 夜雨聆风
夜雨聆风





〖OpenClaw系列〗模型配置完整指南
前文回顾
前面(推荐阅读 〖OpenClaw系列〗配置文件 openclaw.json 详解)我们完成了OpenClaw的神经中枢配置。你现在已经知道 agents.defaults.model 里填 "anthropic/claude-sonnet-4-6" 就能让AI跑起来,填 "openai/gpt-5.2" 就能换个模型。
但如果你停下来想:这个模型ID的完整列表在哪?API Key怎么安全存?temperature是干啥的? 这些问题,就是本文要解决的。
本文定位:聚焦”模型”这一具体能力的深度配置,与第3篇的
agents视角形成互补。
先上全景:模型配置的三层结构
一眼看清OpenClaw的模型配置架构:
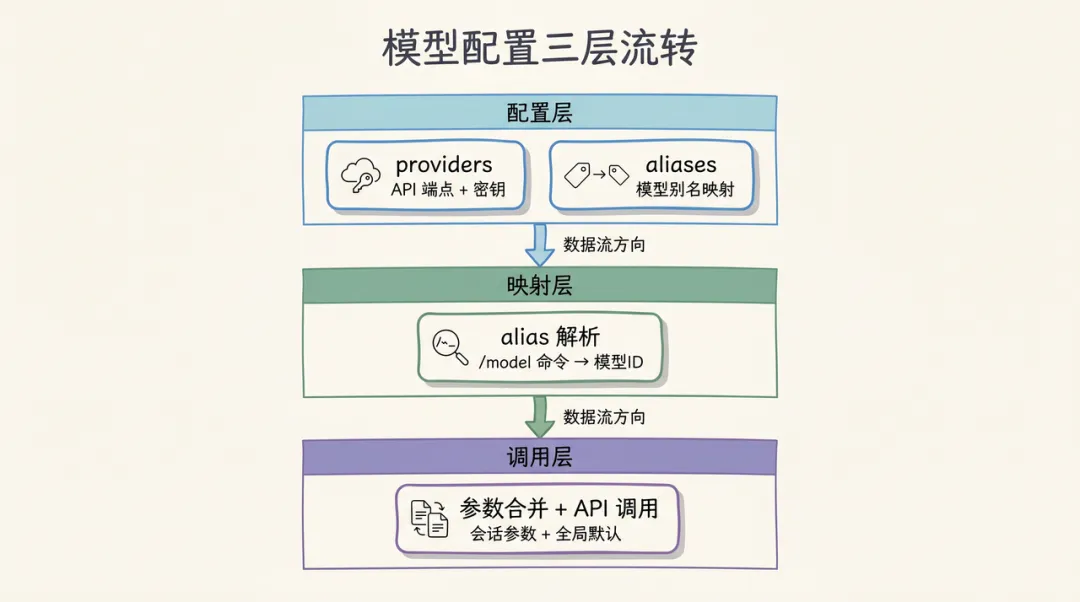
这张图展示了模型配置的完整数据流:
-
第一层(蓝色): models.providers定义所有可用的模型提供商(Anthropic、OpenAI等),包括API端点和默认参数 -
第二层(绿色): models.{id}.alias定义模型别名,让/model命令可以快速切换 -
第三层(紫色):Gateway运行时合并会话参数、全局默认值,最终发起API调用
下面的文章沿着这三层结构展开,每讲一层,你都可以回来看图中对应的彩色区域。
模型配置在系统中的位置
把视角拉远,看看模型配置在 OpenClaw 整体架构中的位置:
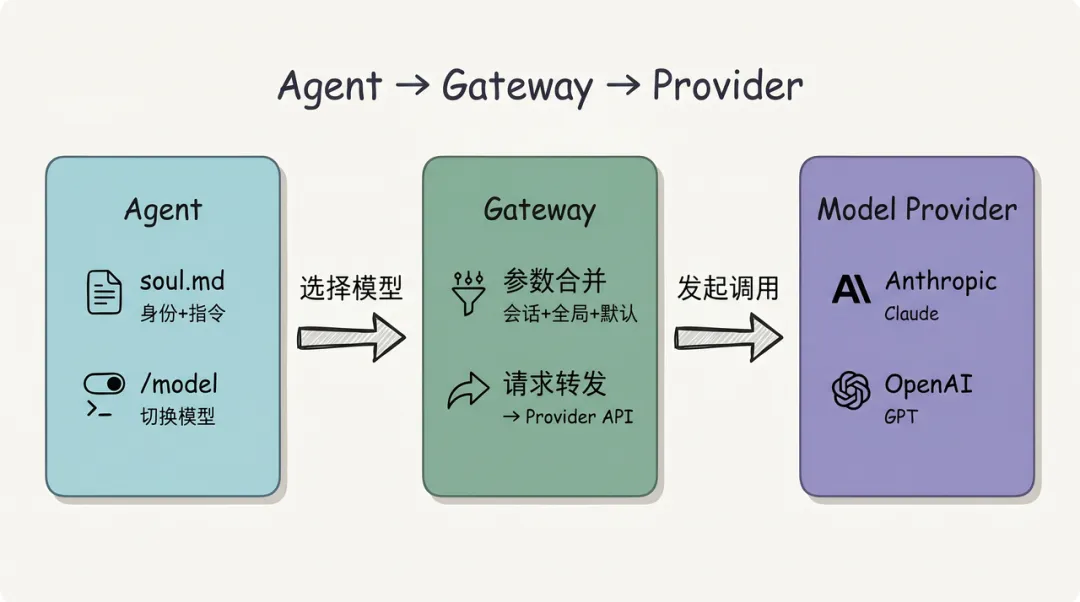
模型配置不是孤立的——它处在 Agent → Gateway → Model Provider 这条调用链的中枢:Agent 决定”用哪个模型”,Gateway 负责”参数合并与请求转发”,Provider 才是真正的”模型API”。理解这张全局图,后面三层配置就只是这条链路上的不同环节而已。
第一层:模型提供商配置
术语说明:
provider(提供商)指提供大语言模型API服务的厂商,如Anthropic、OpenAI、Groq等。每个provider可以包含多个模型(model)。OpenClaw通过models.providers配置块定义如何连接这些服务。
主流提供商对照表
OpenClaw内置支持多家模型提供商,配置结构基本一致:
|
|
|
|
|
|---|---|---|---|
| Anthropic | anthropic/ |
|
|
| OpenAI | openai/ |
|
|
| Groq | groq/ |
|
|
| Together | together/ |
|
|
| Ollama | ollama/ |
|
|
Anthropic配置详解(生产环境推荐)
Anthropic的Claude系列是目前OpenClaw推荐的主力模型,配置最完整:
{
models: {
providers: {
anthropic: {
// API Key配置:从环境变量读取
apiKey: {
source: "env",
id: "ANTHROPIC_API_KEY",
},
// 可选:自定义API端点(企业代理或转发服务)
baseUrl: "https://api.anthropic.com/v1",
// 默认请求参数:所有Anthropic模型共用
defaultOptions: {
maxTokens: 4096,
temperature: 0.7,
// 额外Anthropic特有参数
topP: 0.9,
topK: 40,
},
},
},
},
}
配置项说明:
|
|
|
|
|---|---|---|
apiKey |
|
env方式从环境变量读取 |
baseUrl |
|
https://api.anthropic.com/v1,企业内网可自定义 |
defaultOptions.maxTokens |
|
|
defaultOptions.temperature |
|
|
OpenAI配置详解
OpenAI的配置结构与Anthropic几乎一致:
{
models: {
providers: {
openai: {
apiKey: {
source: "env",
id: "OPENAI_API_KEY",
},
// 可选:多租户组织ID
organization: "org-xxx",
defaultOptions: {
maxTokens: 4096,
temperature: 0.7,
// OpenAI特有:函数调用模式
responseFormat: "text",
},
},
},
},
}
注意:OpenAI的模型ID格式与Anthropic略有不同。完整的模型ID是 openai/gpt-5.2,而Anthropic是 anthropic/claude-sonnet-4-6。
其他提供商简要配置
Groq和Together等提供商配置更简洁:
{
models: {
providers: {
groq: {
apiKey: { source: "env", id: "GROQ_API_KEY" },
// Groq默认端点固定,通常无需配置baseUrl
},
together: {
apiKey: { source: "env", id: "TOGETHER_API_KEY" },
},
},
},
}
术语说明:
provider(提供商)指模型API的服务方(Anthropic、OpenAI等),一个provider可以包含多个model(模型)。OpenClaw的provider配置块定义了如何连接该提供商的统一参数。
第二层:API Key的安全管理
绝对不要把API Key明文写在 openclaw.json 里。OpenClaw提供三种安全方式:
三种方式对比
|
|
|
|
|
|---|---|---|---|
| 环境变量 |
|
|
|
| SecretRef灵活配置 |
|
|
|
| .env文件 |
|
|
|
把这三种方式按”安全等级”立体地排一遍,更容易记住差异:
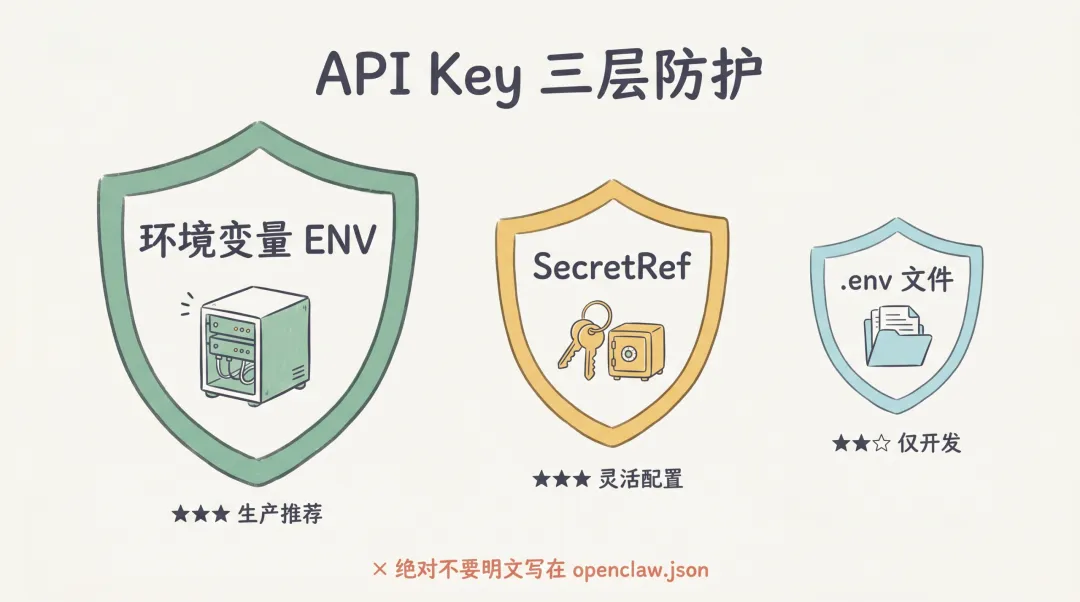
三层防护从左到右安全等级递减:环境变量适合生产、SecretRef适合多密钥灵活管理、**.env 文件**仅限本地开发。无论哪种方式,绝对不要明文写在 openclaw.json 里。
方式1:环境变量(最推荐)
在启动Gateway的shell中设置环境变量:
export ANTHROPIC_API_KEY="sk-ant-api03-..."
export OPENAI_API_KEY="sk-..."
openclaw gateway start
配置文件中引用:
{
models: {
providers: {
anthropic: {
apiKey: {
source: "env",
id: "ANTHROPIC_API_KEY", // 对应环境变量名
},
},
},
},
}
优势:Key不落地磁盘,进程结束后环境变量消失,适合服务器部署。
方式2:SecretRef灵活配置
需要更复杂的密钥管理(如从密钥管理服务读取):
{
models: {
providers: {
anthropic: {
apiKey: {
// 支持 env | file | exec
source: "file",
id: "/run/secrets/anthropic_key", // 从文件读取
},
},
},
},
}
source类型说明:
-
env:从环境变量读取 -
file:从指定路径文件读取(适合Docker secrets) -
exec:执行命令获取(如aws secretsmanager get-secret)
方式3:.env文件(开发环境)
在项目根目录创建 .env 文件:
ANTHROPIC_API_KEY=sk-ant-api03-...
OPENAI_API_KEY=sk-...
OpenClaw启动时会自动加载当前目录和 ~/.openclaw/ 下的 .env 文件。注意:.env 不应该提交到Git仓库,务必添加到 .gitignore。
安全提示:生产环境永远不要使用
.env文件存储密钥,始终使用环境变量或专门的密钥管理系统。
第三层:模型参数调优
理解了配置层,再看运行时如何精细控制模型行为。
核心参数详解
以下是影响模型输出质量的关键参数,都在 defaultOptions 或会话级配置中:
|
|
|
|
|
|
|---|---|---|---|---|
| temperature |
|
|
|
|
| maxTokens |
|
|
|
|
| topP |
|
|
|
|
| topK |
|
|
|
|
| stopSequences |
|
|
|
|
| presencePenalty |
|
|
|
|
| frequencyPenalty |
|
|
|
|
temperature:创造力 vs 确定性
temperature 是最常用的调参项:
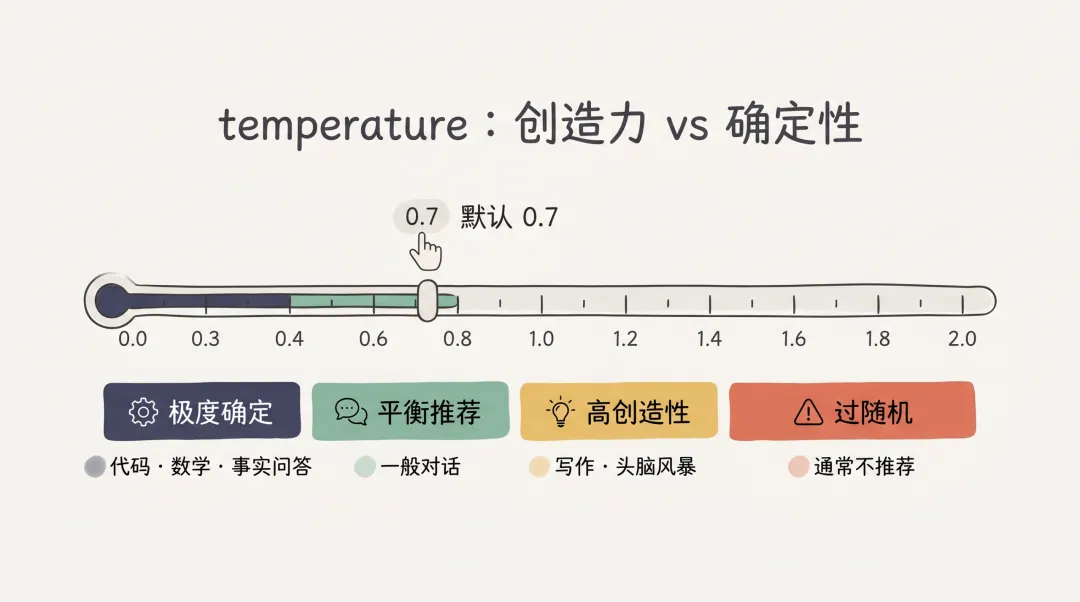
把 temperature 想象成一根滑杆,滑到不同位置意味着不同的”输出气质”:
-
0.0 – 0.3:极度确定,适合代码生成、数学计算、事实问答 -
0.4 – 0.7:平衡,默认推荐,适合一般对话 -
0.8 – 1.2:高创造性,适合写作、头脑风暴 -
**1.3+**:随机性过高,通常不推荐
配置示例:为不同任务配置不同参数:
{
agents: {
defaults: {
model: {
primary: "anthropic/claude-sonnet-4-6",
// 会话级覆盖defaultOptions
options: {
temperature: 0.3, // 更确定的回答
maxTokens: 2048,
},
},
},
},
}
maxTokens:输出长度控制
坑点预警:maxTokens 限制的是输出长度,不是输入+输出总长度。
Claude 3.5 Sonnet的上下文窗口是200K tokens,但单次输出最多4096 tokens。如果你需要很长的回答(如写代码、写文档),务必检查maxTokens是否足够。
// 长文档生成的配置
{
agents: {
writer: {
model: {
primary: "anthropic/claude-sonnet-4-6",
options: {
maxTokens: 4096, // 拉满
temperature: 0.7,
},
},
},
},
}
不同场景的参数组合推荐
|
|
|
|
|
|---|---|---|---|
| 代码生成 |
|
|
|
| 代码审查 |
|
|
|
| 技术问答 |
|
|
|
| 创意写作 |
|
|
|
| 数据分析 |
|
|
|
| 闲聊对话 |
|
|
|
上表浓缩成一张可贴墙的速查卡:
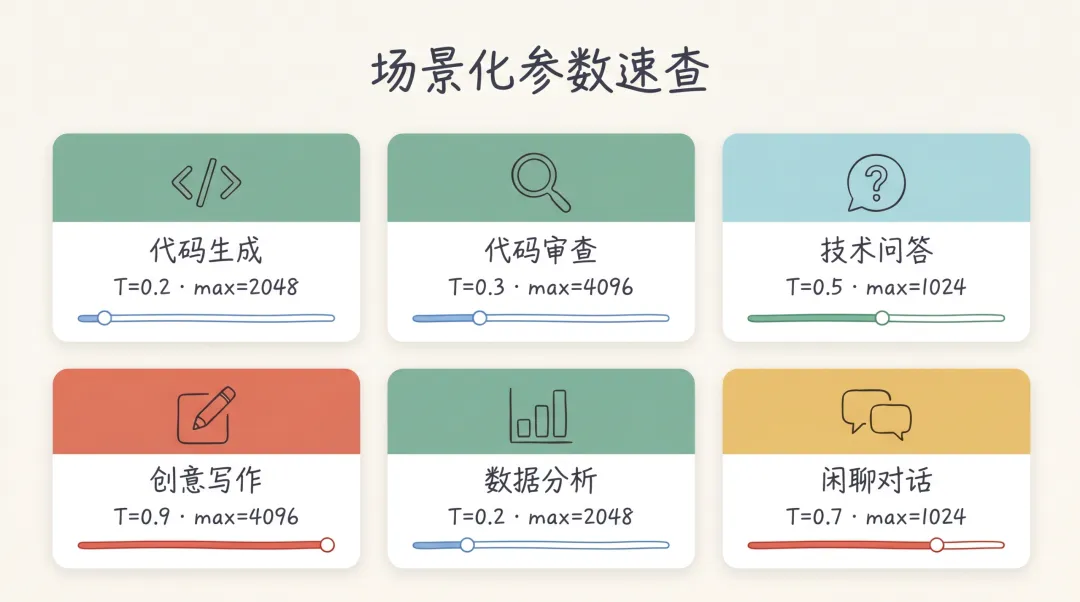
这张速查卡可以直接贴在显示器旁边。一个经验法则:需要精确性的任务温度调低(代码、数学、分析),需要发散性的任务温度调高(写作、头脑风暴),日常对话保持默认 0.7 即可。
第四层:模型别名与切换
配置好provider后,你得到的是完整模型ID,如 anthropic/claude-sonnet-4-6。这个ID太长,不适合日常使用。
定义别名
在 models 块中为模型定义短别名:
{
models: {
// 别名单独定义,与provider同级
"anthropic/claude-sonnet-4-6": {
alias: "Sonnet",
},
"anthropic/claude-opus-4-7": {
alias: "Opus",
},
"openai/gpt-5.2": {
alias: "GPT",
},
"groq/llama-3.1-70b": {
alias: "Llama",
},
},
}
这条配置背后的映射关系,画出来是这样:
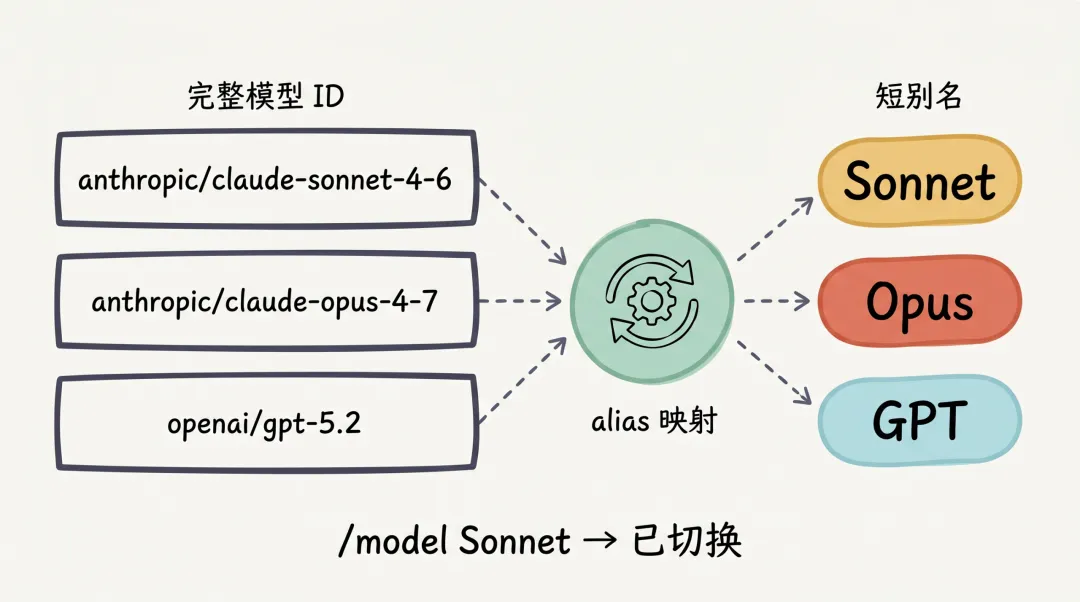
如图所示,左侧的”完整模型 ID”(如 anthropic/claude-sonnet-4-6)通过中心的 alias 映射,被简化为右侧的短别名(Sonnet/Opus/GPT),既方便在配置中引用,也方便 /model 命令切换。
术语说明:
alias(别名)是对长模型ID的短名称映射。定义后,你可以在agents.defaults.model.primary中使用别名,也可以用/model命令在运行时切换。
别名使用场景
定义别名后,多处配置变得更简洁:
{
agents: {
// 场景1:默认Agent用Sonnet
defaults: {
model: { primary: "Sonnet" }, // 不是完整的anthropic/claude-...
},
// 场景2:代码Agent用Opus
coder: {
model: { primary: "Opus" },
},
// 场景3:测试用Llama
tester: {
model: { primary: "Llama" },
},
},
}
运行时切换模型
在对话中,你可以用 /model 命令临时切换模型:
用户: /model Opus
AI: 已切换到模型:Opus (anthropic/claude-opus-4-7)
用户: /model Sonnet
AI: 已切换到模型:Sonnet (anthropic/claude-sonnet-4-6)
切换范围:
-
默认情况下, /model只影响当前会话 -
如果要全局切换,需要配置 agents.defaults.model.primary
未定义别名的模型:可以使用完整ID切换,但 /model 不会提示:
用户: /model anthropic/claude-haiku-3-5
AI: 已切换到模型:anthropic/claude-haiku-3-5
但这不会显示友好的别名,建议常用模型都定义alias。
踩坑
坑1:模型名称拼写错误
现象:Gateway启动时一切正常,但发起对话时报错 Model not found 或 404。
原因:模型ID拼写错误,如 anthropic/claude-sonet-4-6(少了n)。
解决:
-
核对官方模型ID。Anthropic的完整列表在 https://docs.anthropic.com/claude/docs/models-overview -
使用 openclaw doctor检查配置 -
常用模型定义alias,减少拼写错误可能
坑2:API Key权限不足
现象:调用报 401 Unauthorized 或 insufficient_quota。
可能原因:
-
Key 已被删除或过期 -
Key 的权限未包含该模型(如Opus需要特殊权限) -
账户余额不足
排查步骤:
# 测试Key是否有效
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{"model":"claude-sonnet-4-6","max_tokens":100,"messages":[{"role":"user","content":"hi"}]}'
坑3:maxTokens设置过小导致回答截断
现象:AI回答到一半突然中断,末尾有 ... 或被截断。
原因:maxTokens 设置小于模型实际需要的输出长度。
解决:
-
检查被截断的回答长度 -
估算需要的token数(英文约4字符/token,中文约2字符/token) -
提高该场景的 maxTokens配置
坑4:temperature太低导致回答死板
现象:AI回答千篇一律,缺乏灵活性,即使问的是开放性问题。
原因:temperature 设置为 0 或接近 0。
解决:根据场景调整。聊天对话用 0.7,创意任务用 0.9+。
坑5:多个provider配置了相同的模型ID
现象:配置了两个provider,但模型调用总是走其中一个,另一个不生效。
原因:模型ID冲突,如两个provider都配置了 "gpt-5.2"。
解决:使用带前缀的完整ID:"anthropic/claude-sonnet-4-6" 和 "openai/gpt-5.2"。全局唯一的模型ID更安全。
常见问题(FAQ)
Q:如何测试模型连接是否正常?
A:使用 openclaw doctor 命令,它会检测所有配置的provider连接状态:
openclaw doctor --models
或直接发一条测试消息:
openclaw message "Hello" --model Sonnet
Q:可以在不重启Gateway的情况下切换模型吗?
A:可以。/model 命令在运行时切换,只影响当前会话。如果要修改默认模型,改配置后热重载生效(无需重启)。
Q:本地模型(Ollama)如何配置?
A:本文不讲,这是[第13篇:接入本地模型:Ollama/LM Studio](./第13篇-接入本地模型:Ollama-LM Studio.md)的主题。简单说就是 providers.ollama 配置本地端点。
Q:一个Gateway可以同时配多个Anthropic Key吗?
A:不能直接配多个Key,但可以通过配置多个 agents 分别使用不同的 env 变量名来间接实现。更推荐用Key池或代理服务。
Q:模型参数(temperature等)可以在对话中临时改吗?
A:OpenClaw CLI 不支持会话级参数覆盖,需要修改配置后热重载。如果你需要频繁调整参数,建议配置多个Agent,每个Agent用不同的参数预设。
总结:OpenClaw模型配置核心要点
回顾今天的三层架构图:
-
配置层(蓝色): models.providers定义如何连接Anthropic/OpenAI等提供商,核心是API Key和默认参数 -
映射层(绿色): models.{id}.alias定义短别名,让配置和切换更便捷 -
调用层(紫色):Gateway运行时合并参数,发起实际API调用
关键配置清单:
|
|
|
|
|---|---|---|
|
|
models.providers |
apiKey
baseUrl |
|
|
defaultOptions
|
temperature |
|
|
defaultOptions
|
maxTokens |
|
|
models.{id}.alias |
alias |
|
|
|
/model
|
安全底线:API Key绝不明文写入配置文件,优先使用环境变量。
下一篇预告
〖OpenClaw系列〗模型故障切换与多模型策略
当Anthropic服务挂了怎么办?当Grok价格太贵怎么办?下一篇我们配置 fallbacks 故障切换链,以及多模型协同的策略模式。
本文是系列第11篇,前序文章:〖OpenClaw系列〗配置文件 openclaw.json 详解
📌 觉得有用?点个「在看」 👇 👨💻 关注「敏叔侃技术」,每周更新 OpenClaw 实战干货 ⭐ 收藏这篇文章,配置模型时翻出来对照结构图修改