 夜雨聆风
夜雨聆风用 OpenClaw 自带基础记忆的时候,我一直有个很强的体感:它不是完全没记住,而是记得不太对。
刚聊没几轮的时候还行,越往后越容易出问题。前面明明说过的偏好、项目背景、一些已经确认过的约束,到了后面就开始松动,像是隔着一层雾。尤其一旦对话拉长,记忆这件事就不再像“记住”,更像“模糊猜到你可能提过”。OpenClaw 官方文档里其实也把记忆说得很实在:真正的记忆,本质上是写进工作区里的 Markdown,再由当前启用的 memory 插件负责检索,不是模型脑子里天然会一直带着。
所以我这两天看到 memory-lancedb-pro 的时候,会有一种“这才像是该补的地方终于补上了”的感觉。
这个插件是给 OpenClaw 做长期记忆增强的,作者写得也挺直接:它不是在原版 memory-lancedb 上修修补补,而是把整套检索链路往前推了一大截。最核心的一点,是它不再只靠单一向量搜索,而是把 向量检索和 BM25 关键词检索混在一起做融合,再加上 cross-encoder 重排,让召回结果不只是“语义像”,也能兼顾“关键词真对得上”。
这个区别其实很关键。
很多人一开始觉得,记忆插件嘛,能搜回来就行。但真用久了就会发现,AI 记忆最烦的不是“完全忘了”,而是“捞回来一堆不该捞的”。你问一个具体问题,它给你翻出一段语义相近但不在点上的旧上下文;你提一个明确关键词,它又因为只做向量相似,把真正重要的那条压到后面去了。memory-lancedb-pro 这一套混合检索,说白了就是不想再让 Agent 靠“差不多”过日子。 而且它不是只有检索思路升级这么简单。
我看 README 时有个地方挺戳我:它把很多原本只存在于“生产环境里应该有”的东西,也一起补进来了。比如 recency boost、time decay、length normalization、MMR 多样性选择、noise filtering、adaptive retrieval,甚至还有 session memory 和 管理用 CLI。这就不是那种“能跑起来”的插件了,而是明显在往“跑久了也别乱”这个方向做。
尤其是“最新、最核心的信息优先”这件事,它显然是认真想过的。
因为长期记忆这东西,一旦存多了,最大的问题不是容量不够,而是旧信息开始污染新判断。你以前说过一次的话,后来改主意了;你之前项目是那个结构,现在已经重构了;你某个习惯上个月成立,这个月不成立了。如果检索层没把“时间”当回事,Agent 就很容易一本正经地把过期信息重新端回来。memory-lancedb-pro 里专门做了时间衰减和新鲜度加权,本质上就是在解决这个问题。
还有一点我觉得对折腾本地部署的人很重要。
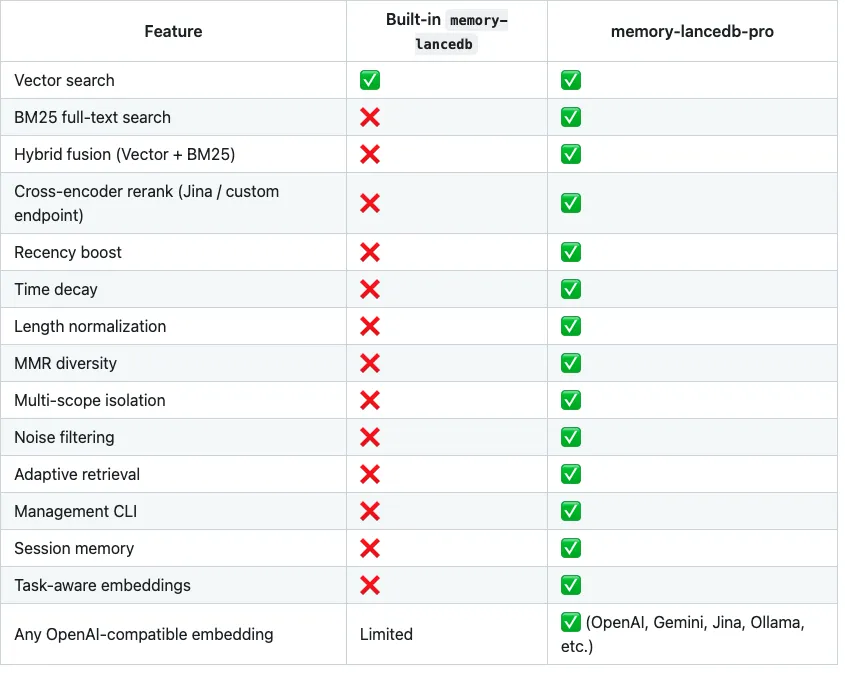
OpenClaw 官方文档讲得很清楚,记忆能不能用,取决于你启用了哪个 memory 插件;而原版 memory-lancedb 在社区里一直有人吐槽,它对嵌入模型的支持比较受限,甚至有 issue 明确提到它基本绑在 OpenAI 的 embedding 上,本地 Ollama 这类方案并不友好,而且这个需求后来还被标成 not planned。 但 memory-lancedb-pro 这边,README 直接写了自己支持 OpenAI-compatible embedding,包括 OpenAI、Gemini、Jina、Ollama 等多种接口,灵活度明显高一截。
这就很现实了。
因为很多人玩 OpenClaw,本来就是冲着可控、可折腾、本地化去的。结果记忆层反而卡在“你得先接某一家云服务”,这体验其实挺别扭。现在这个插件至少把路铺平了:你要云上能配,你要本地也能配,不至于为了让 Agent 记住点东西,还得先在接口层绕一圈。
还有个让我有点在意的小细节,是它提到了 reflection recall 这套东西。它不是单纯把旧记忆捞出来喂给模型,而是在做一种更动态的反思式召回和聚合。这个方向很像是想让 Agent 不只是“背资料”,而是边聊边修正自己怎么用这些资料。离真正意义上的“自我反思和纠错”当然还有距离,但至少方向是对的。
所以如果你最近也在折腾 OpenClaw 小龙虾,已经开始对原生记忆有点不耐烦了,这个插件确实值得试一下。
它最打动我的地方,不是又堆了多少个 fancy 名词,而是终于有人认真对待一件很朴素的事:Agent 的记忆,不该只是“存下来”,而应该是“下次真能用对”。
这两者,看着只差一点,实际差得挺远。
GitHub地址: win4r/memory-lancedb-pro
