 夜雨聆风
夜雨聆风实践周期:2026年3月13日(周五)— 3月15日(周日)硬件配置:十多年前的旧笔记本、4GB内存、集成显卡目标:零成本本地部署OpenClaw +本地大模型,跑通完全免费的调用流程
一、目的:我为什么要做这件事?
这次实践的起因是我对OpenClaw一直有了解的兴趣,但需求不强,迟迟没有动手。周末突然起心动念,想试一下本地部署加本地大模型调用,验证"完全免费"的本地AI工作流是否可行,同时通过动手实践理解OpenClaw的原理和工作过程。为了避免风险,我特意选了台旧电脑。
我的预期目标是:
l把旧电脑改成轻量级Linux系统(Lubuntu)
l用Ollama部署本地大模型
l安装OpenClaw并连接本地模型
l实现完全免费的AI调用流程
二、过程:十几个小时的技术马拉松
第一阶段:系统改造(周五晚—周六早上)
原计划:硬盘安装或WinPE启动安装Lubuntu
实际遭遇:
l硬盘安装失败
lWinPE调用镜像失败
l不想格式化原有U盘,最后在京东买了新U盘(周六早上送到)
结果:周六早上终于装好Lubuntu,但已经消耗了不少时间精力,好在白天天气不错,进行了不错的户外活动。
第二阶段:Ollama部署(周六晚—周日上午)
原计划:官网一键安装现实:官网Linux安装脚本下载速度极慢,估算需要几十个小时
我的应对:
l找国内镜像(都失效了)
l挂官网链接通宵下载(周日早上发现只完成30%)
l最后在论坛找到离线安装包
结果:周日上午Ollama终于装好,但时间成本已经远超预期。
第三阶段:模型选择与测试(周日上午—下午)
第一轮:Phi3:mini
l安装成功,本地对话速度极慢
第二轮:Qwen2.5-0.5B
l下载顺利,本地测试速度还可以
但连接OpenClaw时报错:token数低于最小要求
排查过程:
l尝试扩大模型token限制(多次尝试,新建多个模型)
l尝试降低OpenClaw最小token要求(修改本地参数)
结果:都失败,还是报同样的错误
第三轮:DeepSeek-R1-1B
l本地跑通了
l连接OpenClaw时出现接口调用错误
重置后再尝试:
l完全重置OpenClaw参数
l换用Llama3.2-1B
终于连接成功,但速度极慢,一个字吐不出
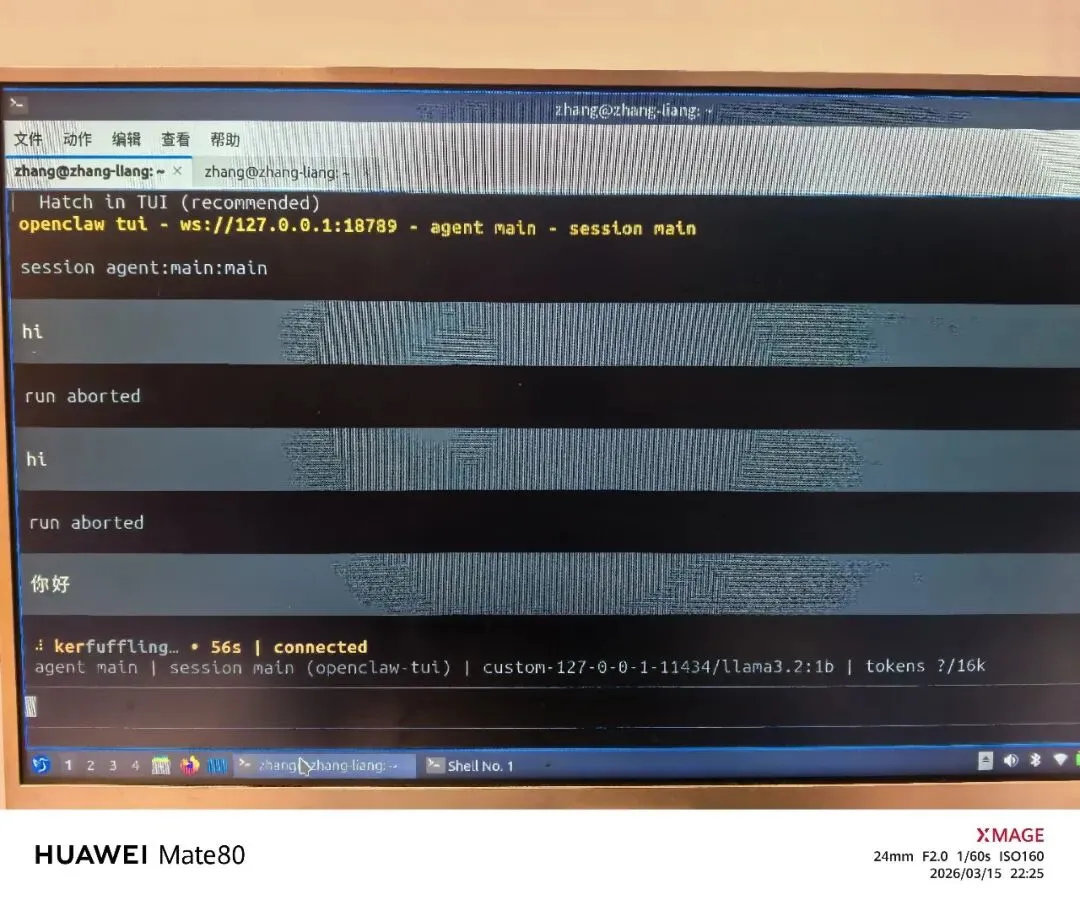
OpenClaw连接调用本地Llama3.2-1B成功,但响应很慢直接超时
第四轮:回到Qwen2.5
l这次没报token超限制,连接成功
l同样一个字吐不出
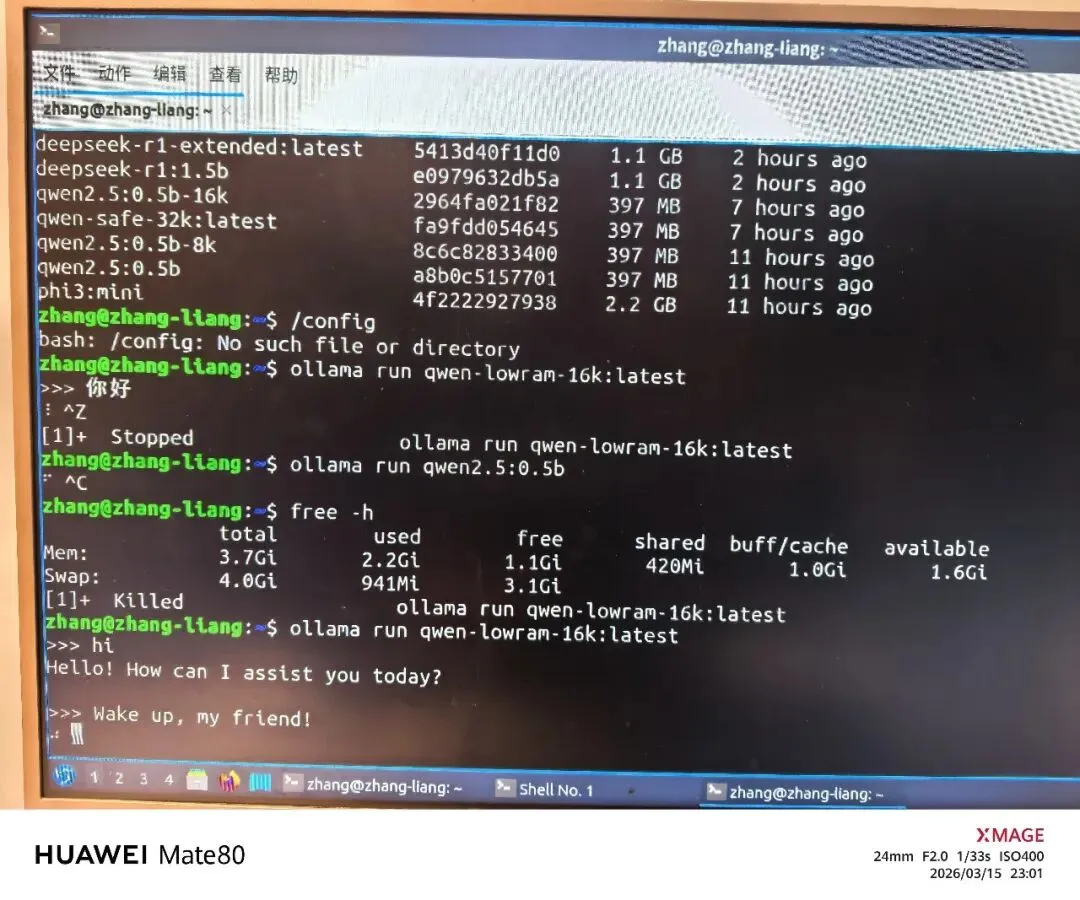
OpenClaw调用本地Qwen2.5简化版本也是一个字吐不出,Ollama本地直接运行大模型响应相比之前也变慢很多(内存占用,SWAP太多)
周日结果:十几个小时投入,目标没达成,挫败感很强,还影响了正常活动计划。
三、反思:我哪里出了问题?
1. 硬件选择的根本性误判
这是最致命的问题。我后来查到,OpenClaw官方列出的"4GB RAM最低要求"只适用于网关模式(连接外部API),本地大模型模式实际需要16GB起步,32GB推荐。
4GB内存面对本地LLM推理存在物理层面的不可行性:
l即使是7B参数模型,量化后也需要4-6GB内存
l加上系统、Ollama运行时、上下文缓存,4GB必然触发频繁的磁盘交换
l集成显卡没有独立显存,无法分担内存压力
"一个字吐不出"的本质:系统内存耗尽,被迫用硬盘当虚拟内存,推理速度从秒级降到分钟级甚至完全卡住。
反思:我一开始"把需求扔给三个AI",AI们都建议精简版Ubuntu——这个建议本身没错,但所有方案都回避了核心问题:4GB内存对于本地LLM推理根本不够。AI们给了"技术上可行"的方案,但没告诉我"体验上不可接受"的现实。
2. "免费"的成本陷阱
这次实践完美诠释了"免费才是最贵的":
成本类型 | 我的实际支出 |
时间成本 | 约15+小时 |
硬件成本 | 新U盘(京东购买) |
精力成本 | 高强度调试导致的身心疲惫 |
机会成本 | 影响正常活动计划 |
如果换算成时薪,这些时间的价值可能远超一年的云API订阅费用。OpenClaw的VPS部署方案每月才$24,更别说国内大模型的性价比,而我的15小时按最低时薪算也超过这个数字了。
3. 沉没成本谬误
复盘整个过程,我至少有三个应该放弃的节点:
第一个节点:周五晚安装系统失败时硬盘安装失败→WinPE失败→需要买新U盘。这时候应该意识到硬件兼容性问题比预期复杂,考虑是否值得继续。
第二个节点:周六晚Ollama下载极慢时"几十个小时"的下载估算本应触发警觉:这个硬件环境是否适合运行现代AI基础设施?这时候转向云端API方案可能是更理性的选择。
第三个节点:周日早token报错反复无法解决时当我"把报错信息扔给多个AI"并尝试两种方案都失败后,应该意识到这并非配置问题,而是架构层面的不匹配。这时候应彻底放弃本地模型路线,而非继续尝试更大模型。
"坚持之后又没有成功"的挫败感,很大程度上源于我违背了"快速失败"原则。在错误的道路上走得越远,挫败感越强。
4. 目标与手段的混淆
我的原始目标是"了解OpenClaw的原理和工作过程"。这个目标完全可以通过更低成本的方式实现:
l在主力机上用Docker快速部署
l直接连接云端API观察工作机制
l阅读文档和源码或者观看视频
但我选择了最困难的路径:旧电脑+本地模型+完全免费。这个路径叠加了三个高复杂度因素,导致目标被手段绑架。
四、收获与总结:这次实践教会了我什么?
1. 技术认知的深化
尽管目标没达成,但是对大模型和Openclaw本地部署及以下概念有了实践性的理解:
l内存墙:本地LLM推理的核心瓶颈永远是RAM/VRAM
l量化:用精度换内存的实际意义
l上下文窗口:token限制的本质是内存分配
lSwap的致命性:磁盘交换对交互式应用的毁灭性影响
这些认知未来在做技术选型时,会让我本能地先检查硬件规格是否匹配软件需求。
2. 决策框架的优化
这次实践后,我建立了以下前置评估清单:
评估维度 | 关键问题 |
硬件边界 | 物理规格是否满足软件的推荐配置(而非最低配置)? |
时间预算 | 预估投入时间是否超过购买现成服务的成本? |
退出机制 | 设定明确的"放弃节点",避免沉没成本累积 |
目标纯度 | 区分"学习技术"和"证明可行性" |
3. 对"免费"的重新理解
真正的免费不是零支出,而是成本的可控与可转移:
l可控:云服务成本是线性、可预测的;DIY成本是长尾、可能爆发的
l可转移:时间可以转化为金钱,但健康、情绪、关系难以量化
对于旧硬件的利用,更理性的策略是:
l4GB RAM旧电脑:适合作为OpenClaw网关(连接外部API),或纯文件服务器,不适合本地LLM
l本地LLM实验:至少需要16GB RAM起步
4. 对AI建议的批判性审视
这次实践暴露了AI建议的局限性:
lAI倾向于给出"技术上可行"的方案,而非"体验上最优"的方案
lAI会迎合用户的约束条件,而非挑战这些约束的合理性
l多AI共识不等于正确——三个AI都建议精简Ubuntu,但没人质疑4GB内存的根本不足
未来使用AI辅助技术决策时,我或许会主动追问:
"这个方案的推荐配置是什么?最低配置下的实际体验如何?"
"如果硬件不足,有哪些降级的替代方案?"
"这个任务的时间成本预估是多少?"
5. 家庭支持的珍贵
复盘最后必须提到:幸亏家人很理解我,同时还保证了我的正常睡眠和饮食。技术探索的挫败感往往会被亲密关系缓冲,这是比任何技术成果都更重要的收获。
结语:下一次,我会怎么做?
如果重来一次,面对"4GB旧电脑+OpenClaw+本地模型"的需求,回归理性,可能选择:
方案A(学习目标优先):放弃旧电脑,直接在主力机用Docker部署OpenClaw+Ollama,快速验证流程后再考虑是否需要在特定硬件上复现。
方案B(零成本优先):旧电脑装Lubuntu后,部署OpenClaw但只连接免费/低价的云端API,不碰本地模型。
方案C(本地模型优先):承认4GB内存不足,先升级硬件,再启动项目。
最得不偿失的,就是我这次实践的路径——在捉襟见肘的硬件上,用低效的方式,追求一个被执念绑架的目标。
这次"失败"的价值,在于让我建立了对技术边界、成本计算、决策时机的深刻体感。这些隐性知识,往往只能通过真实的踩坑获得。十几个小时没有换来一个完全跑通的系统,但换来了一套未来可以复用的决策框架——这或许是这次实践真正的收获。
这次实践,我着相于"免费"之相,住于"坚持"之执,如那游戏《黑神话悟空》中追逐虚妄的精怪,在错误的路上越走越远;破此相、离此住,方知器有边界,执念成障,放下亦是修行。
(本文经AI辅助完成,但所有实践、反思与决策均源于亲身经历)
