 夜雨聆风
夜雨聆风tags: [openclaw, AI, RAG, knowledge-base, dev-tools]

你是否遇到过这样的困境:让 AI 帮你处理文档,问它细节问题却答不上来?或者想让 AI 基于你的个人笔记来回答问题,却发现它根本“看不到”这些内容?
这个困扰其实很普遍。AI 模型的训练数据有截止日期,而你的知识是动态的、私有的。当你想让 AI 帮你处理自己的文档、笔记或资料时,传统的问答方式往往力不从心。
不过现在,我有了新的解题思路:给 OpenClaw 增加知识库能力。
为什么 OpenClaw 需要知识库
OpenClaw 是一个 AI 工作助手,它的定位是成为你日常工作的智能伙伴。无论是编程、写文档、还是处理信息,OpenClaw 都能提供强大的帮助。
但在实际使用中,我发现了这样一个需求:能不能让 OpenClaw 也“读懂”我的私有文档?
比如:- 让它基于我写的技术笔记来回答问题?- 让 AI 帮我从海量文档中检索信息?- 让 AI 基于我的需求文档来生成方案?- 让 AI 从我的资料库里总结关键内容?
这些场景都指向同一个能力:知识库。
现有的 OpenClaw 本身不擅长这件事,它更像是一个通用的 AI 助手,而不是专攻知识管理的工具。这恰恰是我需要增强的方向。
RAG:让 AI “看见” 你的知识
解决问题的关键技术叫做 RAG,中文名叫“检索增强生成”。听起来很学术,但原理并不复杂。
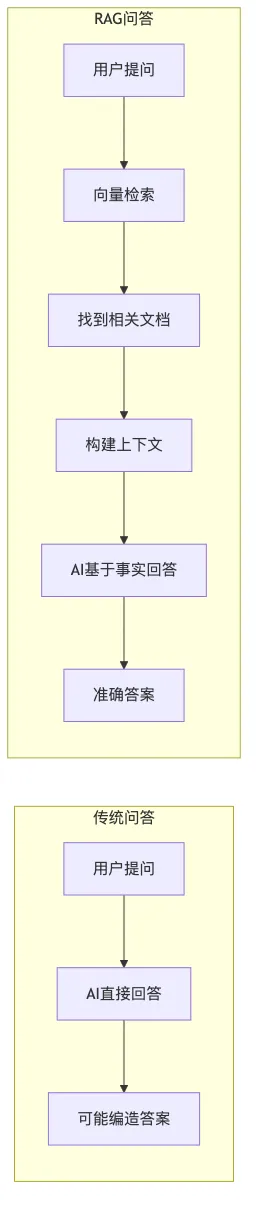
想象一下,你给 AI 一份产品文档,然后问它具体的技术细节。如果只是简单问答,AI 可能会“一本正经地胡说八道”,因为它记不清文档里的具体内容。但如果换一个方式会怎样?
先把文档的内容拆成一小段一小段,每段都转换成一种特殊的“数字编码”——这就是向量。然后把这些向量存起来。当用户提问时,不是直接让 AI 回答,而是先在向量库里找到“最相关”的段落,把这些段落作为“参考资料”一起发给 AI。这样 AI 就能基于真实的文档内容来回答问题,而不是凭空编造。
这就是 RAG 的核心思路:先检索,再生成。
我的解决思路:构建本地知识库系统
最近我一直在思考,如何为 OpenClaw 增加知识库能力。我的方案是为它开发一个知识库插件,让它具备本地知识库的构建和检索能力。
整体思路是这样的:
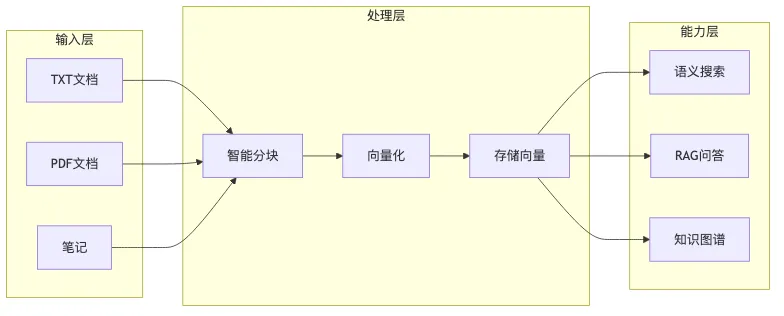
第一步:文档处理
用户提供原始文档,可以是技术文档、学习笔记或者任何文本内容。系统会对文档进行智能分块,按照段落和句子来拆分,每块控制在合理长度(500 字符左右)。这样做的好处是既保留了语义完整性,又不会因为单块过长而影响检索精度。
第二步:向量化存储
然后,每个文本块都会被转换成向量。这里我用到了中文优化的 Embedding 模型,能够准确捕捉文本的语义信息。向量会配上唯一的 ID,存储到本地文件中。整个过程完全离线,不需要依赖外部云服务。
第三步:RAG 问答
当用户提问时,系统会把问题也转换成向量,然后在向量库中进行相似度搜索,找到最相关的几个文本块。最后,把这些问题和检索到的相关段落一起发送给 AI 模型,让它基于真实的文档内容来生成答案。
技术架构设计
为了更好地理解这个方案,让我从架构层面来介绍一下。
整个系统分为几个层次:
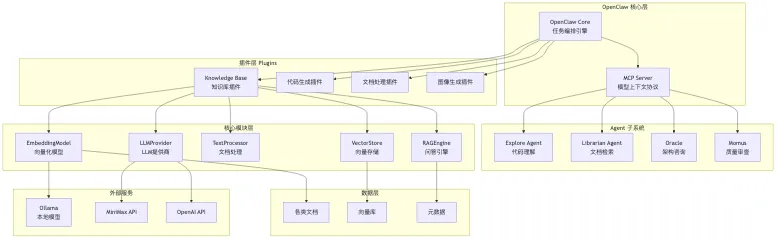
OpenClaw 核心层是整个系统的大脑,负责任务编排和 Agent 协调。
Agent 子系统提供各种能力:代码理解、文档检索、架构咨询,质量审查。
插件层是扩展 OpenClaw 能力的关键:- Knowledge Base:知识库插件- 代码生成插件:处理编程相关任务- 文档处理插件:处理各种文档格式- 图像生成插件:文生图能力
核心模块层是知识库插件的底层支撑:- EmbeddingModel:负责把文本转换成向量- LLMProvider:对接各种大语言模型- TextProcessor:处理文档分块- VectorStore:管理向量存储- RAGEngine:协调整个 RAG 流程
数据层存储原始文档和向量数据。
外部服务层对接各种模型服务。
这是具体的数据流:

向量库创建流程:输入文档 → 文档分块 → 向量化 → 存储
RAG 问答流程:用户问题 → 向量化 → 相似度检索 → 构建 Prompt → LLM 生成 → 返回答案
实际应用场景
这个能力能做什么?
技术文档助手是我最常用的场景。把我学习技术时记录的笔记、踩坑记录、方案总结都转换成向量库,然后问 AI 任何关于某个技术点的问题,它都能基于我写的文档来回答。
比如问:“之前我整理的 Docker 网络排查步骤是什么?”AI 会从向量库中检索我之前记录的文档,然后告诉我具体的排查流程。
个人知识管理也很实用。把我的学习笔记、项目经验、思考总结都建成向量库,AI 就能帮我快速检索和总结。遇到问题时,直接问 AI,它会从我的笔记中找到相关的内容来回答。
内容创作助手也是个好场景。把平时收集的参考资料、素材文档都建成向量库,写作时可以让 AI 根据这些素材来生成内容,保证内容的准确性和一致性。
为什么选择本地部署
我这个方案的一个核心特点是本地部署。
隐私保护:所有数据都存在本地,不会发送到第三方云服务。你的文档、笔记、资料都是私密的,不会泄露。
成本可控:不需要额外的向量数据库服务,本地文件存储零成本。Embedding 模型可以本地运行,LLM 也可以选择免费或本地方案。
离线可用:不需要网络也能使用知识库功能,随时随地都能查询你的文档。
定制灵活:可以根据自己的需求选择不同的 Embedding 模型和 LLM 服务,不受制于特定供应商。
未来的可能性
这只是一个开始。随着方案的完善,我可以支持更多文档格式,比如 PDF、EPUB、Markdown、Word 等。多语言 Embedding 也在计划中,这样就能处理英文、日文等多种语言的知识库。
更深层的方向是引入知识图谱,把文档之间的关联关系也存储起来,让 AI 不仅能找到相关内容,还能理解知识之间的联系。
另一个方向是多知识库联合检索,让你可以同时管理多个不同的知识库,AI 会根据问题自动选择合适的知识库来回答。
还有对话式知识管理,支持多轮对话,记住上下文,让你可以深入探讨文档内容,就像有一个专业的助手在旁边一样。
写在最后
AI 的能力再强,如果“看不到”你的知识,就无法真正为你所用。RAG 技术的价值,就是搭建起一座桥梁,让 AI 能够访问我们的私有知识库。
给 OpenClaw 增强知识库能力,是我最近在探索的一个方向。本质上,我希望让 AI 助手不仅是工具,也成为你个人知识的智能入口。
如果你对这套方案感兴趣,欢迎在评论区交流讨论。也欢迎点个赞、在看,让更多志同道合的朋友看到这篇文章。
我们下期再见!
title:参考资料-什么是RAG:检索增强生成技术简介-向量数据库:赋能AI的长期记忆-本地部署AI模型的实践指南