夜雨聆风
夜雨聆风





OpenClaw 和 NVIDIA 这次合作,开源 67453 个技能扫描结果:Agent 安全不能只靠一个杀毒软件
大家好,我是 One。
OpenClaw 这两天发了一个挺重要的东西。
不是一个普通版本更新,也不是又接了一个模型。
它和 NVIDIA 合作,把 ClawHub 上 67,453 个公开技能的安全扫描结果,做成了一个数据集,开源到了 Hugging Face。
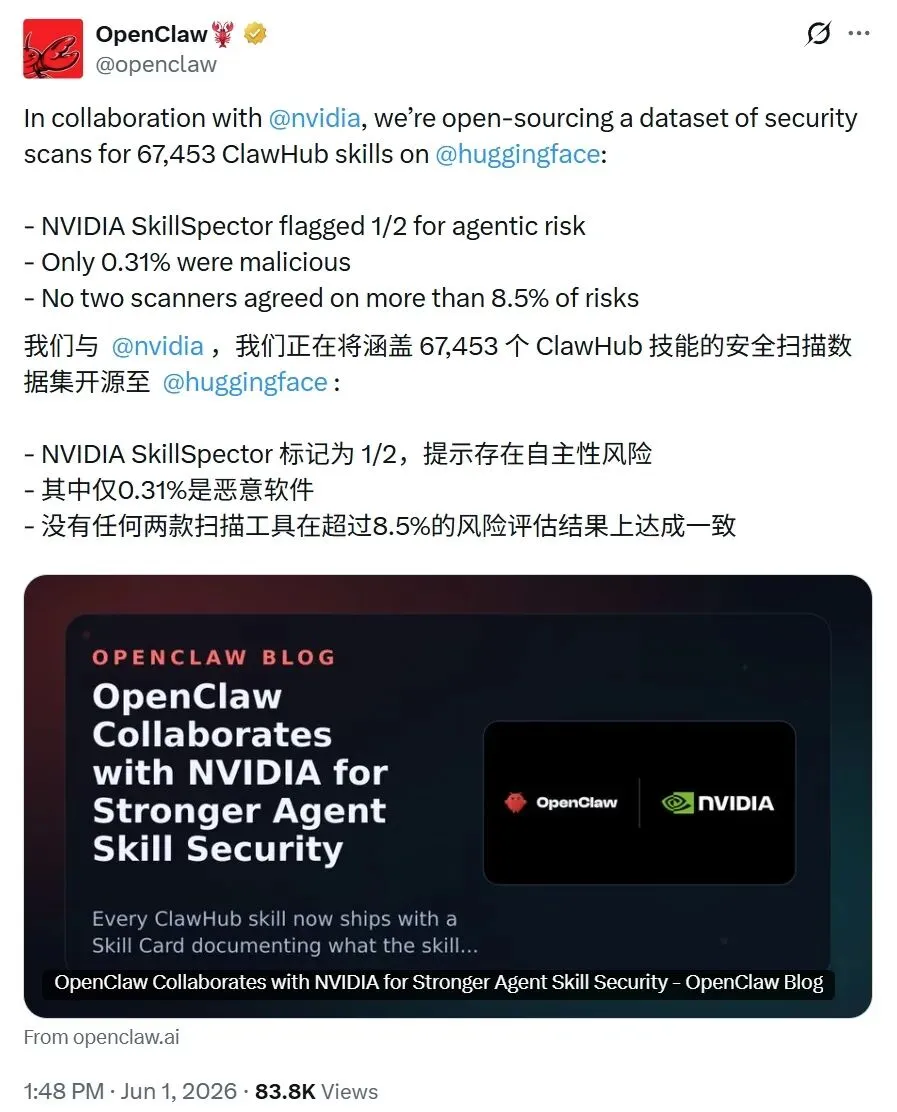
几个数字先放出来:
67,453 个 ClawHub skills。NVIDIA SkillSpector 大概标出了接近一半的 agentic risk。最终被 ClawScan 判成 malicious(恶意) 的只有 206 个,大约 0.3%。三类扫描器之间的重合度很低,最高也只是 10% 左右。
这个结果我觉得很有意思。
因为它基本上把 Agent 生态现在最麻烦的问题摆到台面上了:
很多技能不一定是“病毒”。但它可能有很大的权限。可能读不该读的文件。可能调用危险命令。可能在 prompt 里藏了额外指令。也可能只是写得很糟糕,边界不清楚,一旦被 Agent 执行,出事范围很难估。
传统软件安全里,我们习惯问一句话:
这个包有没有恶意代码?
到了 Agent 技能这里,问题变了。
你还得问:
它到底想让 Agent 做什么?它声明的能力和实际代码一致吗?它能碰到哪些工具、文件、环境变量和外部服务?如果 Agent 误信了它,最坏会发生什么?
这几个问题,单靠 VirusTotal 解决不了。
技能不是插件,它更像给 Agent 的一段行为指令
OpenClaw 官方博客里举了一个很直白的例子。
一个 skill 可以说自己是“帮你总结日志”。
但它打包的脚本,可能顺手把日志发到外部服务器。
这不一定长得像传统恶意软件。
它可能没有一个病毒特征。也没有明显的二进制木马。甚至代码本身看起来还挺正常。
但对 Agent 来说,这已经是风险了。
因为 Agent 不是普通的 UI 插件。
它会读上下文。会调用工具。会执行命令。会拿着你的授权去做事。
这也是为什么 OpenClaw 这次强调的是 multi-layered skill scanning。
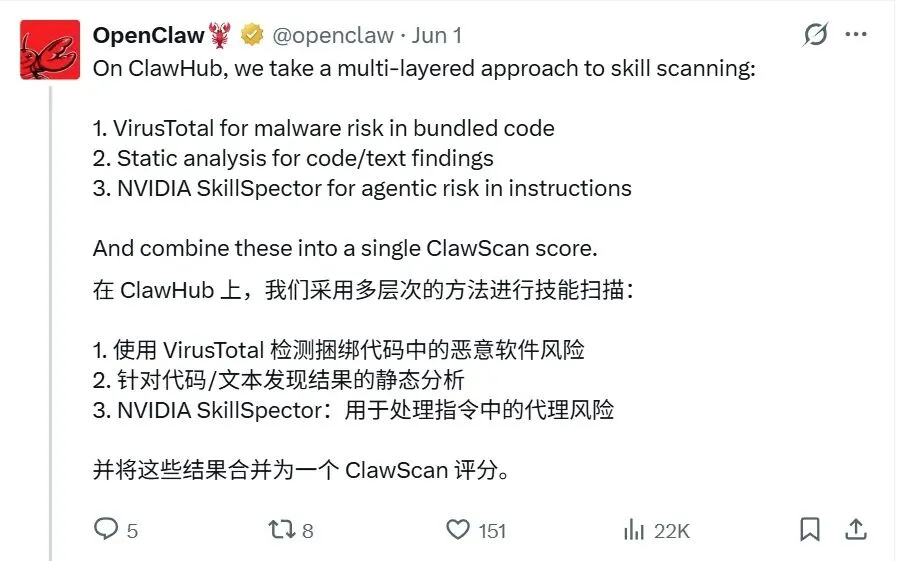
ClawHub 现在对技能做三层扫描。
第一层,用 VirusTotal 看打包代码里的恶意软件风险。
第二层,做静态分析,看代码和文本里有没有危险模式。
第三层,用 NVIDIA SkillSpector 看 agentic risk,也就是 Agent 指令里的隐藏风险、越权能力、工具投毒、数据外流、危险执行路径等问题。
最后这些信号会合到 ClawScan 里,给出一个总判断:
Clean。Suspicious。Malicious。
这个设计比较符合 Agent 产品的现实。
安全不是一个 yes/no 问题。
尤其在技能市场里,一个技能可能不是恶意的,但它的 blast radius 很大。
比如它能读很多文件,能操作 shell,能访问 token,能调用 MCP 工具。
这些能力在某些场景是合理的,但前提是它必须讲清楚,边界也要收住。
否则用户点一下安装,等于把一串看不见的权限交给 Agent。
最关键的发现:扫描器之间几乎不重合
这次数据集里最值得看的,不是“恶意技能只有 0.31%”。
这个数字当然重要。
但我更关注另一个结果:
三类扫描器看到的风险,重合度非常低。
OpenClaw 的数据卡里写得很清楚:
VirusTotal 正向标记 5,225 行,占 7.75%。静态分析正向标记 4,434 行,占 6.57%。SkillSpector 正向标记 32,856 行,占 48.71%。
再看重合:
只有 468 个技能同时被三类扫描器标记,占 0.69%。81.9% 的 positive findings 只来自单一扫描器。任意两个扫描器的 Jaccard overlap 都没有超过 0.104。
说人话就是:
它们看到的不是同一种风险。
VirusTotal 更像看“有没有已知恶意软件”。静态分析更像看“代码里有没有危险写法”。SkillSpector 更像看“这个 skill 会不会让 Agent 做越界的事”。
这三类问题都叫安全,但不是同一个层面。
所以如果一个技能 VirusTotal 是 clean,不代表它对 Agent 就安全。
如果 SkillSpector 标了 risk,也不代表它就是恶意软件。
如果静态分析发现危险执行,也要结合它的用途和权限边界一起看。
这也是 Agent skill 安全最麻烦的地方。
它不是纯代码审计。也不是纯内容审核。它介于代码、指令、权限、工具调用和用户信任之间。
Skill Card 可能会变成技能市场的基础设施
OpenClaw 这次还引入了 NVIDIA Skill Cards。
每个发布到 ClawHub 的 skill,现在都会带一张 Skill Card。
这张卡不是发布者自己写一句“我很安全”。
它会记录:
谁发布了这个技能。技能声明自己能做什么。ClawScan 扫到了什么。它来自哪里。最终判断是 clean、suspicious,还是 malicious。
用户可以在技能详情页看,也可以用命令看:
openclaw skills verify <slug> --card我觉得这个方向是对的。
Agent 生态要往前走,不能只靠用户自己赌。
以前装一个 npm 包,很多人已经是闭眼装了。
到了 Agent skill 这里,如果还闭眼装,风险会更大。
因为 npm 包大多数时候只是代码依赖。
Agent skill 往往会改变 Agent 的行为。
它可能让 Agent 学会一个新工具。也可能让 Agent 接触一个新数据源。还可能让 Agent 在某个场景里默认相信一套流程。
所以技能市场未来一定需要类似“营养成分表”的东西。
不是只给用户一个星标数、下载数、README。
而是告诉用户:
这个技能吃什么权限。会碰什么文件。会调用什么工具。扫描器各自怎么看。如果出问题,影响范围在哪里。
Skill Card 做的就是这件事。
这个数据集对开发者也有用
OpenClaw 这次不是只发了一篇博客。
它把完整数据集放到了 Hugging Face:
OpenClaw/clawhub-security-signals。
数据集是 MIT license,包含 67,453 个公开 ClawHub skill 版本。
里面有几个关键信息:
clawscan_verdict:最终 ClawScan 判断。static_status:静态分析结果。virustotal_status:VirusTotal 结果。skillspector_status:SkillSpector 结果。skillspector_issue_categories:SkillSpector 风险类别。clawscan_summary:ClawScan 摘要。skill_md_content:经过脱敏的技能说明内容。skill_bundle_content:经过脱敏的打包文件内容。
如果你想自己分析,可以这样加载:
from datasets import load_datasetdataset = load_dataset("OpenClaw/clawhub-security-signals", name="default",)train = dataset["train"]print(train[0]["skill_slug"], train[0]["clawscan_verdict"])这个数据集的价值不是让大家拿来做“谁是坏人”的榜单。
OpenClaw 也说得很清楚:
scanner positives 是 evidence,不是 ground truth。SkillSpector 的 findings 是 advisory,不是指控。suspicious 的意思是 review before trusting,不是 malicious。
这点很重要。
Agent 安全里,很多东西不是非黑即白。
一个自动化部署 skill,如果能执行 shell,本身就有危险能力。
但如果它边界清楚、来源可信、指令明确,它可以是合理的。
反过来,一个看起来很温和的总结 skill,如果暗地里读 token、读日志、发外部请求,那才麻烦。
所以这个数据集更适合做研究、做评估、做 scanner 训练、做风险分类,而不是拿来简单拉黑。
对普通用户,先养成一个习惯
如果你只是 OpenClaw 或 ClawHub 的普通用户,我觉得这次更新可以转化成一个很简单的习惯:
以后装 skill,不要只看名字和描述。
至少看三件事。
第一,看 Skill Card。
它不是装饰品。
它会告诉你这个技能的来源、能力声明、扫描结果和 ClawScan 判断。
第二,看它要碰什么东西。
只读公开网页,和读取本地文件、执行 shell、访问环境变量,不是一个风险级别。
第三,看 suspicious 的原因。
suspicious 不等于不能用。
但它意味着你不能无脑用。
尤其是那些能操作生产环境、能读密钥、能调用外部 API、能改文件的 skill,一定要多看一眼。
Agent 越强,默认信任越危险。
这句话听起来有点老生常谈,但到了技能市场这里,它会变成很具体的问题。
你今天装的不是一个“小功能”。
你装的是一段会影响 Agent 行为的外部指令。
NVIDIA 这条线也值得继续看
这次合作还有一个背景。
OpenClaw 之前就和 NVIDIA 在 NemoClaw、OpenShell、Windows 原生支持这些方向有合作。
这次又把 NVIDIA SkillSpector 和 Skill Cards 接进 ClawHub。
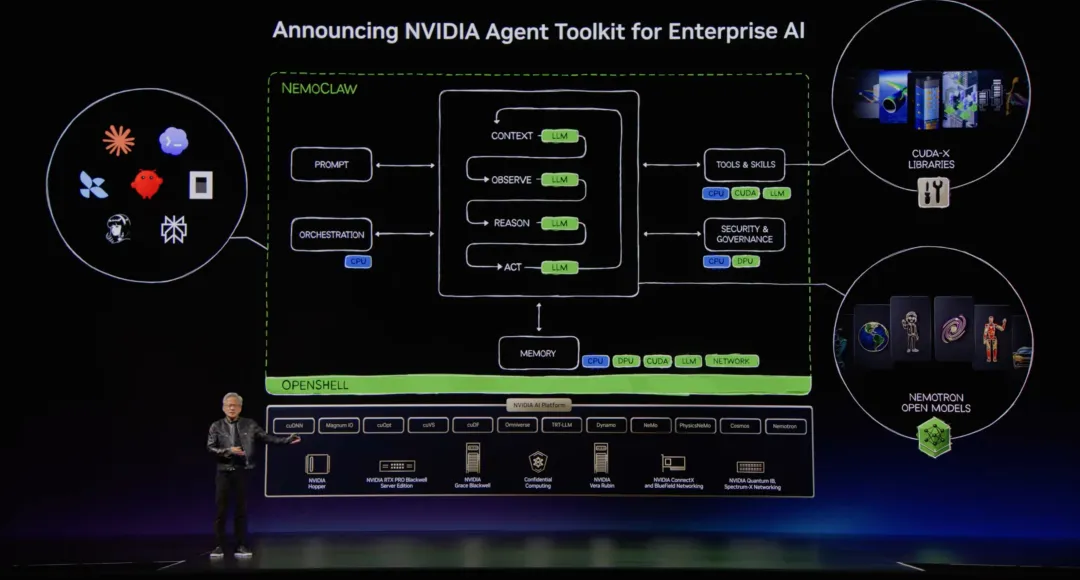
从 NVIDIA 的角度看,这不只是“帮一个开源项目做扫描”。
如果企业要真的跑 Agent,安全、治理、可审计这些东西绕不开。
模型很强是一回事。
Agent 能不能安全地接工具、接数据、接企业流程,是另一回事。
尤其现在大家都在讲 enterprise AI agent。
企业不会只问“它聪不聪明”。
企业会问:
它为什么调用这个工具?谁给它的权限?它读了什么数据?它执行了什么命令?这个技能是谁发布的?出问题以后能不能追溯?
OpenClaw 这次做 Skill Card 和公开扫描数据,其实是在补 Agent 生态的信任层。
这个活不花哨,但很基础。
没有这层,技能市场越大,风险越大。
我更愿意把它看成一次基础设施升级
很多 AI 产品更新喜欢讲能力:
更强模型。更多工具。更多自动化。更深集成。
这些当然重要。
但 Agent 生态真要变成日常生产力,光堆能力是不够的。
你还要解决几个很土的问题:
我敢不敢装?我怎么知道它有没有越权?我怎么判断扫描器的结果?我出了问题能不能追溯?我能不能把风险解释给团队里其他人?
OpenClaw 和 NVIDIA 这次做的事,就是把这些问题往前推了一步。
不是说现在就完美了。
恰恰相反,这次数据里最清楚的结论是:单一扫描器根本不够。
VirusTotal、静态分析、SkillSpector 都有盲区。
ClawScan 也不是人工终审,只是 registry 的自动化运营判断。
数据集本身也是 silver-standard,不是最终真理。
但把 67,453 条真实扫描信号公开出来,这件事本身很有价值。
它让大家终于可以基于同一批数据讨论:
什么是 agentic risk。什么是 malicious。什么情况只是 suspicious。不同扫描器到底在看什么。一个技能市场应该怎么建立信任。
Agent 时代,安全不会只发生在模型层。
它会发生在 skill、plugin、MCP、shell、文件系统、凭证、消息入口、定时任务这些地方。
这些地方都很碎。
但 Agent 真正干活的时候,风险也正是从这些碎片里出来的。
所以这次 OpenClaw + NVIDIA 的合作,我觉得不是一个普通 PR 新闻。
它更像是给 Agent 技能生态打了一个地基:
以后别再只问“这个技能有没有病毒”。
还要问:
它会让 Agent 做什么?它有没有说清楚?它的权限是不是过大?它的风险有没有被记录?我能不能在安装前看到一张可信的 Skill Card?
这才是 Agent 技能市场要长大的样子。
以上,
—
如果你想通过创业而不是打工赚到100万
如果你想通过创业而不是工作赚到100万, 你需要信息,认知,技能和圈子, 而毫无疑问,生财有术社群是以上最具性价比的解决方案, 没有之一,
有点小贵,没关系, 可以白嫖三天——
通过我下方的邀请码直接加入生财有术,3天内可以自助申请退全款。 你不妨抱着白嫖的心态进去找找创业/副业信息,再看完我在社区里所有的帖子,判断它是否适合你,如果觉得不适合,可直接申请退款,秒到账,毫无压力。