 夜雨聆风
夜雨聆风专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
你的龙虾助手能自己进化了。
每次交流后系统都会悄悄进化,变得更懂你的心思。
仅仅通过日常交流和使用就能实现自我迭代,将原本被丢弃的聊天记录转化为高价值的训练数据。

普林斯顿大学研究团队发布了全新的强化学习框架OpenClaw-RL。
该框架能够实时捕捉用户的反馈与环境运行结果,将隐性评价和显性纠正转化为指导智能体进化的信号,无缝衔接个人设备的定制化需求与云端的大规模通用任务训练。
挖掘日常互动的隐藏信号
当前部署的各类智能体无时无刻不在与真实世界产生海量互动。
智能体执行完每一个动作后都会接收到来自外部环境的下一个状态信号。
用户的一句回复或软件工具的一串输出结果构成了庞大而繁杂的信号流。
现有的系统普遍将后续产生的信息仅仅当作生成下一句回复的上下文背景。
系统读取完历史记录便随即抛之脑后。
研究团队发现日常丢弃的交互废料包含着极具价值的信息,并将反馈信号清晰地划分为两种截然不同的维度:评价性信号和指令性信号。
评价性信号就像是天然的打分器。
系统执行完动作后,外界的反应直接给出了成绩。
用户连续追问代表初次沟通失败。代码测试用例全部通过代表逻辑满分。程序弹出错误追踪日志等于直接给出了零分。
目前行业内习惯耗费巨资雇佣人类专家专门给模型输出结果打分。
日常交互中产生的满意度评价和对错判定其实每分每秒都在免费产生。
传统的训练框架完全无视实时产生的活数据,且只能依赖提前打包好的静态数据集进行离线训练。
指令性信号构成了更为珍贵的宝藏。
外界反馈除给出对错评判外,更直接指明了修改的具体方向。
用户在聊天框里敲下不该使用某某函数库,明确给出了针对词汇级别的修正指导。
详尽的报错日志同样包含着明确的逻辑修正线索。
常规的标量奖励机制只能给出一个干瘪的分数,完全无法吸收蕴含在文本中的方向性指导。
现有的知识蒸馏技术高度依赖提前人工筛选的问答配对数据。
研究人员打破了静态数据集的限制,直接从实时产生的数据流中提取出带有指导意义的文本线索。
独立解耦的异步运转机制
为了在不影响用户正常体验的前提下捕捉实时互动数据,研究团队打造了完全解耦的异步架构。
底层系统建立在开源的异步框架slime之上。
模型推理服务、环境运行节点、奖励评分系统以及策略训练引擎被拆分成四个互不干扰的独立循环模块。
相关的架构全貌类似下图。
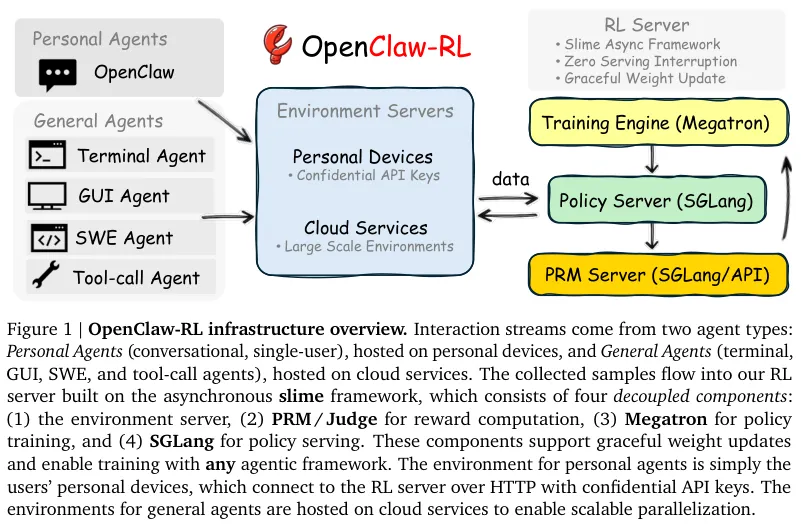
任何单一模块都不需要停下来等待其他模块的运行进度。
基于SGLang搭建的推理引擎专注于为用户提供流畅的对话响应。
负责处理历史数据的过程奖励模型(Process Reward Model)在后台同步分析刚刚发生的对话。
Megatron训练引擎根据积累的梯度数据更新神经网络权重。
用户体验毫无卡顿感。
架构设计的核心在于极强的场景扩展能力。
个人智能体的运行环境直接部署在用户的私人设备上。
私人电脑或手机通过加密的API与后端的服务器进行连接。
系统将每一次接口请求精准划分为主线轮次和支线轮次。主线轮次涵盖智能体的核心回复与工具执行结果并直接转化为可供训练的优质样本。
云端部署版本展现出应对海量通用任务的强悍算力。系统原生支持极为广泛的真实世界应用场景。
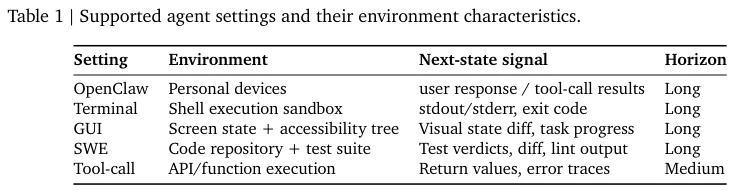
多类场景的具体设定如下。
所有交互数据与奖励评分都会在后台进行无阻塞的日志记录。
写入操作采用异步触发机制完全不增加系统延迟。
日志文件会在模型完成一次权重更新后自动清理,从而确保收集到的数据始终与当前策略模型版本保持绝对一致。
融合打分与文本指导
框架通过两套互补的机制将形态各异的信号流转化为推动模型进化的策略梯度。
二元强化学习机制专门负责处理评价性信号。
系统利用多数投票机制构建出一个强大的评分裁判模型。给出一句回复以及随后的环境状态,裁判模型会评估动作质量并赋予1、负1或0的分值。
工具调用结果通常能推导出清晰的结论。用户回复需要模型深入揣摩其中蕴含的满意程度。裁判模型会发起多次独立的查询计算并采用多数票决定的方式输出最终分值。
下方的方法概览详细展示了对应流程。
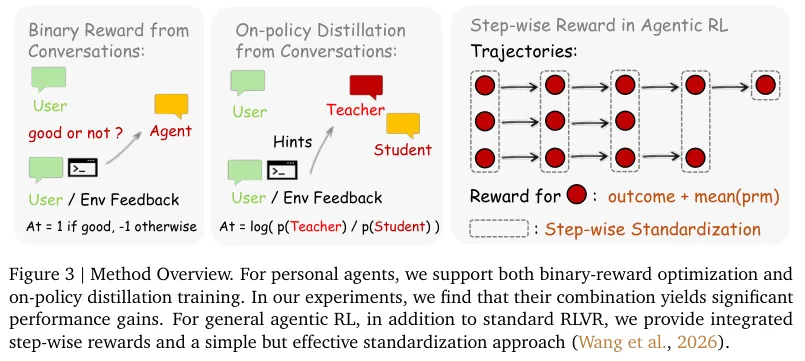
二元强化学习将外界反馈的丰富内涵压缩成了一个数字。
后见之明引导的在线策略蒸馏(On-Policy Distillation)技术复原了信号中丢失的文本深度。
用户在聊天中指出错误细节时,系统会将外界状态信号转化为Token级别的监督指令。
系统在后台执行巧妙的提示词提取操作。
裁判模型一旦判定某次互动存在明确的纠正信息,便会从繁杂的用户回复中提炼出简洁的操作指南。
人类交流习惯将抱怨与新的提问混杂在一起。系统主动过滤杂音并萃取出专注指出缺陷的指令。
提取出的指令经过严格质量筛查只有长度超过10个字符且信息量丰富的提示才能进入下一环节。
在线策略蒸馏技术以牺牲样本数量为代价换取了指令维度上的极高精度。
经过提炼的纠正指令被拼接到上一轮用户输入的末尾构建出增强版的教师上下文。
策略模型重新审视自己原本的回答并计算出每一个Token的对数概率。
教师视角下的模型为极其准确的Token赋予正向优势值,从而引导其在未来的生成中提高出现频率。
不恰当的Token面临概率上的压制。定向指导超越了传统的标量打分机制。
相关机制的维度的对比如下表。
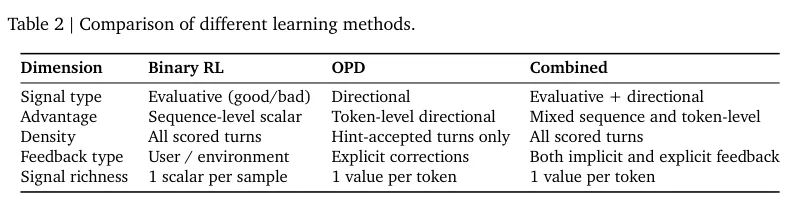
两套机制在实际运行中展现出极佳互补性。
二元强化学习照单全收所有被评分的交互轮次并提供广泛的梯度覆盖。
在线策略蒸馏专注于捕获包含明确指令的高质量交互,以提供高分辨率的微观修正。
系统将两者的优势值在数学层面上进行权重叠加。
对于执行周期极长的复杂任务系统引入了分步奖励机制。过程奖励模型根据实时产生的状态信号,为每一个操作步骤独立打分,从而保障长周期任务下的稳定收敛。
真实场景的性能验证
研究团队在统一的基础设施之上设计了两条平行的测试轨道。
个人智能体轨道聚焦于通过对话信号实现用户偏好的持续定制。
测试场景极具现实色彩,模拟了一位正在使用个人电脑写作业,且希望隐藏自己使用了人工智能辅助的学生。
助手生成的文风必须贴合人类自然表达习惯。另一个独立的大语言模型扮演挑剔的学生并不断抛出数学问题。
系统设定了极低的学习率,并规定每收集16个训练样本就触发一次后台权重更新。
另一场景中,挑剔的教师角色要求批改作业的评语必须具体且充满友善的温度。
相关模拟的对话细节如下图。

结合了二元强化学习与在线策略蒸馏的混合优化方法,取得了最耀眼的成绩。
纯粹依靠在线策略蒸馏由于触发条件严苛,导致样本稀疏从而产生一定延迟。
下方的表格清晰展示了各项得分对比。
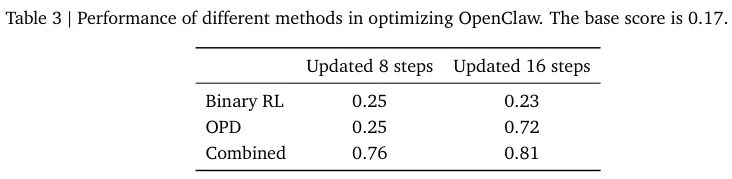
学生模拟场景下助手经历36次问题解答互动,便抛弃了机器味的表达习惯。
教师批改场景中仅需短短24次互动,系统产出的评语就变得细致且充满人情味。
通用智能体轨道投入了涵盖40亿至320亿参数规模的庞大模型矩阵。
终端执行环境使用了相关数据集,图形界面智能体在验证环境里摸爬滚打,软件工程测试依托代码库展开,工具调用能力的训练也随之同步推进。
下方的折线图描绘了通用智能体的强化学习扩展情况。
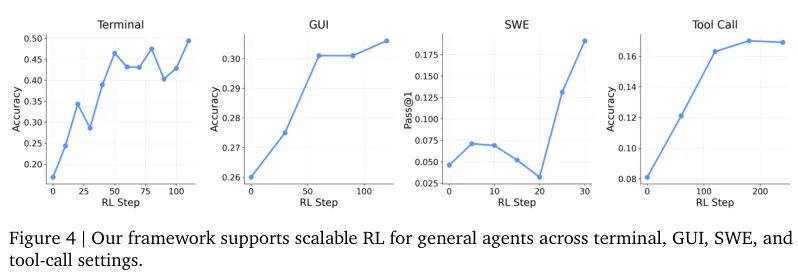
云端的大规模并行计算撑起了高效的训练流。
针对长周期复杂任务的探索揭示了过程奖励机制的不可替代性。
研究数据印证了过程奖励与最终结果奖励相融合的巨大威力。混合打分模式全面超越了单一结果导向模式。
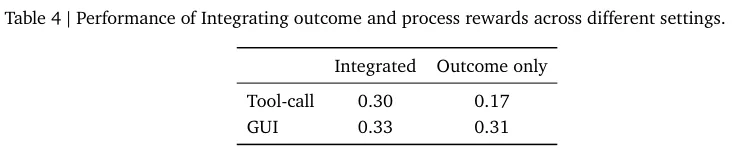
在云端预留计算资源去运行过程奖励模型,换来了整个系统执行长线任务时无可匹敌的准确度。
每经历一次互动,系统对世界的理解就深刻一分。
OpenClaw-RL用最朴素的对话,蹚出了一条通往全自动自我进化的新路径。
参考资料:
https://github.com/Gen-Verse/OpenClaw-RL
https://arxiv.org/pdf/2603.10165
END
点击图片立即报名👇️





