 夜雨聆风
夜雨聆风





LiteParse:快速轻量本地文档解析
开源工具
GitHub 一夜暴涨9000星:LiteParse 重新定义文档解析
你有没有过这种经历
给 AI 投喂一份 PDF 文档,等着它给出有价值的回答,结果模型完全漏掉了关键数据——表格里的数字对不上,段落里的数字对不上。你一看解析结果才发现,PDF 里的文字根本没提取完整,表格变成了乱码,图片里的内容更是完全丢失。
这不是模型的问题。问题的根源在于:大多数 PDF 解析工具,根本没有真正「读懂」文档的结构。文字提取是做到了,但空间位置、阅读顺序、多栏布局、表格结构——这些决定信息是否准确的结构信息,全部丢失了。
最近 GitHub 上出现了一个 Rust 写的文档解析工具,叫 LiteParse。发布不到四个月,Stars 突破 8000,一天之内新增超过 900 颗。它的核心理念很简单:快、轻、准,而且全部跑在本地。不做云端,不依赖大模型 API,把文档解析这件事做到极致。
01 功能:它能解析什么
LiteParse 支持的格式覆盖了日常办公中最常见的几类:PDF、DOCX、XLSX、PPTX、图片。无论是你从网上下载的论文报告,还是同事发来的 Excel 数据表,或者是截图里的表格内容,它都能统一处理。
它输出的不只是纯文本。你可以拿到 JSON 格式的结构化数据——包含文字内容和对应的边界框(bounding box)信息,也就是每个文字块在页面上的准确坐标。这意味着即使是一份复杂的双栏排版文档,LiteParse 也能还原出正确的阅读顺序,而不是把内容搅成一团。
还有一个很实用的功能——截图生成。它可以用指定的 DPI 把 PDF 页面渲染成高清图片,输出 PNG 文件,供你在工作流里直接使用,或者喂给多模态模型做进一步分析。
「LiteParse is a standalone OSS PDF parsing tool focused exclusively on fast and light parsing. Everything runs locally on your machine.」
—— LiteParse README
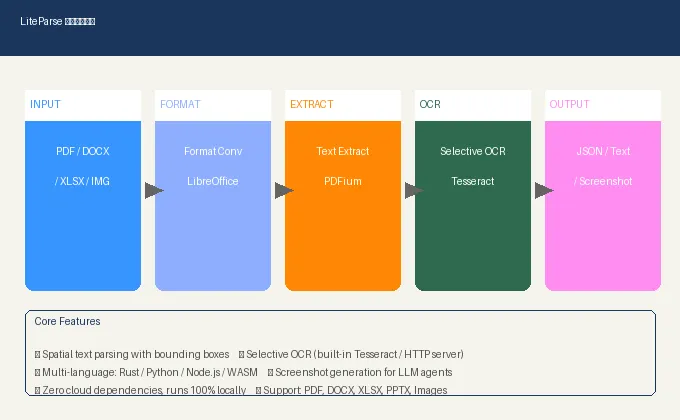
02 技术:它是怎么做到的
LiteParse 的核心由 Rust 实现,选择 Rust 的理由很充分:速度极快,内存安全,且适合编译成 WASM 在浏览器里跑。PDF 文字提取用的是 PDFium C 库——这是 Google Chrome 底层也在用的 PDF 渲染引擎,经过了大量实战验证。
最关键的一点是它的 选择性 OCR 机制。PDF 本身自带文字的页面,直接提取就行,不需要浪费算力做 OCR。只有当某一页是扫描件或图片嵌入时,LiteParse 才会调用 OCR 处理。而且 OCR 引擎是插件化的——内置 Tesseract(零配置,开箱即用),也可以接入任何支持标准 API 的 HTTP OCR 服务,比如 EasyOCR、PaddleOCR,或者你自己训练的模型。
整个处理流程是:格式转换 → 文字提取 → 选择性 OCR → 结果合并 → 网格投影重建阅读顺序。语言绑定方面,覆盖了 Rust、Python、Node.js/TypeScript、WASM(浏览器),用哪门语言都能无缝集成。
03 安装:快速上手
安装 LiteParse 非常简单,根据你使用的语言选一条命令即可:
# Rust
cargo install liteparse
# Python
pip install liteparse
# Node.js / TypeScript
npm i @llamaindex/liteparse
# Browser (WASM)
npm i @llamaindex/liteparse-wasm
OCR 功能默认开启,使用 Tesseract,默认语言为英文。配置项也很灵活——可以指定 DPI、目标页码范围、密码保护文档、输出格式(JSON 或纯文本)等。对于有特殊需求的用户,还可以通过实现 OcrEngine trait 来接入自定义 OCR 后端。
04 观察:为什么它值得注意
LlamaIndex 官方出了 LiteParse 做「Lite」版本,本身就是一个很强的信号。它的定位很明确:做轻量本地解析,对标 LlamaParse 云端版本。两者共享同一个技术规范,在不同的场景下互为补充——轻量场景用 LiteParse,需要处理复杂文档(密集表格、多栏布局、图表、扫描件)时用 LlamaParse。
本地运行 + 零云依赖是它最大的差异化优势。在数据隐私越来越受重视的今天,能把文档解析这件事完全放在本地跑,不用把敏感文件上传到第三方 API,意味着它可以直接集成到企业内部的知识管理系统里,这是很多竞品做不到的。
✅ 适合场景:RAG 系统文档预处理、知识库构建本地化、企业内部数据管道、低资源环境部署
❌ 不适合:复杂扫描件密集表格(建议用 LlamaParse 云端版)、超大型文档批量处理(需要分布式架构)
05 结尾
文档解析这件事,看起来基础,真正做好却很难。LiteParse 的价值在于,它把「快速准确提取结构化文档信息」这件事做到极致,用 Rust 的性能换速度,用模块化的 OCR 设计换灵活性,用纯本地的运行模式换数据安全。
如果你正在构建 RAG 系统,或者需要一个可靠的本地文档解析工具,LiteParse 值得你花十分钟跑一下 demo。如果你的文档里有大量复杂表格和扫描件,LlamaParse 是它的官方搭档。
它们的关系很简单:LiteParse 负责简单的,LlamaParse 负责复杂的。两件事分开做,各自做到最优。
最后说两句。
文档解析赛道正在变得热闹起来。LlamaIndex 这样的头部项目亲自下场做「轻量版」,本身就说明这个需求是真实的。不是每个人都需要云端的大模型来处理文档,也不是每个场景都值得为解析这一步付云服务的费用。本地化、确定性、可控的文档解析,正在成为 AI 应用栈里越来越重要的一层基础设施。
LiteParse 的 8000 星只是开始。
📌 数据来源:GitHub Trending,2026-05-31
GitHub:https://github.com/run-llama/liteparse
如果你觉得这个项目有意思,欢迎 Star 支持开源 🧬