夜雨聆风
夜雨聆风





OpenClaw 拆解⑤丨每次 API 调用 50-130K tokens,六层 Prompt 的预算战争
这是 OpenClaw 架构拆解系列的最后一篇。
前面四篇分别聊了 Agent Loop、System Prompt、Memory 系统、Context Engine。今天把最后一块拼图补上,每一次 API 调用,OpenClaw 到底发了什么给 LLM?
这个问题的答案比我预期的复杂得多。
每次 OpenClaw 调用 LLM API,它发出去的不是一个简单的字符串。
它是一个由六层结构组装而成的完整请求。
L1: System Prompt (~8-15K tokens)
═══ CACHE BOUNDARY ═══
L2: Memory Addition (~2-5K tokens)
L3: Bootstrap Files (~3-10K tokens)
L4: Context Files (~5-15K tokens)
L5: Conversation History (~30-80K tokens)
L6: User Message (~0.5-5K tokens)每一层有自己的来源、自己的预算管理、自己的牺牲策略。加起来,一次完整的 API 调用大约消耗 50-130K tokens。
💡 即使是一个空对话(刚打开,还没说第一句话),固定开销就已经有 21K tokens,占总预算的 16%。这解释了为什么 OpenClaw 要在提示词中精打细算每一行文字。
像不像网络协议的 OSI 模型?
L1 System Prompt ≈ 物理层(最底层,定义基本能力)。L2 Memory ≈ 数据链路层(提供记忆上下文)。L3 Bootstrap ≈ 网络层(路由到正确的项目配置)。L4 Context ≈ 传输层(项目代码快照)。L5 Conversation ≈ 会话层(对话状态管理)。L6 User Message ≈ 应用层(用户意图)。
每一层都在上一层的基础上加 header,逐层封装。
🏗️ L3 Bootstrap Files 的五阶段过滤管线
L3 层的 Bootstrap Files 不是简单地「读取所有 .md 文件」。它经过了五个阶段的过滤。
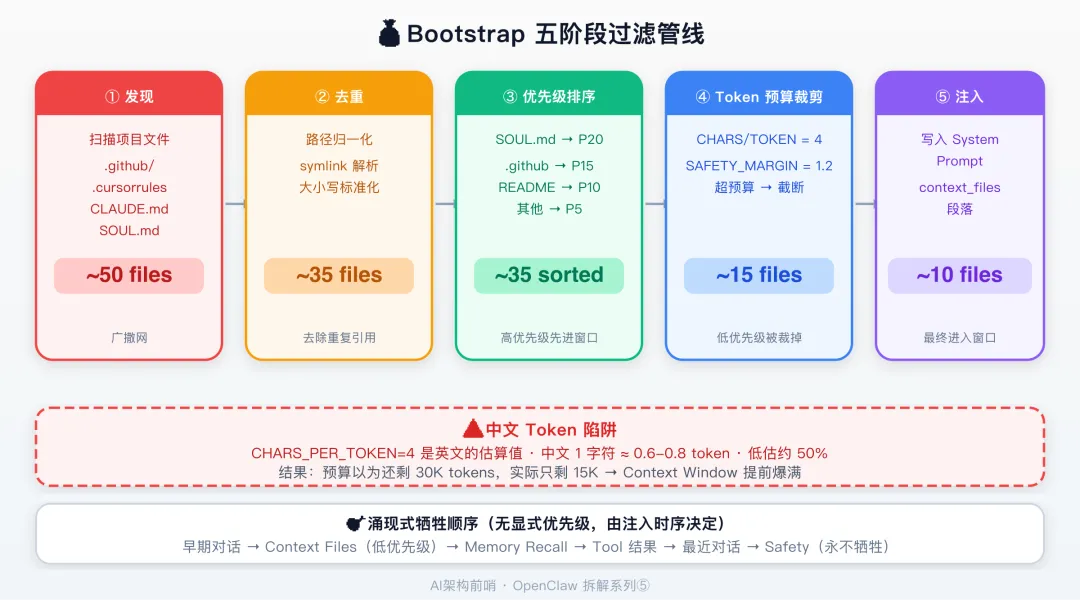
源码在 src/agents/bootstrap-files.ts L148-288。
workspace files → session filter → context mode → heartbeat filter → hook overrides → budget trim
全量 会话相关 full/lightweight 心跳排除 插件覆盖 字符预算
| 阶段 | 做了什么 |
|---|---|
| 1. Session Filter | 只保留当前会话相关文件 |
| 2. Context Mode | full 保留全部,lightweight 只保留核心 |
| 3. Heartbeat Exclusion | 心跳场景排除大文件 |
| 4. Hook Overrides | 插件可动态增删文件 |
| 5. Path Sanitize/Dedup | 路径去重+清洗 |
最后一关是字符预算裁剪。
buildBootstrapContextFiles() 执行 per-file 和 total 字符预算控制。超预算的文件被截断或直接跳过。预算花完了,后面的文件全部丢弃。
文件的加载顺序由优先级决定。SOUL.md 优先级 20 排最前面,最先被加载,也就最后被牺牲。identity.md(30)、tools.md(50) 这些优先级低的文件,预算紧张时先被丢弃。
💡 从网络 QoS 的视角看,前 4 阶段是定性过滤(ACL),最后 1 阶段是定量裁剪(带宽调度)。先按类型分类,再按权重分配资源。这和 Cisco 路由器的 QoS 管线是同一个结构。
⚔️ 牺牲顺序,涌现出来的退出序列
当 token 预算不够的时候,谁先被砍?
L5 对话历史 → L3 Bootstrap → L4 Context → L2 Memory → L1 System Prompt → L6 用户消息(永不牺牲)但这个顺序不是一个统一的「优先级调度器」控制的。
每一层都有自己独立的预算管理机制。L5 通过 compact() 主动压缩,是最频繁被牺牲的。L3 通过 buildBootstrapContextFiles() 的字符预算裁剪。L4 通过 analyzeBootstrapBudget() 的限制。L2 通过 buildMemoryPromptSection() 的截断。L1 通过 lightweight context mode 减少段落。L6 永远不被碰。
牺牲顺序是各层独立响应资源压力「涌现」出来的。
反直觉 没有一个地方写着「先牺牲 L5,再牺牲 L3」。这个顺序是各层阈值的副产品。L5 的阈值最宽松(token 数最多,最先触达上限),所以最先被触发压缩。L1 的阈值最严格(只有在 lightweight 模式下才减少),所以最后才被影响。
这像什么?
经济学的价格机制。没有中央计划者决定谁先被淘汰,而是每个参与者对资源压力做出独立响应,宏观上形成了有序的退出序列。价格(token 预算压力)上涨时,利润最薄的企业(L5 对话历史)最先退出市场,利润最厚的企业(L6 用户消息)最后才受影响。
🔧 Provider 注入点
Provider(比如 Anthropic、OpenAI)可以通过 promptContribution 在六层结构中插入自己的内容。
实际的组装结构(含 Provider 注入点)是这样的。
[Provider stablePrefix] ← Cache Boundary 之前
L1: System Prompt
└── 3 个可被 Override 的段
═══ CACHE BOUNDARY ═══
L2: Memory Addition
L3: Bootstrap Files
L4: Context Files
L5: Conversation History
L6: User Message
[Provider dynamicSuffix] ← 最末尾stablePrefix 在 Cache Boundary 之前,参与缓存。dynamicSuffix 在最末尾,不参与缓存。
一个意味着「我的定制化内容也能享受缓存加速」,另一个意味着「我的动态内容可以每轮变化而不影响缓存」。
看起来对称,但缓存行为完全不对称。
⚠️ Token 计数的中文陷阱
最后说一个让我有点不舒服但必须说的发现。
OpenClaw 的 token 计数不用 tiktoken 这种精确分词器。它用的是字符估算法。
CHARS_PER_TOKEN_ESTIMATE = 4 // 每 4 个字符 ≈ 1 个 token
SAFETY_MARGIN = 1.2 // 结果 × 1.2 留余量源码在 src/agents/pi-embedded-runner/tool-result-char-estimator.ts。
不同内容类型还有特殊权重。普通文本按 chars/4 计算。Tool results 有专门的调整(代码/JSON token 密度不同)。图片固定按 8000 字符计(≈ 2000 tokens)。
为什么不用 tiktoken?
三个原因。第一,性能。tiktoken 需要加载 tokenizer 模型,对每条消息做完整分词。第二,模型无关。OpenClaw 支持多个 Provider,每个 Provider 的 tokenizer 不同(BPE / SentencePiece / etc.),字符估算反而是最通用的方案。第三,足够准确。有 20% 安全边际兜底。
对英文来说,CHARS_PER_TOKEN = 4 是偏保守但基本准确的。英文实际约 3.5-4.5 chars/token。
但对中文呢?
中文 1 个字通常是 1-2 个 tokens,chars/token 大约 1.5-2。
OpenClaw 按 4 算,实际是 1.5-2。
低估了 50-60%。
后果是,中文用户的对话会比系统预期更快地逼近 token 上限,更频繁地触发 compaction。你可能聊了没几轮就发现 Agent 的「记忆力」变差了。
⚠️ 这不是 LLM 的问题,是 token 预算被低估导致的过早压缩。CHARS_PER_TOKEN = 4 是一个西文中心主义的假设。
这让我想到了 Unicode 的历史。UTF-8 中英文 1 字节,中文 3 字节。很多早期系统假设 1 字符 = 1 字节,导致中文处理一堆 bug。现在 Agent 框架在 token 层面犯了完全一样的错误。
我觉得这不是故意的。大概率是开发团队主要处理英文场景。但作为中文用户,这个差异带来的体验退化是实实在在的。
💡 修复建议也不复杂。要么加一个语言检测逻辑,CJK 字符用不同的系数(比如 1.8)。要么改用 Provider 提供的实际 token 计数 API。代价是增加一点延迟,但换来的是准确的预算管理。
📊 一张表总结 Token 经济学
| 层级 | 典型 Token 数 | 占比 | 牺牲顺序 |
|---|---|---|---|
| L1 System Prompt | 8-15K | ~15% | ⑤ 几乎不碰 |
| L2 Memory | 2-5K | ~5% | ④ |
| L3 Bootstrap | 3-10K | ~8% | ② |
| L4 Context | 5-15K | ~12% | ③ |
| L5 Conversation | 30-80K | ~55% | ① 最先牺牲 |
| L6 User Message | 0.5-5K | ~5% | 🔒 永不 |
| 总计 | 50-130K | 100% | — |
| 固定开销(空对话) | ~21K | ~16% | — |
五篇写完了。
从 Agent Loop 的三层嵌套,到 System Prompt 的 20 段组装,到 Memory 的三层金字塔,到 Context Engine 的接口设计,到 Prompt 的六层组装和 Token 经济学。
我从 OpenClaw 的源码里看到的不是一个 AI 应用。我看到的是一个正在形成的操作系统。
进程调度、内存管理、文件系统、缓存策略、安全模型、进程隔离……这些 OS 教科书里的概念,在 Agent 框架里一个一个重新出现,只不过换了名字。
Agent Loop ≈ 调度器。Memory ≈ 存储层级。ContextEngine ≈ MMU。Cache Boundary ≈ Cache Line。SOUL.md ≈ 用户配置文件。Profile 轮转 ≈ RAID。Failover 决策树 ≈ RestartPolicy。
如果你是做 Agent 开发的,去翻翻操作系统教科书。
不是为了考试。是为了少走弯路。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。