夜雨聆风
夜雨聆风做生物信息,不可避免一定要下载数据,例如下载基因组参考序列,原始测序数据,各种基因注释信息。总之,你肯定要用到下载数据。下载生物数据是生物信息基本技能,但是常常因为各种原因导致无法下载,从本次内容开始,我们将系统的给大家介绍生物数据下载的各种方法。
利用迅雷提高下载速度
迅雷有些时候可以极大提高下载速度,来做几个演示。我想要下载这个44G的数据,比较大也比较慢,于是就使用迅雷直接下载。
https://www.10xgenomics.com/resources/datasets/10k-human-pbmcs-3-ht-v3-1-chromium-x-3-1-high
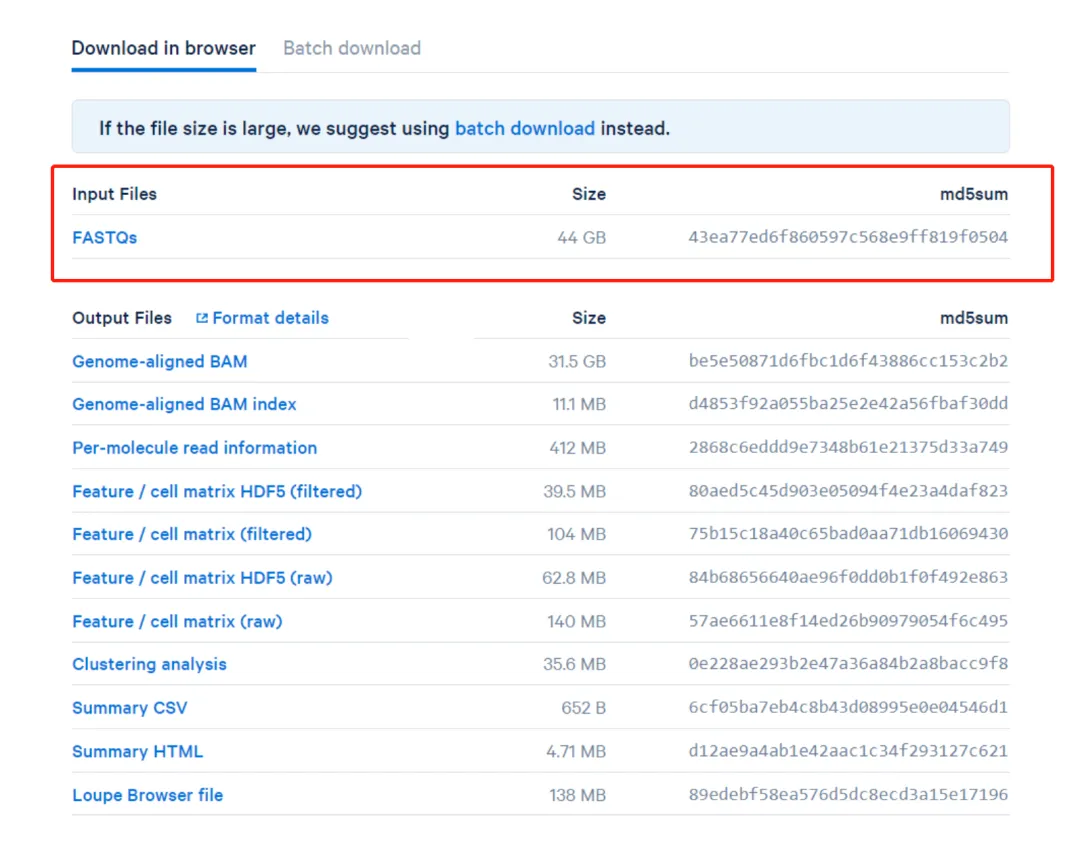
鼠标右键复制链接地址,打开迅雷开始下载。这个地址在亚马逊云,在美国西区,数据做成了一个S3类型存储。这种数据这么放着都得花钱,不过10x大公司,不差这点钱。
https://s3-us-west-2.amazonaws.com/10x.files/samples/cell-exp/6.1.0/10k_PBMC_3p_nextgem_Chromium_X/10k_PBMC_3p_nextgem_Chromium_X_fastqs.tar创建任务,准备下载。
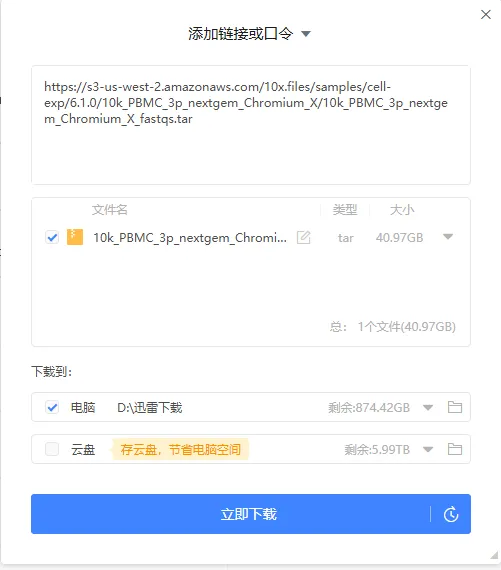
由于我是尊贵的迅雷白金会员,下载速度可以达到40多M。如果不是会员或者黄金会员可能会慢一些。如果家里带宽足够高,应该也是可以的。
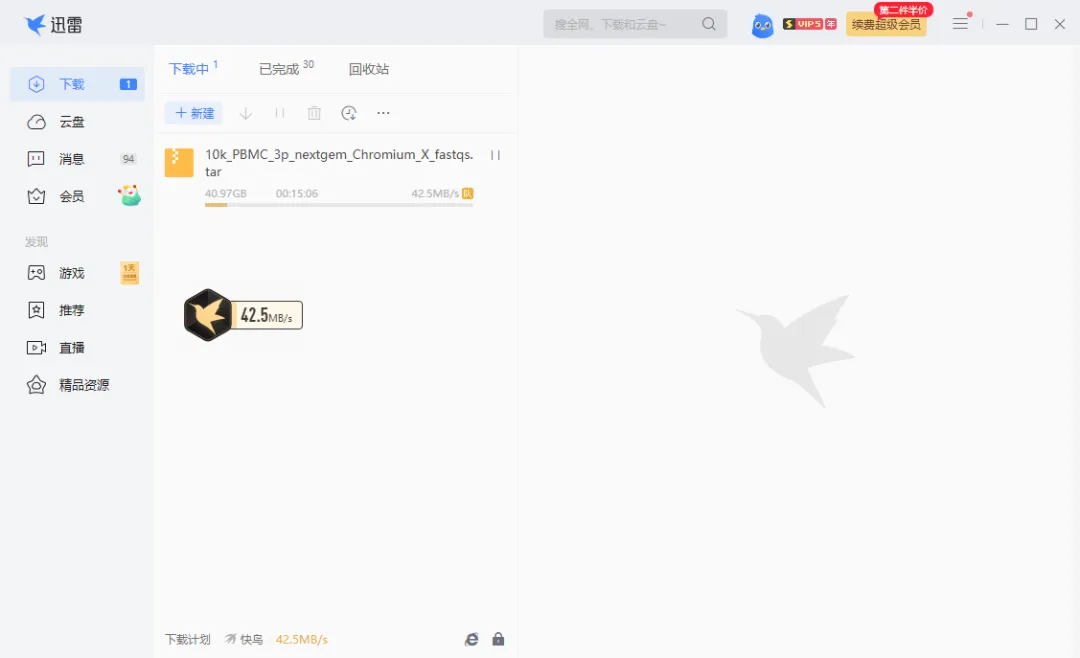
虽然下载了数据,但是下载到了个人电脑上,还是得传到服务器上,这个速度就慢了,慢慢传吧。
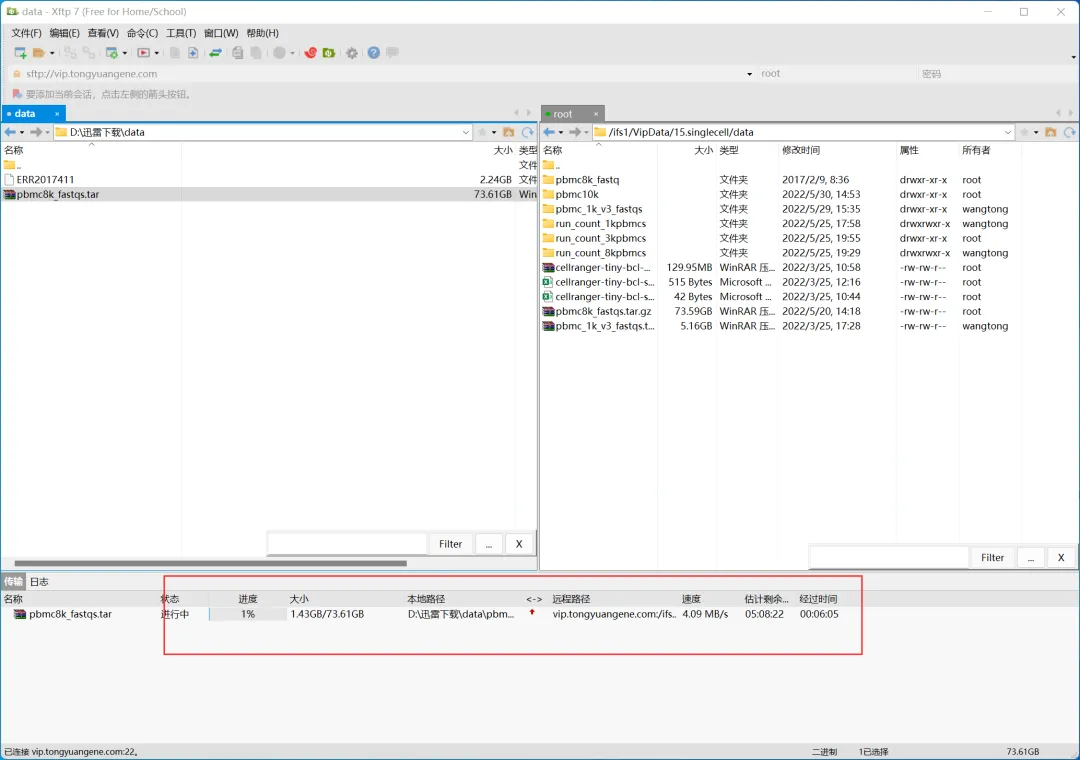
如果你使用ubuntu系统,可以直接安装linux版本迅雷,直接下载到服务器上。我用centos,没有图形界面,就这么操作了,服务器端网速也没家里快。虽然麻烦,但也完成任务,殊途同归。
获取SRA下载地址
迅雷主要支持https开头的地址,所以我们要找到文件的这样地址。
例如下载的案例
https://trace.ncbi.nlm.nih.gov/Traces/?run=SRR11874161
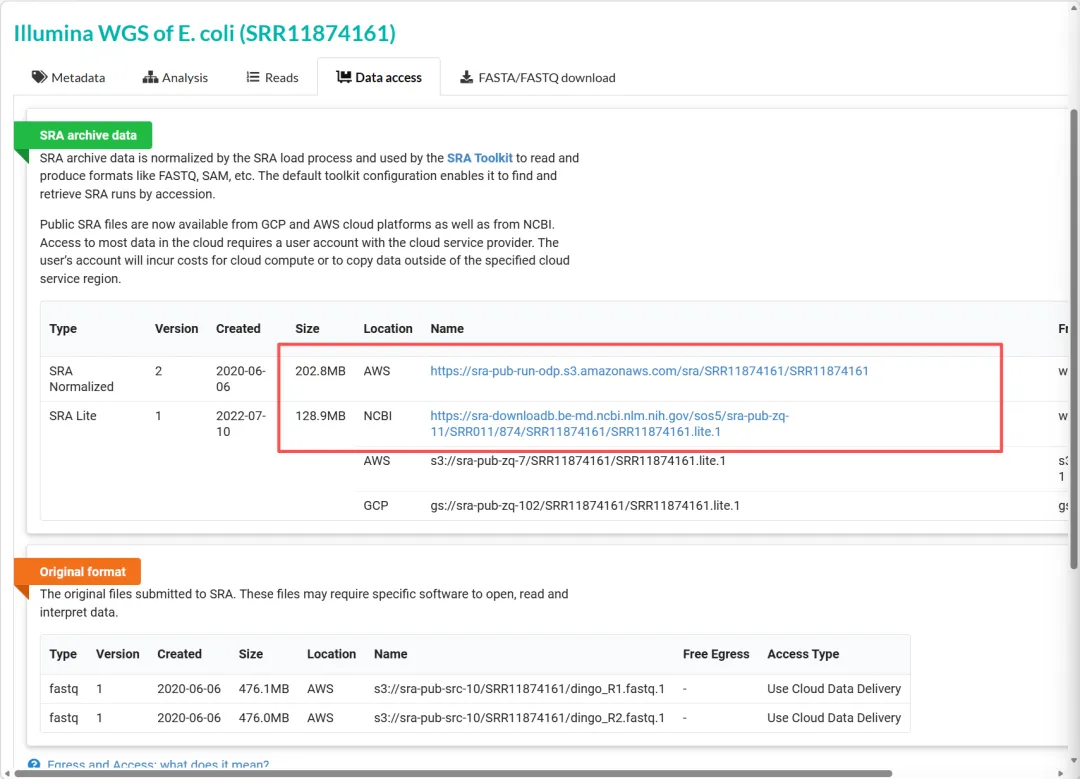
我们直接获取https开头的地址即可。
如果数据实在ENA数据库,我们要用鼠标右键获取数据地址。
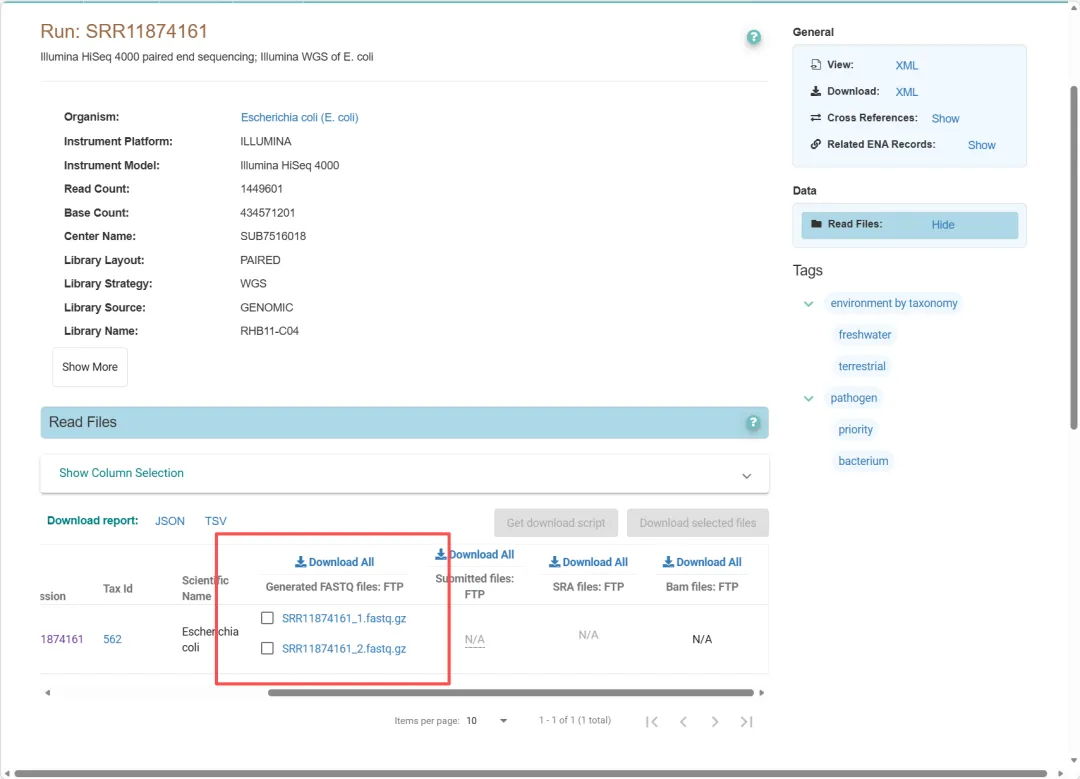
ftp://ftp.sra.ebi.ac.uk/vol1/fastq/SRR118/061/SRR11874161/SRR11874161_1.fastq.gzftp://ftp.sra.ebi.ac.uk/vol1/fastq/SRR118/061/SRR11874161/SRR11874161_2.fastq.gz
批量下载SRA数据
我们也可以使用迅雷批量下载SRA数据,例如要下载下面这个项目数据。
https://www.ncbi.nlm.nih.gov/Traces/study/?query_key=2&WebEnv=MCID_62949972a373723fcb4dc041&o=acc_s%3Aa
下载Accession List文件。
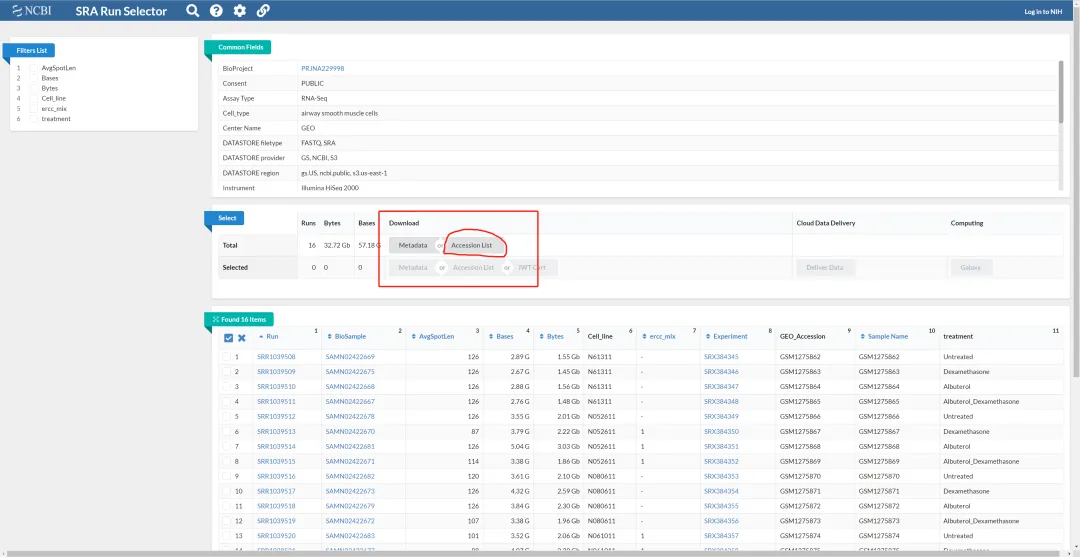
这批数据目前NCBI已经托管到AWS和Google Drive上了,还好可以用aws的地址进行下载。
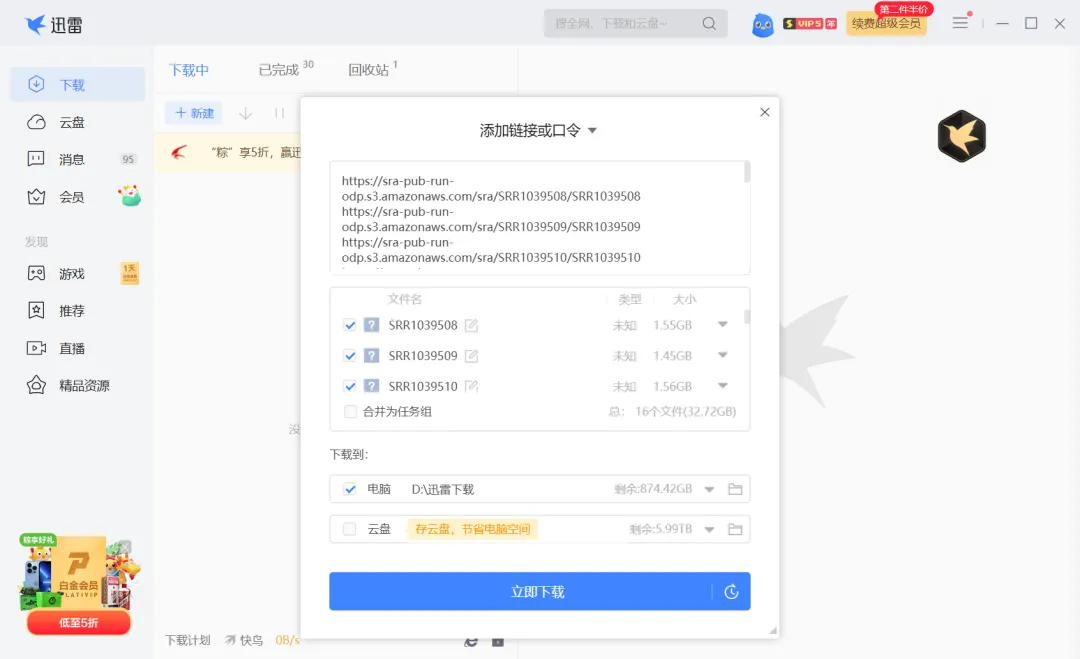
由于样品量多,且aws地址有规律,我们可以写一个批量的脚本,批量生成地址。
cat SRR_Acc_List.txt | while read i; doecho "https://sra-pub-run-odp.s3.amazonaws.com/sra/${i}/${i}"done
输出结果
https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039508/SRR1039508https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039509/SRR1039509https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039510/SRR1039510https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039511/SRR1039511https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039512/SRR1039512https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039513/SRR1039513https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039514/SRR1039514https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039515/SRR1039515https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039516/SRR1039516https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039517/SRR1039517https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039518/SRR1039518https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039519/SRR1039519https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039520/SRR1039520https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039521/SRR1039521https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039522/SRR1039522https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR1039523/SRR1039523
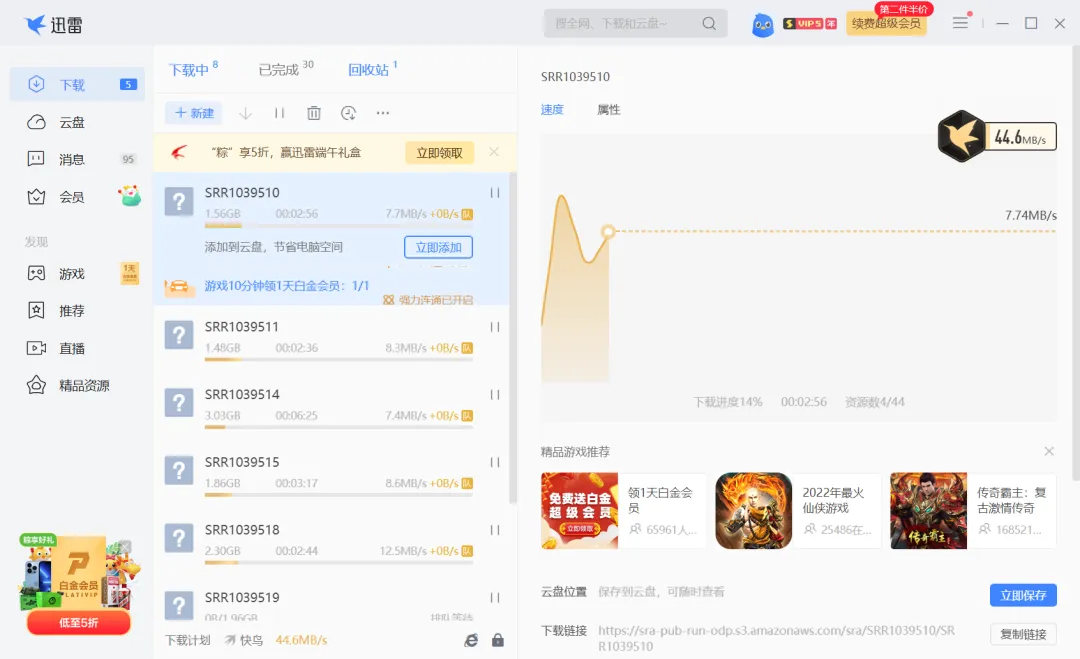
在迅雷里新建任务,将全部地址复制进去即可。
作为尊敬的迅雷白金会员用户,下载速度依然很快。
下载ftp文件
如果一个文件是通过ftp方式发布的,我们也可以使用迅雷来进行下载。例如下面是一个我们通过lftp方式访问nmdc数据库上的一个文件,需要找到文件目录,然后使用mget命令在命令行下载。
lftp ftp://download.nmdc.cn/lscd tools/condamget gtdbtk.tar.gz
下面我们将文件的地址写在一起。
ftp://download.nmdc.cn/tools/conda/gtdbtk.tar.gz然后将ftp开头的文件直接放到迅雷中就可以直接下载了。