 夜雨聆风
夜雨聆风我每天消耗的 token 降到了 每天1 个亿。
作为典型的 Token 杀手:用的越多,越想省钱的心越多。
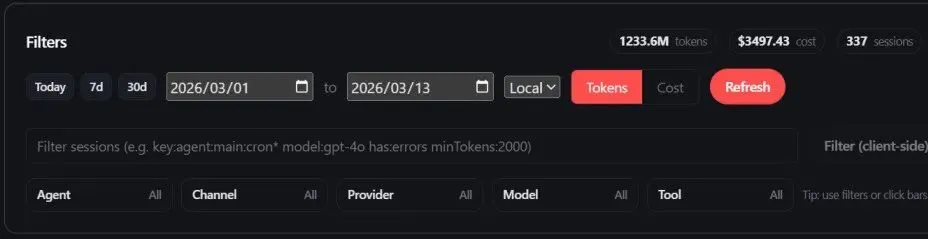
有时间的从表格开始逐条对照,按条目检查还有哪些办法省点钱。
内容长、干货多,建议先收藏。
省钱总览:三板斧(开源、节流、对账单)
总览 1:开源:先把“单价”打下来
输入输出约束:约束自己,也约束模型 |
总览 2:减少调用次数:少触发、少交互、少试错
总览 3:上下文窗口管理:让每次交互更便宜
/new 创建新会话/reset:重置下文 | |
总览 4:关掉后台自动化(别让钱花在看不见的地方)
提醒:迭代很快,不同版本/不同插件环境下命令可能略有差异。多让Openclaw自己来。
开源:先把“单价”打下来
1.1 包月/套餐:用量大就降单位成本
没用openclaw之前调用量小,直接调用API,Openclaw上了之后一不注意,一天200块。豆包、Kimi、硅基流动,整体上来讲都是贵到受不了。
之后用上了Coding Plan方案,主要面向Coding,但实际日常也一样。
Coding Plan 不是真正包月的,都是按时间段、按周、按月限制调用。
提醒:目前市场上的Coding Plan 具体的Token限制没有一个说清楚的,建议先买一个月试试。
阿里百炼Code Plan | |
Kimi Code | |
Minimax Code Plan |

作为日常使用minimax code plan确实够用,价格也不错。
1.2 渠道:咸鱼淘宝小红书,上车反重力
国产的这些模型在用过,gpt、opus之后,会觉得还是太弱了一些。
强烈建议至少有一个最小的gpt/opus方案,来拯救危局。
这时候很可能淘宝,小红书,小黄鱼才是省钱最大的神器。这个生意主要就是找人分担家庭账号,或者企业账号的费用,也是个很好的生意。
和KimiCode、阿里百炼相比,我认为非常有性价比。但也许也注意风险,同样大多的套餐还是有限额的,务必保有一个Minimax作为最后的保障。
1.3 模型分类:分工不同,价格不同
因为很多服务商不光限制token, 也限制总费用,费用也是限制条件之一。不同的模型价格差异很大,GTP-5.4是GTP-5 Mini的10倍价格。

整理清单、改格式、搬运内容、日常定时任务这些跑腿的事,用便宜量大模型。高质量书写、编码、推理攻坚才用聪明模型。
1.4 代理分工:专业的交给专业的人,别牛刀杀鸡
模型代表能力,但对openclaw来说agent(代理、数字人)才是干活的人关键。
就像理发店里面有学徒、首席、总监,我们需要根据出活效果要求让不同的大模型干活。
可以简单分类:固定三类岗位:
跑腿:抽取、去重、改格式、拉清单 写作:出大纲、改稿、脚本化表达 攻坚:难题推理、关键决策、复杂排错
不同的agent只处理自己的上下文,保证上下文窗口信息有效,钱花在刀刃上。
尽量信息减少遗忘,保证花的钱没有白花。。
不同的agent,配合不同的模型,不用人为反复切换模型反复消耗token。
就像理发店里面有学徒、首席、总监,我们需要根据出活效果要求让不同的大模型干活。
可以简单分类:固定三类岗位:
跑腿:抽取、去重、改格式、拉清单 写作:出大纲、改稿、脚本化表达 攻坚:难题推理、关键决策、复杂排错
不同的agent只处理自己的上下文,保证上下文窗口信息有效,钱花在刀刃上。
尽量信息减少遗忘,保证花的钱没有白花。。
不同的agent,配合不同的模型,不用人为反复切换模型反复消耗token。
拿我自己的举例:
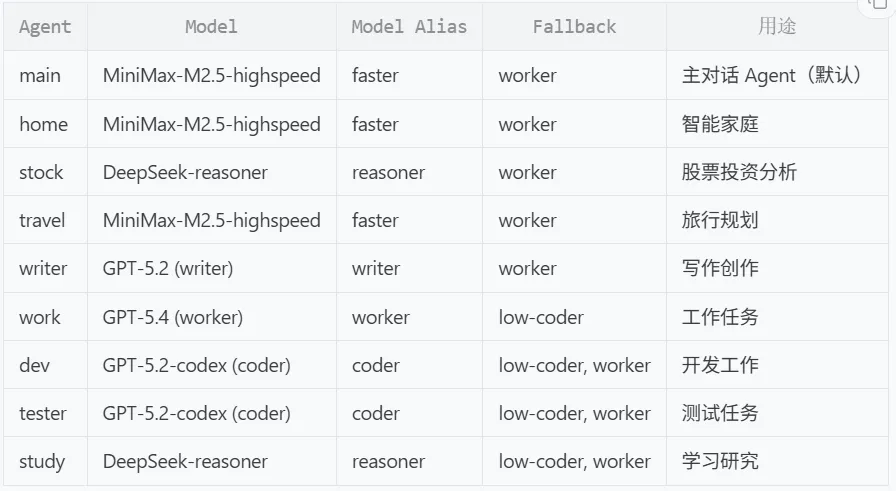
1.5 输入输出约束:约束自己,也约束模型
Chatgpt的时候,我更多是和大模型闲聊,用户输入的内容有限,我们各种办法增加prompt以提高效能。
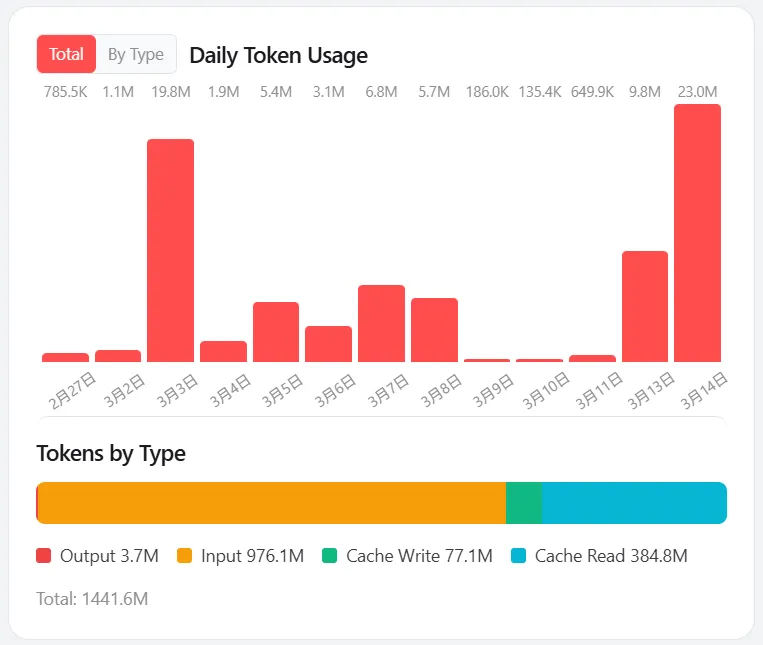
Openclaw prompt面临的是爆炸问题,看下面图,就能发现Prompt占据了费用支持出的99.9%。
所有省钱办法都只一个目的:更少的Input 更多的有效 Output.
老板话要少,你要活干好。
所有省钱办法都只一个目的:更少的Input 更多的有效 Output.
老板话要少,你要活干好。
一定要清楚表达自己的需求,这样干出来的活才会更符合预期。对很多人来讲,要自己把自己要什么先想清楚,我先聊聊再看这种想法就是在燃烧费用。
如果完全没有想法,建议用最便宜的模型,或者直接用chatgpt这种免费的。
想要让Openclaw少花钱,办大事,还是要遵守规则:
一次性把事情交代清楚,不要来回反复追问。
给Openclaw足够的授权,不要因为授权反复沟通。
增加对产出物定性、定量的描述,确保不要闲聊式输出。
明确什么是不要的,明确注意事项。
一次性把事情交代清楚,不要来回反复追问。
给Openclaw足够的授权,不要因为授权反复沟通。
增加对产出物定性、定量的描述,确保不要闲聊式输出。
明确什么是不要的,明确注意事项。
减少调用次数:少触发、少交互、少试错
2.1 少触发模型:能 slash 就别用文本
习惯了chatgpt什么都可以回答,我们总是直接把想法告诉Openclaw。
我们会Openclaw各种问题,“openclaw 当前状态",”你现在用的是什么模型“,”你...."。
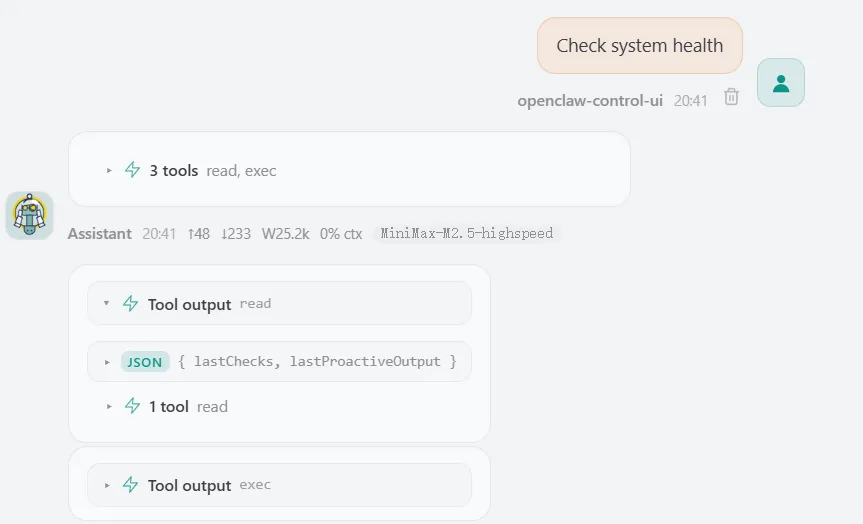
这个问题,openclaw会调用23次工具, Input: 23.4k tokens Output: 1.8k tokens。
但是openclaw 和 各种 channels 都有自己内置的 slash command, 可以在大模型解释之前就完成命令的执行。不调用大模型,自然不用有花费。
更多信息看这个:https://docs.openclaw.ai/tools/slash-commands
2.2 本地命令/bash
同/slash command , 在openclaw作为助手,对文件的操作管理,对操作系统管理也是高频操作。
这些很确定的工作,我们不希望也不需要 AI来花钱完成。
比如:
查文件: ls、cat、tree搜内容: grep、find、sed、awk、跑脚本: ./xxx.sh
# 直接执行,不经过 AI!ls -la ~/writer/# 用 grep 搜文件!grep -r "省钱" ~/writer/
如果让这些读写操作让AI进行,那么这些内容都会进入prompt,都会成为花钱才能看到的东西。
配置:你可以直接让openclaw给你配置。
//openclaw.json{"commands": {"bash": true //允许bash 命令},"tools": {"elevated": {"enabled": true, //允许提权"allowFrom": {"feishu": ["ou_xxx" //哪些飞书账号可用]}}}
// exec-approvals.json{"defaults": {"security": "full","ask": "off", //不问你要确认"askFallback": "full","autoAllowSkills": true},"agents": {"*": {"allowlist": [{"pattern": "/usr/bin/ls" //所有飞书用可执行}]"main": {"allowlist":["pattern": "/usr/bin/rm" //只有main agent能执行]}}}
2.3 Skill 包装:把日常需求变成流程(不追问少试错)
我们会有一些日常工作,第一次做的时候要花学习很长时间。
比如想通过家里里的音箱播放新闻摘要,有几件事要做:
查找新闻,生成播放的摘要(有字数、内容、风格要求等)找到可用的音响(网络搜索、接口识别、可用性测试等)生成音频文件(可用模型、内容位置、声音风格等)音乐传输播放(音量、接口调用等)
对于openclaw,它第一次面对这些问题的时候,很多信息需要和我们确认,设备也查找,各种信息需要与我们进行打合。这个过程是非常复杂,非常消耗token的过程。
当第一次成功完成这个动作之后,我们需要让openclaw记下设备配置,记下内容选择、记下我们喜好。
只要是有可能重复的操作,就让openclaw创建专用的skills, 下次再执行的时候skills会调用本的scripts来完成这个动作,只有项摘要生成这个行为还高度依赖于模型,至少可以节省80%的token消费。
这种场景非常常见,比如:
//常见场景访问共享文件 //大量的输入输出打印文件 //设备的管理使用本地数据库 //数据获取操作Excel/文本 //调用现有的专用工具完成管理下载工具 //调用接口,授权鉴权管理docker //健全与日常查询新闻收集 //重复动作
//创建SKILL过程你可以先和openclaw互动,让他自行学习。使用这些功能,如果不能成功就让他去官网学习后再尝试,直接成功。最后让openclaw根据刚才的过程,总结经验,创建新的SKILL即可。
举两个例子:
| 名称 | |
| 用途 | |
全屋播报、TTS播报、通过小爱音箱播报、通过回音壁播报 |
| 名称 | |
| 用途 | |
设备列表查询、在线状态、路由器管理、网络流量、异常检测、局域网扫描 |
| 名称 | |
| 用途 | |
场景 | Emby、MoviePilot、Nextcloud、Calibre-Web、Audiobookshelf、Pinchflat、Portainer 管理 |
将再次使用这些功能时,我们可以观察到大模型主要的参与是识别要使用哪个SKILL, 之后本地执行了,最后根据本地的输入摘要成结果。大模型的参与度极大地降低了Token的消耗。
2.4 Skill 减量:通用 Skill 5-10 个,不加载专业 Skill
创建SKILL太容易了,ClawHub市场中的SKILL快速到了22000+。
但就,但你真用的永远就那几个。
OpenClaw 读取的 Skills 路径:├── 1. ~/.npm-global/lib/node_modules/openclaw/skills/ (内置 Skills)├── 2. ~/.openclaw/skills/ (共享skills)└── 3. {workspaceDir}/skills/ (agent 专用skills)
做的三件事,都是为了省几个Token:
1. 不要动内置的Skill: 禁用不用的, 比如linux不能用mac的SKILL
2. 减少共享skill: 只放共用的比如clawlist, search, memory等
3. 明确专用Skill: 只有自己用的,或者对共享的skill进行了调整的
2.5 精简启动注入:系统提示词越长越贵
每个agent、subagent的session启动,都会读取agent的配置文件。
agent配置文件务必大幅简化。
建议除了USER.md和IDentity.md之外,都先清空,边用边补充。
可以让openclaw定期总结经验,自行补充,再做调整。
怎么样衡量文字减少了,Token影响有多大:
/context listAGENTS.md: OK | raw 0 chars (~0 tok) | injected 0 chars (~0 tok)SOUL.md: OK | raw 370 chars (~93 tok) | injected 370 chars (~93 tok)TOOLS.md: OK | raw 916 chars (~229 tok) | injected 916 chars (~229 tok)IDENTITY.md: OK | raw 298 chars (~75 tok) | injected 298 chars (~75 tok)USER.md: OK | raw 351 chars (~88 tok) | injected 351 chars (~88 tok)HEARTBEAT.md: OK | raw 167 chars (~42 tok) | injected 167 chars (~42 tok)BOOTSTRAP.md: OK | raw 0 chars (~0 tok) | injected 0 chars (~0 tok)MEMORY.md: OK | raw 979 chars (~245 tok) | injected 979 chars (~245 tok)
Tips:
1. IDENTITY.md:直接找与这个agent定位最一致的名人。
2. USER.md : 对你甲方爸爸的描述,不需要任何情绪化的描述。
写完之后让openclaw再给你优化一次,删除那些没有用的干扰。
2.6 利用引用,提高 Cache 命中,减少费用
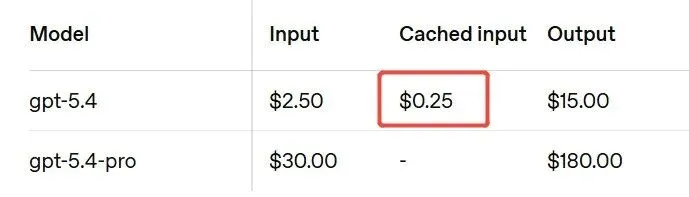
Cached Input 的 价格是 Input 价格的10%, 能提高Cache命中率就能大幅减少成本。
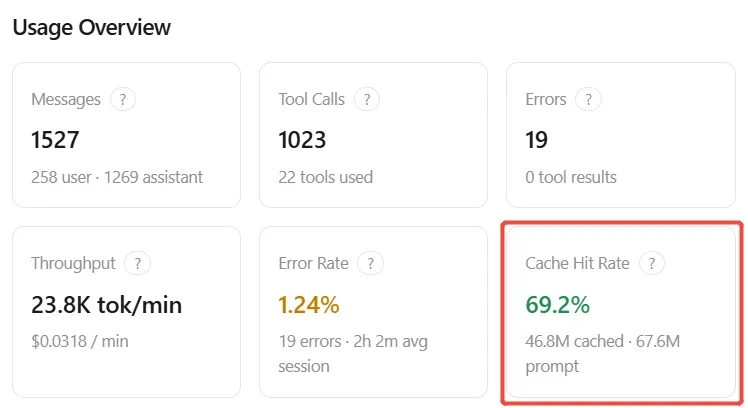
统计信息来看,目前的近70%的cache命中率。说明两个问题:
1. openclaw真的大量重复的prompt输入 :-(
2. 目前的重复输入,大多都触发了cache :-)
70%的命中率是非常高的水平, 如何提高 Cached hit Rate?
1. 每个不同的话题,用不同的session。
2. 利用subagent, threadSession。
3. 裁剪不需要的上下文。
核心就是contextWindow的说明。
上下文窗口管理:让每次交互更便宜
上面我们关注的是如何减少交互来减少Token。
而上下文窗口管理(contextWindow)则聚焦在每一次交互如何减少费用。
影响上下文窗口的有模型、全局的agent配置、单一agent/session配置。
模型可配置项
{ id: 'MiniMax-M2.5-highspeed', name: 'faster', api: 'anthropic-messages', reasoning: true, // 是否支持 thinking input: [ // 支持的输入类型 'text', ], cost: { // 价格配置 input: 4.2, output: 16.8, cacheRead: 0.21, cacheWrite: 2.625, }, "contextWindow": 200000, // 模型上下文上限 "maxTokens": 32768, // 模型输出上限 }
{id: 'MiniMax-M2.5-highspeed',name: 'faster',api: 'anthropic-messages',reasoning: true, // 是否支持 thinkinginput: [ // 支持的输入类型'text',],cost: { // 价格配置input: 4.2,output: 16.8,cacheRead: 0.21,cacheWrite: 2.625,},"contextWindow": 200000, // 模型上下文上限"maxTokens": 32768, // 模型输出上限}
2.8 contextWindow:输入上限,别一次喂太多
模型硬限制,是指模型本身支持的最大上下文 tokens 数。
配置文件中只是声明。
设置低有作用,设置高无意义。
如果真的输入大于模型的contextWindow会报错。
2.9 maxTokens:设输出上限,别让模型写没完
模型硬限制,输出限制,单次回复最大生成 tokens 数。
从输入输出的比例,就可以看出输出的难度。
Agent全局参数
Agent全局参数
这些参数无法针对某一个agent进行修改。
agents: {defaults: {models: {bootstrapMaxChars: 20000,bootstrapTotalMaxChars: 150000,contextTokens: 200000,contextPruning: { //定期清理工具输出,释放空间mode: 'cache-ttl', //工具输出缓存超时清理ttl: '30m', //工具输出保留30分钟后移除tools: {allow: [ //只有这两个工具的输出会被缓存'exec','read',],},},compaction: {mode: 'safeguard',reserveTokensFloor: 30000,memoryFlush: { //接近阈值时强制刷出内存到文件enabled: true,softThresholdTokens: 10000,},}thinkingDefault: 'medium', //low:~4k medium:~8k tokenverboseDefault: 'off', //on 工具输出占用token}}}
如何查看当前加载的所有的内容对上下文的影响:
/context detailoutput:Bootstrap max/file: 20,000 charsBootstrap max/total: 150,000 charsSystem prompt (run): 47,639 chars (11,910 tok) (Project Context 16,254 chars (4,064 tok))Injected workspace files:- AGENTS.md: OK | raw 505 chars (127 tok) | injected 505 chars (127 tok)Skills list (system prompt text): 18,003 chars (4,501 tok) (50 skills)Tool list (system prompt text): 3,771 chars (943 tok)Session tokens (cached): 105,097 total / ctx=200000
| 初始加载 | ||
| 上限 | ||
| 清理 | ||
| 保护 | ||
| 触发压缩 | ||
| 动态开销 |
2.10 如可计算可用的会话空间
可用会话空间 = min(contextTokens, contextWindow)- bootstrapCharsTotal_token //启动被占用 12k- skill + tools + 实际已使用- softThresholdTokens //压缩触发阈值- reserveTokensFloor //预留占用- thinking_tokens //4-8k- verbose_tools_tokens //按实际
2.11 bootstrapTotalMaxChars
BOOTSTRAP.md文件在会话启动时一次性加载,占用初始上下文空间。AGENTS.md 等文件受 bootstrapTotalMaxChars 限制。
2.12 contextPruning:裁掉无关历史,但别裁掉重点
主是针对工作使用过程中的输入输出内容的清理。
这部分内容实际占比非常高,要在会话完成后尽快处理。
基本都是search、cat、find、ls等产生的过程信息。
如果没有长时间任各,可以尽一步缩短ttl的时间限制。
2.13 compaction 自动压缩上下文:把旧对话浓缩成摘要
compactoin主要针对人就实际会话过程的内容。
该过程是自动化的,会有提示告诉。如果压缩在同一任务过程反复发生,说明:
1. min(contextTokens, contextWindow)太小了。
2. reserveTokensFloor + softThresholdTokens太大了。
需要注意 /compact 是一个slash command,可以手动执行的。
2.14 skills.entries:不常用就关
禁用skills:
// ~/.openclaw/openclaw.json"skills": {"entries": {"apple-notes": { "enabled": false },"model-usage": { "enabled": false }}}
迁移skill到特定agent:
//迁移专用skills 到 agent workDir skills 目录。!mv .openclaw/skills/{skillname} {workDir}/skills/
2.15 thinkingDefault:默认别“想太多”
提示:v2026.3.8 之前参数只有off, low, medium, high
目前的版本增加了:minimal, adaptive,要不试试adaptive。
还是期望可以针对agent设置独立的thinking模式。
/thinking adaptive 也是slash command, 可以在任可agent里面手动调整当前思考模式。
Agent会话级参数
会话生命周期管理, 15天没有访问过的会话可以清理掉,对话超过500条掉消息被截断。每天4点会对会话重置,8 小时无操作当前会话历史清空。
"session": { "dmScope": "per-account-channel-peer", //尽可能细化的session "reset": { "mode": "daily", "atHour": 4, //每天4点清理 "idleMinutes": 480 //8小时未活跃 }, "maintenance": { "mode": "warn", "pruneAfter": "15d", //标记为可清理 "maxEntries": 500, //500条对话的会话 "rotateBytes": "50mb" } }
清理方式差异对比:
术语 含义 作用对象 数据状态 清理 (prune) 删除会话记录 历史会话文件 从磁盘删除 清空 (reset) 删除对话历史 当前会话内存 内存释放 懒清空 (idle reset) 闲置后清空 当前会话内存 空闲超时触发 截断 (truncate) 删除部分旧消息 当前会话内容 保留最新500条
2.16 /new & /reset:手动切换上下文
Agent会话级参数
会话生命周期管理, 15天没有访问过的会话可以清理掉,对话超过500条掉消息被截断。每天4点会对会话重置,8 小时无操作当前会话历史清空。
"session": {"dmScope": "per-account-channel-peer", //尽可能细化的session"reset": {"mode": "daily","atHour": 4, //每天4点清理"idleMinutes": 480 //8小时未活跃},"maintenance": {"mode": "warn","pruneAfter": "15d", //标记为可清理"maxEntries": 500, //500条对话的会话"rotateBytes": "50mb"}}
清理方式差异对比:
| 清理 (prune) | |||
| 清空 (reset) | |||
| 懒清空 (idle reset) | |||
| 截断 (truncate) |
2.16 /new & /reset:手动切换上下文
与系统配置对应的手动清理会话的方法:
/new 保存当前会话到磁盘,重新创建新的会话,重新加载system prompt/reset 删除当前会话内容,只保留system prompt/session 当前会话/sessions_list 查看当前agent所有的会话
在一个agent里面,一个项目或者一个主题结束切换时,可以/new构建一个清的干净会话。
reset也支持按类型重置,比如按群、私聊、会话来进行重置。
如果只是一个家庭使用,为了保持会话的连续,不建议自动清除,手动维护就好。
"resetByType": {"direct": { "mode": "idle", "idleMinutes": 480 }, // 私聊 8小时idle清理"dm": { "mode": "daily", "atHour": 4 }, // DM 每天4点清理"group": { "mode": "idle", "idleMinutes": 120 }, // 群聊 2小时idle清理"thread": { "enabled": false } // 线程不清理}
2.17 subagent 减少上下文
依然是基于专业的从专业的人做专业的事的角度,请subagent基于当前的workspace,创建新的session会话来处理任务。减少干扰,保持聚焦。
2.18 去掉 typingIndicator 和 reaction
去掉 typingIndicator:别让系统“多动一下”
// ~/.openclaw/openclaw.json"channels": {"feishu": {"typingIndicator": false, //减少交互"threadSession": true,"footer": { "elapsed": true }}}
关掉后台自动化:别让钱花在看不见的地方
2.19 heartbeat:不用就关/降频,别后台叫你
为每一个agent设置heartbeat, 更需要调整频率。
// ~/.openclaw/openclaw.json{ "id": "main", "heartbeat": { "every": "6h" } }
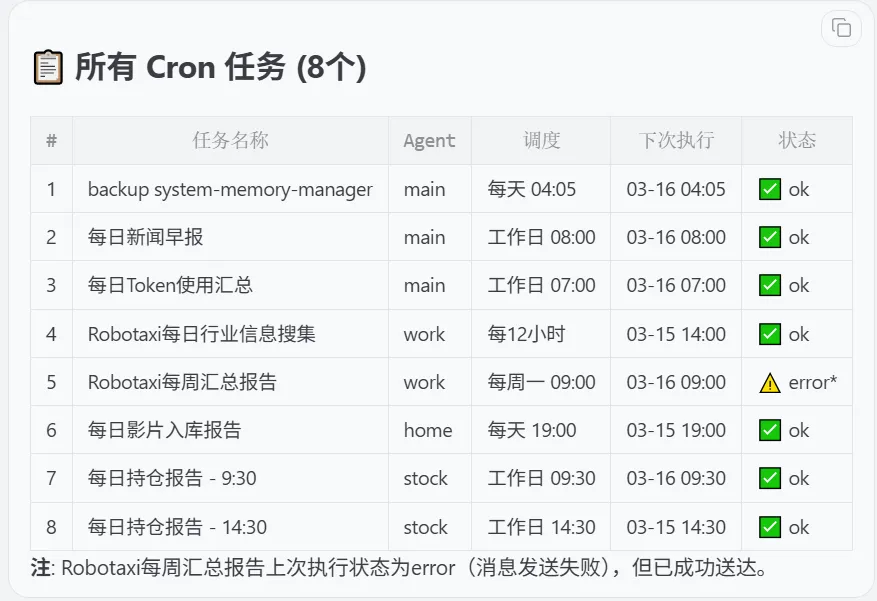
2.20 cron:关掉之后,可以按需手动跑
定时任务对资源的消耗其实也很大,没有必要的可以关掉。
尽量让cron行为脚本化,skill化。
指定特定模型运行cron任务。
定时任务对资源的消耗其实也很大,没有必要的可以关掉。
尽量让cron行为脚本化,skill化。
指定特定模型运行cron任务。
2.21 self-improvement:等系统更新
让这些功能只跑在包月套餐里面。
所有的改动必须要经过同意,很容易崩溃。
2.22 proactive-solvr:减少主动性
主动性越强,token;没明确收益就先收着。
小龙虾们,聊“省”,影响了一些体验。
下次聊一下“快”。
