 夜雨聆风
夜雨聆风英伟达GTC2026核心技术全景:Vera Rubin、NemoClaw与Groq的革命性协同
每一次GTC大会,都是英伟达改写科技格局的时刻。2026年的圣何塞,会场灯光亮起的那一刻,整个产业几乎同时意识到:AI计算正进入一个全新的时代——从“芯片竞赛”转向“智能体系统”的全面整合。这不仅仅是一场硬件更新,更是生态重塑的宣言。
这篇文章将以功能盘点的视角,带你系统拆解英伟达三项关键技术:Vera Rubin超级计算平台、NemoClaw企业AI操作系统、以及Groq LPU高带宽推理芯片协同机制。在这些创新的背后,隐藏的是一条清晰的主线——AI正在成为一场由算力驱动的数据工业革命。
Vera Rubin —— 七芯合体的AI超级计算平台
英伟达的新旗舰Vera Rubin,被称作“七芯合体的智能体引擎”。它并不是单一GPU的代际升级,而是一整套协同平台,由Rubin GPU、Vera CPU、NVLink 6交换机、ConnectX-9 SuperNIC、BlueField-4 DPU、Spectrum-6交换机以及Groq LPU七个核心模块组成。每一个组件都在为一个共同目标服务——构建智能体系统的端到端算力平台。
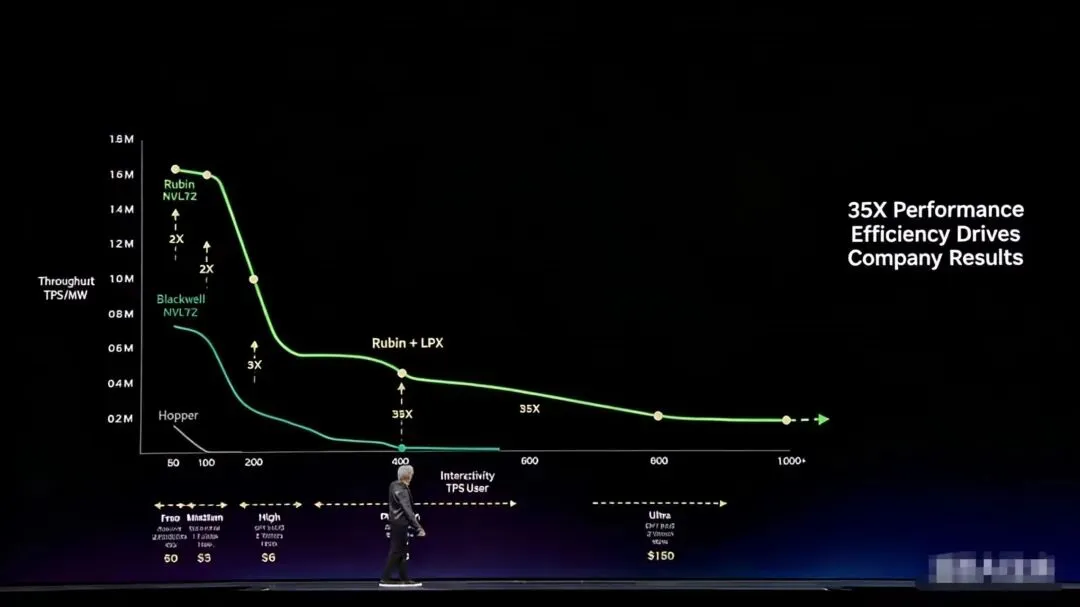
Rubin的性能跃升尤为惊人:在同等功耗下,推理性能提升达35倍,系统冷却和安装速度翻倍,而能耗压力几乎被完全转化为计算能力。采用100%液冷与CPO(共封装光学)技术,让传统铜缆通信成为过去,算力密度达到了前所未有的水平。
更值得关注的,是Rubin所体现出的“算力工厂”理念。在这个体系中,数据中心不再只是模型训练的场所,而是大规模Token生产线。电力被视为产能上限,每一个Token都是新的“数字产品”。Rubin不仅提供了计算效率上的飞跃,更提供了一种全新的工业模型——算力即数据。
在结构设计上,Rubin Ultra的Kyber机架让GPU垂直插入、冷却、通信实现完全整合。这种模块化构造,使得计算能力如同工业装配线般可扩展。配合CPO光学互联,Rubin成为真正意义上的“能源到算法”的转换装置,为未来AI工厂提供物理基础。
展望未来,Rubin已经确定了极为稳定的节奏:从Blackwell到Feynman,每年迭代一次,推理性能提升3-5倍。这样的节奏意味着AI算力的升级将像智能手机更新一样常态化——而资本投入与基础设施周期,也将因此彻底改写。

NemoClaw —— 企业AI操作系统的安全中枢
NemoClaw的诞生,让AI在企业场景的应用进入了可控、安全且高效的时代。这一系统本质上是英伟达打造的企业级AI操作系统,能够让智能体(Agent)在本地安全地运行、协作和接入云端资源。
其运行核心包括三个部分:OpenShell运行时、策略沙箱引擎、以及Nemotron模型集成。安装一条命令即可将其嵌入企业软硬件生态,自动部署安全策略和沙箱,确保Agent在执行代码和访问文件时不会危及内网安全。同时,NemoClaw内置英伟达自研的Nemotron模型,充当企业本地AI“大脑”。本地模型用于常规任务;需要更高算力时,则通过隐私路由调用云端模型,形成安全、高效的双脑结构。
从商业逻辑上看,NemoClaw正在推动服务模式的根本转变。过去的SaaS公司卖工具,现在的GaaS(Agentic as a Service)公司出租“能干活的智能体”。这种范式变化,意味着每家企业都将拥有自己的AI员工,而NemoClaw就是它们的工作环境。
NemoClaw的创新在于,它不是简单地管控安全,而是实现了智能自治与安全合规的融合。策略引擎能持续学习行为模式,对异常调用自动隔离;沙箱机制让企业可以放心让AI执行文件读写、网络通信等操作,而不必担心泄密风险。英伟达将企业信息安全变成AI生态的一部分,使得自主Agent真正能“干活”,而不只是展示。
更深层的影响,在于资源调度逻辑的重构。Nemotron模型的双脑机制让推理任务可以自动选择执行路径——例如高价值任务走云端大模型,低频任务留在本地。这让企业AI的资源管理变得像能源控制一样精确。未来,AI预算甚至可能像电力预算一样可量化。

Groq LPU —— 推理加速的“神经共生芯片”
Groq LPU可被视为Rubin体系中最具突破性的环节。它彻底改变了AI推理的架构思维,从动态调度转向确定性数据流结构。与GPU不同,LPU每一步计算都由编译器静态调度,不存在执行的不确定性。这种确定性架构让AI推理变成可预测的工业流程——每个token的生成被“编排”,不是“随机”。
LPU的片上带宽高达150TB/s,是Rubin GPU的七倍,而SRAM容量仅有后者的五百分之一。看似微小的芯片,却拥有极快的执行响应,使其天生成为低延迟任务的理想载体。通过Dynamo软件,英伟达将推理流程一分为二:前期预填充与注意力计算留在GPU完成;而最终token生成,则由Groq LPU处理。这种双芯分工让延迟减半、性能激增——尤其在超高速推理任务中,达到了35倍的性能提升。
这不只是技术巧思,而是产业逻辑的转变。Groq与Rubin的协同,为AI数据中心带来了异构算力经济模型。企业可以根据工作负载(训练、批量推理、token生成)灵活分配资源。例如,将25%的算力分配给Groq进行高价值编码类任务,可大幅提升效率和收益率。这样的分配机制,让算力成为企业可配置的资本资产。
更有意思的是,这种协同关系正在量产化。每个LPX机架可部署256颗Groq LPU,并通过640TB/s的架构扩展带宽实现模块级水平扩展。当Rubin的GPU算力与Groq的低延迟配合到位,AI推理体系的容量几乎呈指数级增长。算力不再是堆砌出来的,而是通过智能编排实现的。

Physical AI —— 从虚拟智能到具身智能的新跃迁
AI不仅在屏幕里演算,也开始在真实世界中行走。英伟达的Physical AI战略,让智能从虚拟认知正式进入物理存在阶段。现场展示的迪士尼Olaf机器人是最好的例证:它内置Jetson芯片,运行在Omniverse物理仿真环境里,通过Newton引擎和强化学习,学会了走路、感知地形、与人互动。
这一领域的关键不只是算法,而是数据。物理世界的训练数据永远有限,英伟达推出的Cosmos世界模型成为解决逻辑。Cosmos可以将有限的真实数据扩展成合成数据集,补齐那些在现实世界中难以生成的极端场景。算力足够强,就能把训练数据当作可再生资源。
这意味着人工智能的学习将不再被“现实数据”约束。AI可以在虚拟空间形成完备的应变体系,然后迁移至现实机器人。Rubin提供算力,Omniverse提供仿真场景,Jetson提供执行能力,三者组合构成具身智能的技术闭环。英伟达实际上在构建下一代“AI制造工厂”——生产的不再是芯片,而是可以理解世界的机器。
随着自动驾驶、工业制造、交互娱乐的持续融合,Physical AI正成为连接虚拟与现实的桥梁。它不仅改变人机交互方式,更重塑了生产力边界:AI不再只是算法工具,而是具备行动力的劳动力。
AI的版图正在被重新绘制。英伟达通过Vera Rubin提供了硬件上限,通过NemoClaw建立了安全生态,通过Groq LPU打通了推理瓶颈,再结合Physical AI的具身化探索,定义了下一轮智能产业的基础逻辑。
这是一个垂直整合、水平开放的系统,从算法到芯片到数据中心形成了完整闭环。当每一家SaaS公司都转型为GaaS公司,每一个工程师都拥有自己的Token预算时,AI的产业边界也将随之扩展。下一阶段的竞争,不再是模型规模之争,而是生态耦合与智能体系的速度之战。
英伟达的新版图不只是技术故事,更是下一次工业革命的起点。未来的数据中心,将成为智能体的孵化工厂——每一点算力,都是一种新的生产力。
AI 时代到来,要个体的能力加强,在自媒体时代下用 AI + 副业要这一切变得 。在当下最好发展一份属于自己的副业 AI + 行业做副业 已经有 3700名小伙伴加入了,如果你也想着在 AI 时代拥有一份属于自己的 AI 欢迎加入加入吧!这是一个赚钱训练营,AI 技能训练营密集的圈子,你可以每年参加各种副业赚钱训练营。 weixin; wolongjun2018 备注 AI
