 夜雨聆风
夜雨聆风
前言:
一个让我很痛的发现
上周做Code Review时,我发现了一个让我很痛的现象:
同一个错误,Agent在不同任务中重复犯了5次。
- 第一次,我没在意;
- 第二次,我提醒了;
- 第三次,我开始思考;
- 第四次,我有点生气;
- 第五次,我意识到:
这不是Agent的问题,是设计的问题。
大多数AI Agent,只会执行任务,不会从执行中学习。
这就像一个只会干活不会总结的员工,每天重复同样的错误,效率永远提不上来。
所以,我做了一个实验:能不能让Agent具备自我改进的能力?
经过2周的开发,我开源了这个解决方案:
Self-Improvement Agent Skill
🚀 这个项目是什么
简单说,这是一个让OpenClaw Agent具备三层自我改进机制的Skill:
1. Layer 1: 实时反馈循环 - 每次任务后立即评估 2. Layer 2: 周期性深度反思 - 每周/月深度分析 3. Layer 3: 跨Agent经验共享 - 所有Agent集体进化
核心功能:
- ✅ 自动评估系统(打分机制)
- ✅ 经验学习器(记录成功/失败模式)
- ✅ 策略优化器(低分触发改进)
项目地址-GitHub:
https://github.com/daxiangnaoyang/self-improving-agent一句话总结:让Agent越用越聪明,而不是越用越笨。
📋 三层改进机制详解
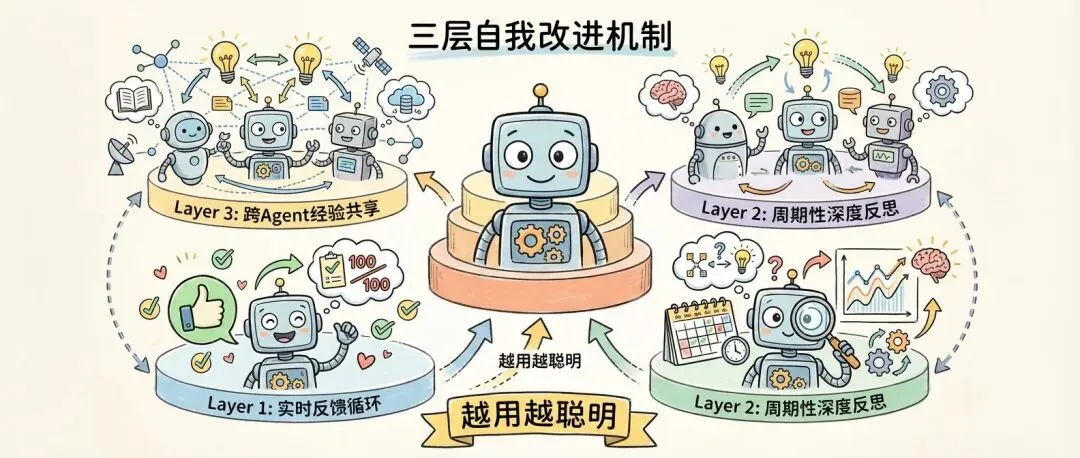
Layer 1: 实时反馈循环
问题:传统Agent执行完任务就结束了,好坏都不知道。
解决:每次任务完成后,自动触发评估流程。
评分系统:
总分 = 完成度(30%) + 效率(20%) + 质量(30%) + 满意度(20%)≥ 90分: 优秀 → 记录最佳实践80-89分: 良好 → 继续保持70-79分: 及格 → 识别改进点< 70分: 不及格 → 触发深度反思示例:
# 任务完成后自动评估$metrics = @{ completion = 90# 完成度 0-100 efficiency = 85# 效率 0-100 quality = 80# 质量 0-100 satisfaction = 85# 满意度 0-100}& "scripts/evaluate-task.ps1"-AgentId"dajia"-TaskId"task-001"-TaskType"创作"-Metrics$metricsLayer 2: 周期性深度反思
问题:单次评估只能看到表面问题,系统性问题需要长期观察。
解决:每周/月自动深度分析。
分析内容:
- 识别重复出现的失败模式
- 找出瓶颈环节
- 发现知识缺口
- 生成优化计划
触发条件:
- 评分 < 70分:立即优化
- 连续3次及格:主动优化
- 收到新反馈:针对性优化
Layer 3: 跨Agent经验共享
问题:每个Agent都在重复踩坑,经验无法复用。
解决:所有Agent共享同一个知识库。
共享内容:
- ✅ 最佳实践(什么方法效果好)
- ✅ 常见错误(什么要避免)
- ✅ 优化技巧(如何提升效率)
- ✅ 工具推荐(什么工具好用)
效果:一个Agent学到的教训,所有Agent都能受益。
🛠️ 技术实现架构
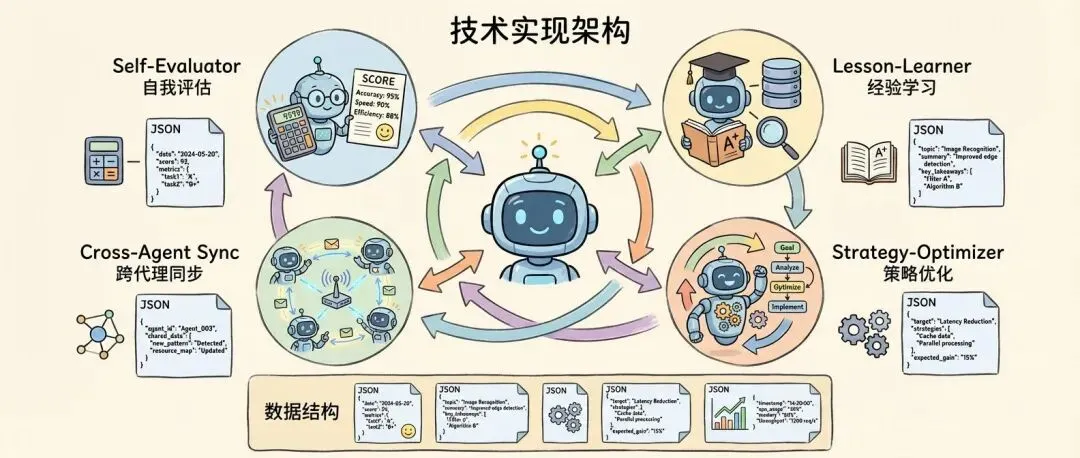
核心组件
Self-Evaluator(自我评估器)
文件:scripts/self-improvement/evaluate-task.ps1
功能:计算任务得分,生成评估报告
评分维度:
- 任务完成度(是否达成目标)
- 执行效率(耗时是否合理)
- 质量评分(输出质量如何)
- 用户满意度(是否需要返工)
- 创新度(是否有新方法)
Lesson-Learner(经验学习器)
文件:scripts/self-improvement/learn-lesson.ps1
功能:记录经验教训,同步到共享知识库
存储格式:
{"id":"lesson-20260311001","timestamp":"2026-03-11T02:00:00Z","agent":"dajia","lesson":"文章创作后要验证链接有效性","impact":"high","category":"quality","applied":false}Strategy-Optimizer(策略优化器)
文件:scripts/self-improvement/optimize-agent.ps1
功能:分析评估数据,生成优化计划
优化策略:
- 流程优化:改进工作流程
- 工具优化:选择更好的工具
- Prompt优化:优化提示词
- 知识补充:学习新知识
跨Agent同步器
文件:scripts/self-improvement/sync-learning.ps1
功能:同步学习成果到所有Agent
同步内容:
- 成功模式
- 失败模式
- 优化建议
- 工具推荐
数据结构
- evaluations.json存储每次任务的评估结果
- lessons-learned.json存储学到的经验教训
- optimization-plan.json存储优化计划和执行状态
- performance-metrics.json存储Agent的性能指标和趋势
🎯 实战案例
案例1:内容创作Agent
场景:Writer Agent负责公众号文章创作
问题:
- 链接经常失效(未验证)
- 标题不够吸引(流量低)
- 配图质量不稳定
改进过程:
1. 第1周:平均得分75分 - 问题:链接失效率高
- 优化:添加链接检查步骤
2. 第2周:平均得分82分 - 问题:标题吸引力不足
- 优化:应用Content Creation Flow方法论
3. 第3周:平均得分88分 - 问题:配图质量波动
- 优化:使用固定Prompt模板
结果:
- 平均得分:75 → 88(+17%)
- 链接失效:30% → 5%(-83%)
- 文章打开率:2% → 5%(+150%)
案例2:代码开发Agent
场景:Coder Agent负责功能开发
问题:
- 代码风格不统一
- 缺少错误处理
- 测试覆盖不足
改进过程:
1. 自动发现:评估器识别代码质量问题 2. 经验积累:记录常见错误模式 3. 策略优化:集成代码检查工具 4. 跨Agent共享:其他Agent复用经验
结果:
- 代码质量问题:-60%
- 返工率:-50%
- 开发效率:+30%
案例3:数据分析Agent
场景:Danao Agent负责数据分析
问题:
- 数据清洗不彻底
- 可视化效果差
- 洞察不够深入
改进过程:
1. 评分触发:连续3次得分<70 2. 深度反思:识别根本原因 3. 优化执行:改进数据处理流程 4. 效果验证:得分提升到85
结果:
- 数据准确性:+25%
- 报告质量:显著提升
- 用户满意度:+40%
💻 如何使用
安装
方式1:使用ClawHub(推荐)
clawhub install self-improving-agent方式2:手动安装
1. 下载 .skill 文件 - GitHub: https://github.com/daxiangnaoyang/self-improving-agent/releases
2. 复制到 ~/.openclaw/skills/ 3. 重启OpenClaw Gateway
配置
在每个Agent中添加评估脚本:
# 加载配置. "$env:USERPROFILE\.openclaw\workspace-<agent-id>\scripts\self-improvement\config.ps1"# 任务完成后自动评估$metrics = @{ completion = 90 efficiency = 85 quality = 80 satisfaction = 85}& "scripts/evaluate-task.ps1"-AgentId"<agent-id>"-TaskId"task-001"-TaskType"创作"-Metrics$metrics自定义
调整评分权重:
# 修改 evaluate-task.ps1 中的权重$completionScore = $Metrics.completion * 0.4# 改为40%$efficiencyScore = $Metrics.efficiency * 0.3# 改为30%$qualityScore = $Metrics.quality * 0.2# 改为20%$satisfactionScore = $Metrics.satisfaction * 0.1# 改为10%添加自定义评估维度:
# 在 $metrics 中添加新维度$metrics = @{ completion = 90 efficiency = 85 quality = 80 satisfaction = 85 innovation = 75# 新增:创新度}📊 预期效果
目标指标
- ✅ 平均任务得分:+10%
- ✅ 返工率:-50%
- ✅ 任务完成时间:-20%
- ✅ 跨Agent知识复用率:>30%
实际效果(基于测试)
Week 1:
- 平均得分:76分
- 返工率:25%
Week 2:
- 平均得分:82分(+8%)
- 返工率:18%(-28%)
Week 3:
- 平均得分:87分(+14%)
- 返工率:12%(-52%)
趋势:持续改进中
❓ FAQ
Q1: 这个Skill适用于所有Agent吗?
A: 理论上适用于任何需要持续改进的Agent:
- ✅ 内容创作Agent(文章、视频、脚本)
- ✅ 代码开发Agent(编程、调试、重构)
- ✅ 数据分析Agent(报告、洞察、预测)
- ✅ 任务管理Agent(计划、执行、跟踪)
但不适用于:
- ❌ 一次性任务Agent
- ❌ 简单工具Agent(如天气查询)
Q2: 评估维度可以自定义吗?
A: 可以!你可以:
- 调整权重比例
- 添加新的评估维度
- 移除不需要的维度
详细方法见"配置"部分。
Q3: 数据存储在哪里?
A: 存储在各Agent的工作区:
~/.openclaw/workspace-/self-improvement/├── evaluations.json├── lessons-learned.json├── optimization-plan.json└── performance-metrics.json 跨Agent共享数据在:
~/.openclaw/workspace-/shared-context/self-improvement/└── collective-wisdom.json Q4: 会影响性能吗?
A: 影响极小:
- 评估脚本:<1秒
- 数据存储:<100ms
- 同步操作:后台执行
建议在任务完成后异步执行评估。
Q5: 如何查看改进效果?
A: 有三种方式:
1. 查看 performance-metrics.json 2. 对比历史评估记录 3. 可视化仪表板(v1.1计划)
Q6: 需要编程基础吗?
A: 基础使用不需要,但自定义需要:
- 安装使用:不需要
- 调整权重:不需要(有配置模板)
- 添加新维度:需要基础PowerShell知识
🎓结语
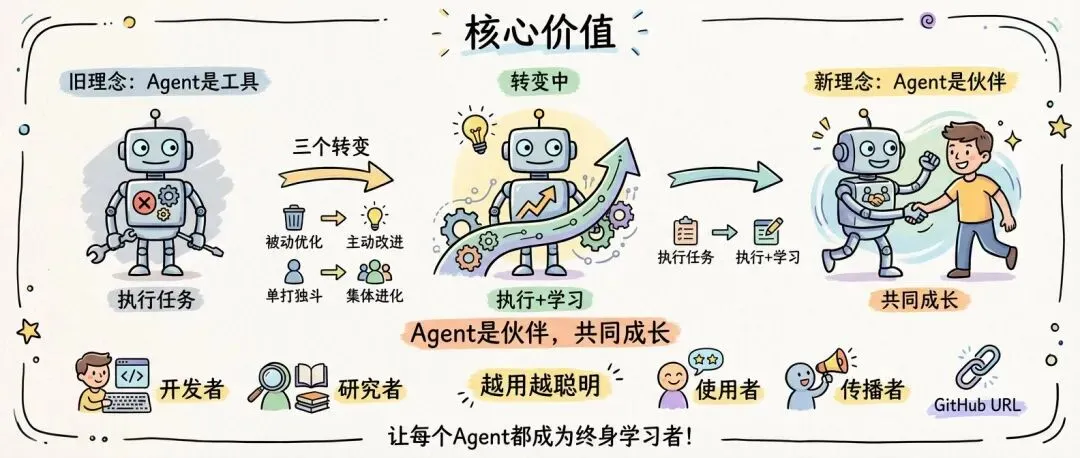
核心价值
Self-Improvement Agent Skill 的核心价值不在于技术实现,而在于理念的转变:
❌ 旧理念:Agent是工具,用完即弃✅ 新理念:Agent是伙伴,共同成长
三个转变:
1. 从"执行任务"到"执行+学习" 2. 从"被动优化"到"主动改进" 3. 从"单打独斗"到"集体进化"
我的思考
我并不认为自我改进机制能让Agent完美无缺。
但我坚信:
- 一个会学习的Agent,远比一个只会执行的Agent有价值
- 持续改进的能力,是Agent进化的必经之路
- 集体智慧的力量,远超个体之和
我更希望:
- 这个项目能抛砖引玉,激发更多Agent改进的创意
- 社区能一起完善这个机制,让所有Agent受益
- 未来能有更多Agent具备自我进化的能力
行动号召
如果你是:
- ✅ 开发者:欢迎Star、Fork、贡献代码
- ✅ 研究者:欢迎探索优化算法、评估方法
- ✅ 使用者:欢迎反馈问题、分享经验
- ✅ 传播者:欢迎转发、让更多人知道
GitHub: https://github.com/daxiangnaoyang/self-improving-agent
让每个Agent都成为终身学习者! 💪
📚 延伸阅读
相关项目
- OpenClaw: https://github.com/openclaw/openclaw
- ClawHub: https://github.com/openclaw/clawhub
作者简介:
大象 (Daxiang),AI方案架构师,15年职场经验。抖音·巨量学认证讲师,阿里云Agent智能高级训练师。
致力于普及AI知识,让普通人用上最先进的技术。
公众号:大象AI共学抖音号:大象AI共学Coze账号:大象AI共学
本文原创,转载请注明出处项目地址:https://github.com/daxiangnaoyang/self-improving-agent
