — MCP 官方文档 -
12. Claude Skills GitHub[3] — 67k stars 学习资源
💬 互动时间:
✦ 你的产品 / 团队 / 工作流,目前在 Software 几点几?✦ 你认同「五层范式」的拆解吗?还是你觉得有更好的切分?✦ 你最焦虑的是「写代码岗位」还是最兴奋的是「Spec 设计岗位」?✦ 如果只能从 5 条实战指引里选 1 条做,你会选哪条?为什么?
如果这篇有帮助,点个”在看” + 转发给写代码的同学、做产品的同事、做投资的朋友 —— 这是关于未来 10 年的事,值得讨论。
也欢迎来 GitHub 看看 ringtone-forge:https://github.com/neosun100/ringtone-forge ⭐
👆 扫码关注 AI健自习室,深入学习 AI / Crypto / 工程实践
这篇文章是我从一个 30 秒铃声工具里看见的未来。5 年后再看,可能会发现:原来那时候已经全都开始了。愿你也找到属于自己的「Brainiac_Maniac 时刻」。
引用链接
[1] ringtone-forge: https://github.com/neosun100/ringtone-forge[2] “Software Is Changing (Again)”: https://www.latent.space/p/s3[3] Claude Skills: https://github.com/anthropics/skills[4] Model Context Protocol: https://docs.anthropic.com/en/docs/agents-and-tools/mcp[5] **Vibe Coding**: https://en.wikipedia.org/wiki/Vibe_coding[6] **Vibe Engineering / Context Engineering**: https://www.forbes.com/sites/forrester/2026/02/02/ai-doesnt-replace-the-development-workforce—it-changes-it/[7] Editorialge 2026 年的报告: https://editorialge.com/saas/[8] Every.to 提出过一个原则: https://every.to/guides/agent-native[9] Wired 最近的访谈: https://www.wired.com/story/mira-murati-humans-in-the-loop-ai-models-thinking-machines/[10] 《记忆碎片》(Memento): https://en.wikipedia.org/wiki/Memento_(film)[11] RMS@29.7s: mailto:RMS@29.7s[12] Verdent: Skills vs MCP vs Agents: https://www.verdent.ai/guides/claude-skills-vs-mcp-agents-comparison[13] CIO: AI coding agents: https://www.cio.com/article/4166029/the-570k-canary-what-ai-coding-agents-reveal-about-enterprise-ais-real-gaps.html[14] Forbes: Software Engineering Cooked?: https://www.forbes.com/sites/timkeary/2026/04/27/is-software-engineering-cooked-the-future-of-development-post-ai/[15] Bessemer: AI Pricing Playbook: https://www.bvp.com/atlas/the-ai-pricing-and-monetization-playbook