 夜雨聆风
夜雨聆风





Rust 重写的文档解析器:300 页 PDF 据说从 3 分钟到 3 秒,还纯本地
做 RAG、或者天天要从 PDF 里扒文字的人,大概都被文档解析坑过:慢、吃 CPU(风扇起飞)、有的还得把文件传到云端——合同、标书这种,传上去心里总不踏实。
最近 LlamaIndex 团队开源了个解析器 LiteParse,把这三个问题一次性解了:Rust 重写、纯本地运行、而且快得离谱。 有人在 issues 里晒,300 页的标书以前等 3 分钟,现在 3 秒出结果。GitHub 上已经冲到 近 8k Star,Apache-2.0 协议。
我去翻了下,这工具最聪明的地方不是「又写了个解析器」,而是把对的引擎用在了对的地方。
01 · 为什么能快这么多:挖出了藏在浏览器里的引擎
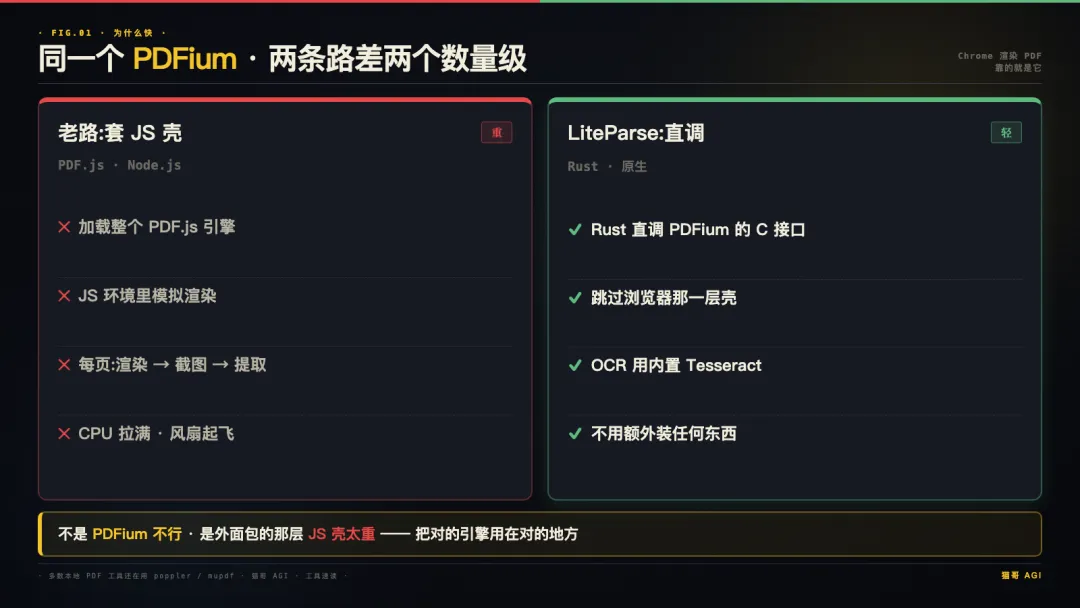
老版本是 JS/TS 写的,走 Node.js 那套,PDF 解析靠 PDF.js——说白了就是个浏览器里的 PDF 阅读器,被强行改造成了解析器。
问题就一个字:重。你得先加载整个 PDF.js 引擎,在 JS 环境里模拟渲染,每页都走一遍「渲染 → 截图 → 提取」。文件一大,CPU 直接拉满,风扇开始表演。
LiteParse 的做法彻底变了:用 Rust 直接调 PDFium——就是 Chrome 底层渲染 PDF 的那个引擎——直接走它的 C 接口提文本,跳过浏览器那一层壳。该用 OCR 时,用内置的 Tesseract,不用额外装任何东西。
这里有个挺有意思的点:Chrome 能那么快渲染 PDF,靠的就是 PDFium。但这么多年,绝大多数本地 PDF 工具还在用 poppler、mupdf,很少有人直接拿 PDFium 做二次开发。LiteParse 算是把这个「藏在浏览器里的神器」挖了出来。
同样一个 PDFium,在浏览器里跑、和用 Rust 直接调,差距能到两个数量级。 不是 PDFium 不行,是外面包的那层 JS 壳太重了。
02 · 怎么用:简单到离谱
四种装法,挑你顺手的:
装好之后,一句话解析:
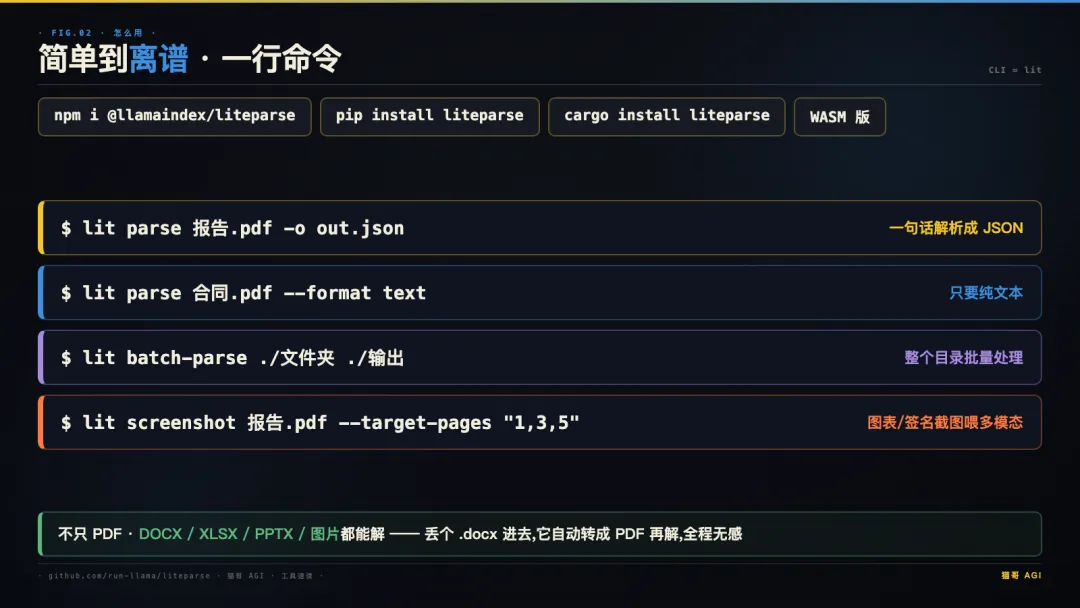
几个实用的姿势:
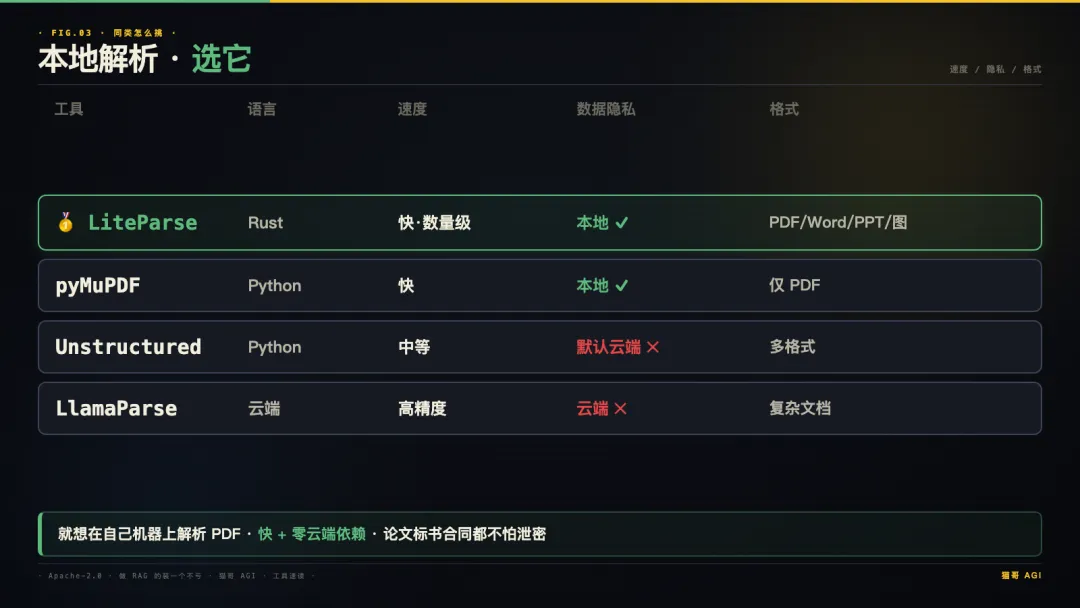
03 · 同类工具,怎么挑
谁该装
经常处理论文、合同、标书的开发者,以及做 RAG 应用要把文档喂给大模型的——这工具装一个不亏。本地跑、不上云,论文标书合同都不用担心泄密,速度还顶。
GitHub 地址:
最后说一句我的真实感受:LiteParse 真正值得学的,不是「Rust 就是快」这种结论,而是那个思路——别急着造新轮子,先看看有没有现成的好引擎,被错误的方式用着。 把 PDFium 从浏览器里挖出来直接调,就是个典型。一行命令的事,装了又不会少块肉,值得试试。