 夜雨聆风
夜雨聆风





OpenClaw 退潮之后:AI 工具真正留下来的,不是热度,而是组织能力
Treeify 专注于【AI测试用例设计】,把测试设计变成经验可沉淀、可持续迭代的过程——用结构化方法把问题空间拆开,再生成更少但更有覆盖的用例。
欢迎参加社区共创/免费内测:【填写问卷】进内测共创群,获得 Treeify 内测资格 / MCP Server 试用。
摘要
OpenClaw 的降温,不是 AI Agent 的失败,而是一次很典型的提醒:能演示,不等于能进入工作流;能完成一次任务,不等于能沉淀组织能力。对企业来说,AI 工具真正值得关注的,不是它有多快火起来,而是它能不能让下一次工作比这一次更聪明。

正文
如果你这几个月关注 AI 圈,大概率见过 OpenClaw。
有人把它叫成“龙虾”,有人写安装教程,有人录部署视频,有人做培训课,有人把它包装成企业 Agent 方案。朋友圈、社群、技术博客里,OpenClaw 一度像一个新的入口:好像只要把它跑起来,我们就离 AI Agent 时代更近了一步。
它确实让很多人第一次直观看到:
AI 不只是聊天框里的回答者。它可以调用工具、访问文件、连接系统、执行任务,甚至帮人处理一串复杂操作。
但热度退得也很快。
根据 AICPB 发布的 2026 年 4 月 AI 龙虾增速榜,OpenClaw 当月 Web 访问量为 14.54M,月环比下降 50.67%;同一榜单中,QClaw、nanoclaw.dev、有道龙虾、copaw、easyclaw 等 Claw 类产品也出现了不同程度的访问量下滑。新浪财经转载非凡产研的 4 月 AI Web 榜单观察时,也把这次变化概括为“OpenClaw 腰斩”。
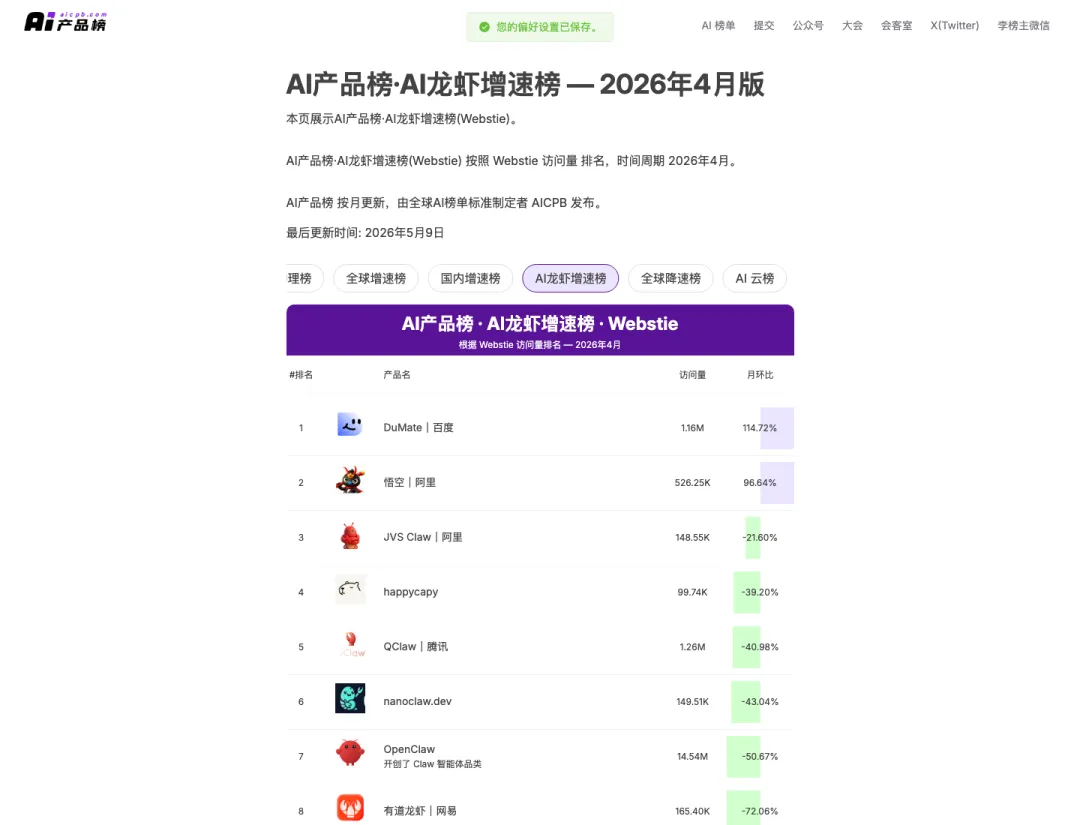
图:AICPB「AI 龙虾增速榜 – 2026 年 4 月版」页面,OpenClaw 当月访问量 14.54M,月环比 -50.67%。
看到这样的数据,最容易得出的结论是:
AI Agent 又一个泡沫破了。
但我更倾向于另一个判断:
OpenClaw 的退潮,不是 AI Agent 没有价值,而是新鲜感退去之后,真正的问题终于浮了出来。
热点解决的是“我也试过”,不是“我真的用上了”
一项新技术刚火的时候,很多团队的第一反应是先追上。
先装起来。先跑通 Demo。先接一个大模型。先试几个插件。先让 AI 帮忙写文档、整理邮件、生成 PPT、跑脚本。
这些动作都没错。
问题在于,很多团队会把“我也试过”误认为“我已经完成 AI 转型”。
这两件事差得很远。
一个工具被安装,只说明它进入了电脑。一个流程被自动化,只说明它完成了一次任务。一个 Agent 能调用工具,只说明它具备执行能力。
但组织真正关心的不是这些。
组织真正关心的是:
这件事以后能不能稳定发生?出错了谁能发现、谁能纠正、谁来负责?不同角色能不能在同一个流程里协作?这次修正过的经验,下次还能不能被系统记住?
如果这些问题没有答案,工具越多,反而越容易制造一种新的忙碌。
以前我们忙着开会、写表格、对齐流程。
现在我们忙着安装工具、测试模型、调 Prompt、研究 Agent、追各种新名词。
形式更先进了,但组织未必真的变聪明了。
OpenClaw 真正戳中的,是大家对 Agent 的想象
这也是为什么,我不认为应该简单嘲笑 OpenClaw 的降温。
它火起来,有它合理的一面。
OpenClaw 官网展示的使用场景里,包括处理邮件、复盘会议、排期、创建发票、检查构建失败、修改部署配置、提交 PR 等任务。这些场景之所以吸引人,是因为它们都不像“问 AI 一个问题”那么轻。
它们更接近真实工作:
要理解上下文。要调用外部工具。要跨多个步骤推进。要把结果写回系统。有时还要对人的决策产生影响。
这正是 Agent 最有想象力的地方。
但也正因为如此,Agent 从 Demo 进入企业生产环境时,会比普通聊天工具面对更高的门槛。
聊天工具答错了,通常只是答案不准。
Agent 做错了,可能会删错文件、发错邮件、改错配置、泄露数据、触发错误流程。
所以,企业对 Agent 的问题不会停留在“它能不能做”,而会很快变成:
-
• 它能不能在权限边界内做? -
• 它能不能解释为什么这么做? -
• 它能不能在关键节点停下来让人确认? -
• 它能不能留下过程记录,方便审计和复盘? -
• 它能不能把人的纠正转化为下次更好的行为?
这些问题听起来没有“全民养龙虾”热闹,却决定了一个 AI 工具能不能真正留下来。
Agent 越能做事,越需要治理机制
围绕 Agent 的安全讨论,其实已经指向了同一个问题。
一篇关于 Agentic AI 安全的综述指出,具备规划、工具使用、记忆和自主性的 Agent 系统,会带来区别于传统软件安全和传统 AI 安全的新风险。另一篇 2026 年 5 月的 AgentTrust 论文把风险说得更具体:现代 AI Agent 会通过文件操作、Shell 命令、HTTP 请求、数据库查询等工具调用产生真实副作用,一次不安全动作就可能导致误删、凭证暴露或数据外泄。
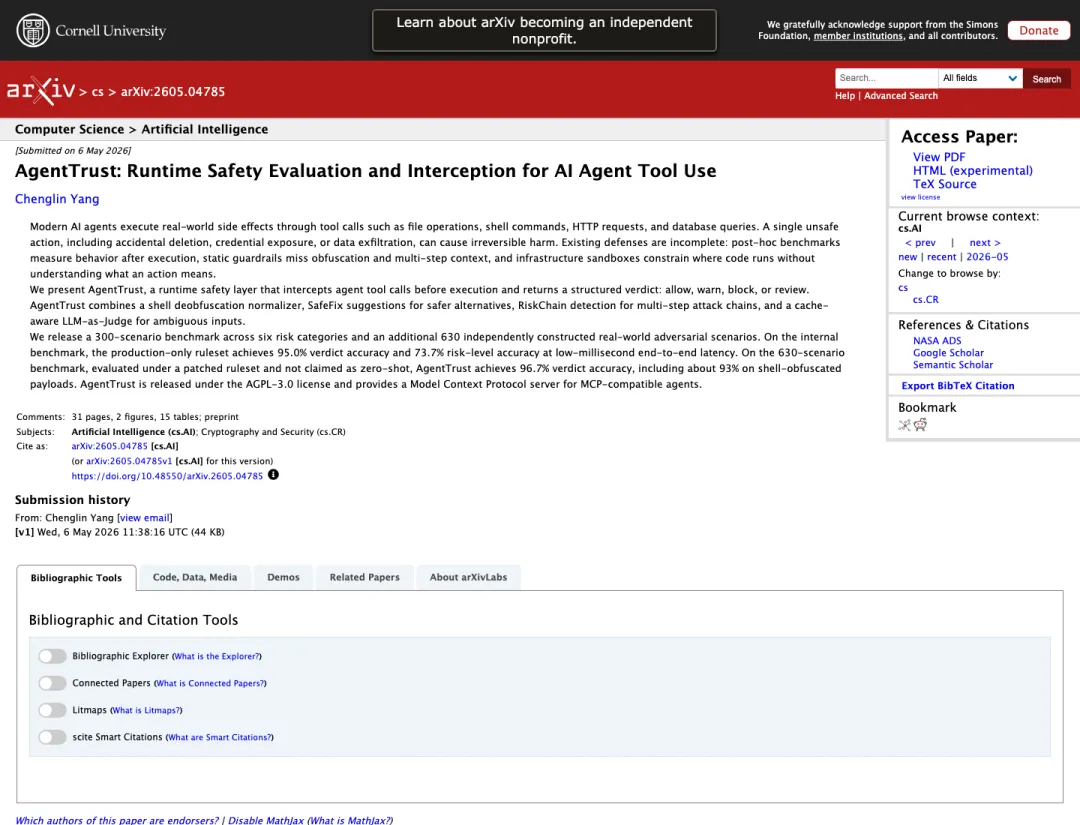
图:arXiv 论文《AgentTrust: Runtime Safety Evaluation and Interception for AI Agent Tool Use》摘要页,文中提到 file operations、shell commands、HTTP requests、database queries 等 Agent 工具调用带来的真实副作用风险。
这不是说 Agent 不该做事。
恰恰相反,Agent 的价值就在于它能做事。
但一个能做事的 AI,必须被放进机制里。
这个机制至少包括四件事:
第一,边界。哪些系统能访问,哪些操作能执行,哪些数据不能碰。
第二,过程。AI 为什么这样拆任务,中间用了什么资料,做了哪些判断。
第三,确认。哪些动作可以自动完成,哪些动作必须让人审核。
第四,沉淀。人每次纠正 AI 之后,这个纠正能不能成为下次可复用的经验。
很多 AI 工具的问题,不是没有能力,而是只有能力,没有机制。
这也是 OpenClaw 这类热点工具给企业的真实启发:
我们不能只问“这个 Agent 能帮我做什么”,还要问“它会怎样进入我的工作系统”。
企业需要的不是更多工具,而是更少从头再来
很多企业做 AI 转型时,很容易把工具采购当成能力建设。
买了一个工具,就好像团队具备了 AI 能力。
接了一个模型,就好像业务已经完成智能化。
搭了几个 Agent,就好像组织进入了自动化时代。
但真实情况往往更朴素:
工具上线了,流程没有变。模型接入了,知识没有沉淀。Agent 跑起来了,组织能力没有升级。每一次任务,依然依赖个人临场发挥。
这就是很多 AI 工具先兴奋、后闲置的原因。
它们确实能解决一些当下的问题,但没有改变组织的工作方式。
一个 AI 工具如果只能帮你完成“这一次任务”,它带来的是短期效率。
但如果它能把人在任务中的判断、修正、偏好、风险意识和方法沉淀下来,并在下一次任务中复用,它才有机会带来长期能力。
换句话说,企业真正需要的不是更多工具,而是更少从头再来。
这句话放到测试设计里,会更明显。
测试设计最怕的,不是 AI 生成慢,而是每次都像第一次
很多团队第一次接触 AI 测试用例生成时,最关心的问题通常是:
能不能根据需求直接生成测试用例?
这个问题合理。
测试设计耗时、重复、依赖经验。如果 AI 能快速生成一批用例,当然能提高效率。
但真正用起来后,第二层问题很快就会出现:
生成得不全怎么办?覆盖角度不够怎么办?业务规则遗漏怎么办?异常场景没想到怎么办?为什么换一个需求,效果又不稳定了?
这时候,很多人会把问题归因于模型能力。
模型还不够强。Prompt 还不够好。Agent 还不够智能。上下文还不够完整。
这些因素当然重要。
但它们不是最根本的问题。
更根本的问题是:
测试设计不是单纯的文本生成,而是经验驱动的专业判断。
同一份需求,给不同测试人员,最后写出来的测试用例一定不一样。
有人更关注主流程,有人更敏感于异常路径。有人会想到权限边界,有人会补充数据一致性。有人会关注合规风险,有人会根据过往线上事故补充隐藏场景。
差异不在于他们读到的需求不同,而在于他们带进需求里的经验不同。
这就是测试设计里最难被 AI 一次性生成出来的东西。
AI 默认不知道你的团队踩过哪些坑
AI 可以读取需求文档。
AI 可以理解业务流程。
AI 可以按照常见测试方法补充边界值、异常流、权限、兼容性等场景。
但 AI 默认不知道你的团队过去踩过什么坑。
它不知道你们系统里某类状态变更最容易出问题。它不知道你们公司对某些业务规则特别敏感。它不知道某个行业里哪些风险必须优先覆盖。它不知道资深测试人员在评审时为什么删掉某些用例,又为什么补充另一些场景。
这些知识通常不在需求文档里。
它藏在一次次评审、修改、返工、线上问题和项目复盘里。
举个简单例子。
如果需求里写“优惠券在用户下单时自动发放并可抵扣”,普通 AI 很可能会生成领取、使用、过期、金额校验等测试点。
这些没有错。
但一个有经验的测试人员可能会继续追问:
优惠券发放失败后是否重试?用户取消订单后优惠券是否退回?同一用户多端同时下单会不会重复抵扣?运营修改活动规则后,旧券按旧规则还是新规则计算?退款、部分退款、超时未支付时,券状态如何变化?
这些问题不只是“更多用例”。
它们背后是一套风险判断。
如果系统不能把这套判断沉淀下来,AI 每次遇到类似需求,仍然要靠人重新提醒。
第一次生成看起来很快。第二次还是要大量人工修改。第三次遇到相似问题,仍然从头再来。
团队没有变聪明,系统也没有变聪明。
这不是 AI 测试的终点。
这只是“AI 生成器”的局限。
Treeify 想解决的,是让测试经验进入系统
这也是我们做 Treeify 时一直坚持的方向。
Treeify 不想把自己做成一个简单的“一键生成测试用例”工具。
因为一次性生成看起来很快,但它解决不了测试设计里最关键的问题:
-
• 如何让生成结果越来越符合团队经验? -
• 如何让资深测试人员的判断被沉淀下来? -
• 如何让组织在多个项目中复用自己的测试方法? -
• 如何让 AI 不只是回答,而是持续学习团队的工作方式?
所以 Treeify 更强调的是一个可检查、可修正、可沉淀的 AI 测试设计过程。
它不是直接跳到最终测试用例,而是把测试设计拆成几个更可控的阶段:
-
1. 需求理解; -
2. 测试对象分析; -
3. 测试场景生成; -
4. 结果审查与修改; -
5. 经验沉淀为 Skills; -
6. 后续任务中持续复用。
这样做的目的,不是增加流程感,而是把 AI 的输出过程变得可见。
当用户发现某个测试对象遗漏了,可以修正。
当用户发现某类场景不完整,可以补充。
当用户发现某种业务风险需要长期关注,可以沉淀为 Skill。
当团队多次在类似需求中做出相似修正,这些经验就不应该永远停留在人的脑子里,也不应该散落在聊天记录、评审评论和复盘文档里。
它应该进入系统,成为组织共享的测试能力。
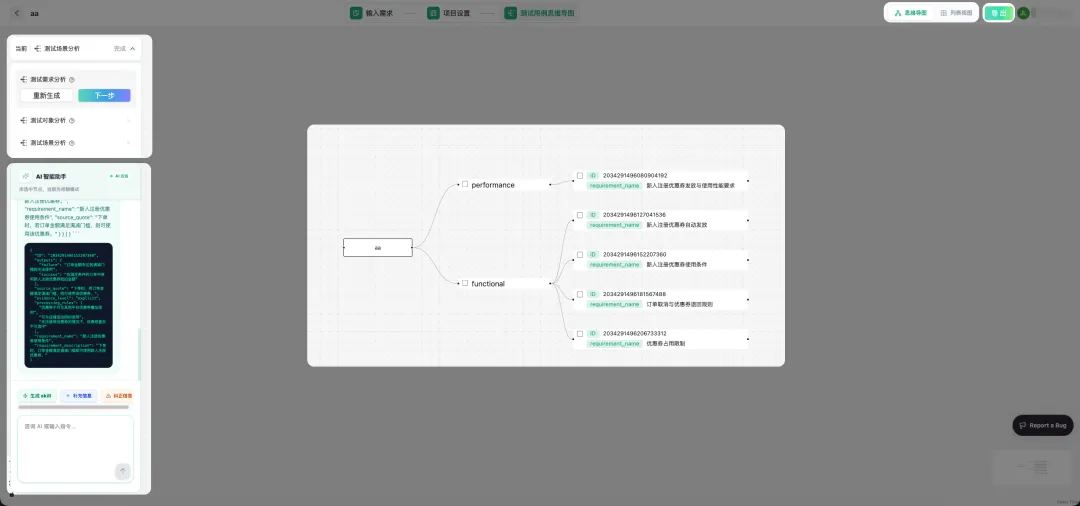
图:Treeify 测试设计流程示例。测试人员可以在需求分析、测试对象分析、测试场景生成等阶段检查、修正和补充 AI 输出。
这才是 Treeify 真正想解决的问题。
不是让 AI 替你一次性写出一堆测试用例。
而是让 AI 在你的工作过程中,逐步理解你的测试方法、团队经验和行业规则。
真正留下来的,是让组织下一次更聪明的产品
OpenClaw 的退潮,不应该让我们得出“不要追 AI”的结论。
相反,它提醒我们要更认真地理解 AI。
不要只看一个工具火不火。要看它能不能进入真实工作流。
不要只看它能不能完成一次任务。要看它能不能留下过程、反馈和经验。
不要只看它是不是 Agent。要看它有没有边界、治理、协作和沉淀机制。
对测试设计来说,这一点尤其重要。
测试用例写得好不好,从来不只是“会不会生成文本”的问题。
它背后是需求理解、风险判断、覆盖建模、异常意识、业务经验和行业知识的综合结果。
如果这些东西不能沉淀,再强的模型也只能解决一部分问题。
而如果这些东西能被持续沉淀,AI 才可能从一个临时助手,变成组织能力的一部分。
这也是 Treeify 所相信的方向:
AI 工具的价值,不在于一次生成得多快,而在于它能不能让下一次生成更接近组织真正的经验。
热点会退潮。
工具会更替。
但真正留下来的,一定是那些能把人的经验变成组织能力的产品。