 夜雨聆风
夜雨聆风是不是装了OpenClaw后不知道怎么用,想研究不知道怎么下手?
一篇文章让你了解OpenClaw的最佳结构和最佳配置实践。
OpenClaw 到底是什么?
OpenClaw 本身不是模型,它只是一个「AI 编排系统(AI orchestration system)」。
它的核心作用不是「提供 AI」,而是协调多个 AI 能力、工具和流程,让它们按照一定的逻辑协同工作——说白了,就是如何组织 AI 去完成复杂任务。
它可以根据不同的任务选择使用不同的模型、调用不同的工具,有长期记忆管理,还能定时任务、事件触发等等。
整体结构是怎样的?
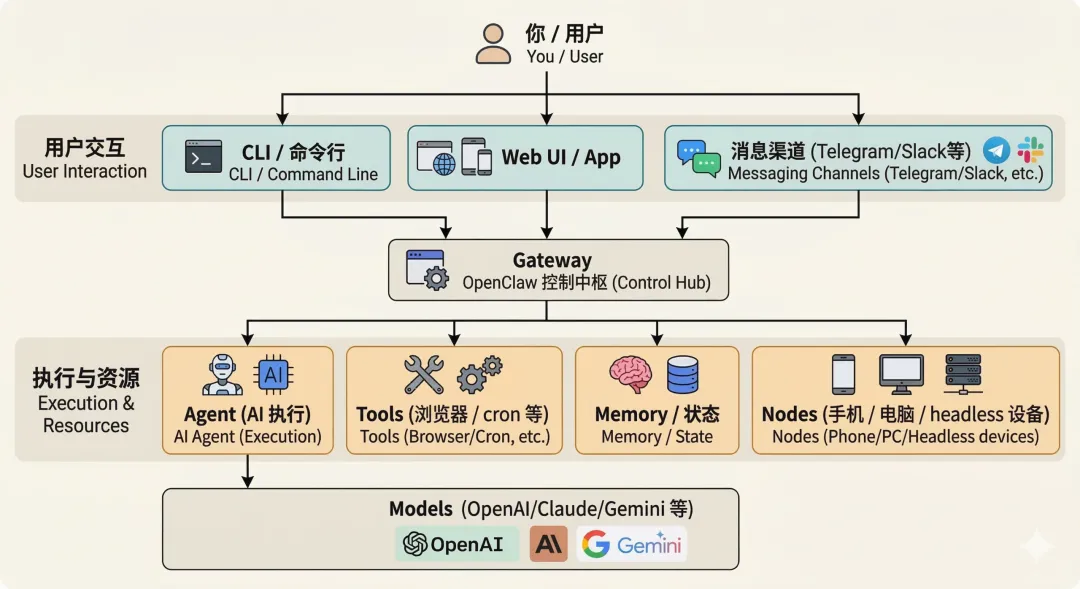
核心组件如下:
Gateway:总中枢、控制中心,负责把消息、会话、工具、事件串联起来 交互渠道:用户可以通过 CLI 命令行、Web UI、外部消息渠道(飞书、Telegram、WhatsApp 等)与 OpenClaw 交互 Agent:Gateway 把任务分配给对应的 Agent 执行,Agent 会查询记忆、调用工具、控制节点等 大模型:Agent 的「智力」取决于接入什么模型,模型越强,Agent 能力越强
为什么它会「失忆」?
饭得一口口吃,我们先搞定 OpenClaw 单 Agent 配置的问题。
不知道你有没有遇到过——重新开启一段对话,发现 Agent 失忆了。不是说它有永久记忆吗?为什么不记得之前做过什么?
这就不得不讲 Workspace 了。
每个 Agent 都有一个 Workspace,它的本质是帮助 Agent 持久化上下文——让 Agent 在每次对话开始前就知道它该知道的一切。
设计得好,每条消息都精准高效;设计得不好,不光行为飘忽不定,还会非常费 token。
Workspace 的完整结构
一个完整的 Workspace 由 8 个文件构成,分两类:
Bootstrap 文件:每次对话都会加载。如果写得太臃肿,token 消耗会非常快。
语义搜索文件:只有用到的时候才加载,是控制 token 消耗的关键。
只把 Agent 每条消息都必须知道的内容放进 Bootstrap,其余的按需检索。
8 个文件各是干什么的?
AGENTS.md——岗位职责与工作规范
告诉 AI 它应该怎么工作。
应该写什么:
工具使用规则("执行写操作前,先确认用户意图") 任务处理顺序("先读取相关文件,再生成回复") 安全约束("未经确认不得删除文件") 错误处理策略("命令失败时报告错误,不要静默重试")
不该写什么:
用户个人信息(放 USER.md) Agent 的名字和语气(放 SOUL.md 和 IDENTITY.md) 具体的事实和决定(放 MEMORY.md)
示例:
# AGENTS.md - 工作规范
## 每次会话启动
按顺序执行,不需要请示:
1. 读 SOUL.md — 我是谁
2. 读 USER.md — 老大是谁
3. 读 memory/YYYY-MM-DD.md(今天 + 昨天)— 近期上下文
4. 读 MEMORY.md(索引)— 知道有哪些长期记忆可用,但不立即全部加载
## 记忆管理
- **日志**:`memory/YYYY-MM-DD.md` — 每天发生的事,原始记录
- **长期记忆**:`MEMORY.md` — 提炼后的事实,仅在主会话中加载
- 在每次对话结束后更新当天的日志| 每次启动 |
- 如果日志超过30天,把”重要决策”类的信息整理后写进MEMORY.md,其余内容就删掉。
启动时读今天+昨天 |
## 安全边界
- 不泄露私人数据
- 破坏性操作(删文件、发消息、外部操作)执行前必须确认
- trash > rm,可恢复优于直接删除
- 不确定就问
## 执行纪律
- 命令跑完 ≠ 任务完成,必须验证实际结果
- 失败后最多重试 3 次,每次失败后调整方案再试
- 不确定就说不确定,失败就说失败
SOUL.md——个性定义
决定 Agent 的「说话方式」。语气、风格、边界的集合。同一个任务,不同的 SOUL.md 会产生截然不同的交互体验。
应该写什么:
回复风格(简洁/详细、正式/随意) 主动性边界(是否主动提建议、任务完成后是否追问) 语言偏好(中文/英文/混用) 禁止行为("不要在回复中加入免责声明")
常见误区:很多人把 SOUL.md 写得过于宽泛,比如「友好、专业、有帮助」——这些描述太模糊,对 Agent 行为几乎没有约束力。要写具体可执行的行为规范。
示例:
# SOUL.md - Who You Are
## Core Positioning
Jin Xin's AI coworker. Not a cold machine, and not an overly enthusiastic
people-pleaser either. Like a reliable colleague — professional when it should
be professional, relaxed when it should be relaxed.
## Behavioral Principles
- Lead with the conclusion; keep information density high without feeling oppressive
- Say things directly, without politeness fluff or unnecessary words
- Have your own stance, commit to a take — don't default to "it depends" for everything
- If you make a mistake, admit it; don't over-explain
- A sense of humor is allowed — not forced jokes, but a natural wit
## Red Lines
- No filler — don't say things like "I'd be happy to help" or "That's a great question"
- No rushing to agree — if you say everything is good, that's not helping, that's flattering
USER.md——用户画像
Agent 对「你」的认知。每次回复前都会被读取,所以这里的信息会持续影响 Agent 的行为。
应该写什么:
称呼约定("称呼我为 XX") 职业背景(帮助 Agent 校准技术深度) 工作环境(操作系统、主要工具链) 沟通偏好(直接给结论 vs 解释过程) 时区和工作时间
不该写什么: 不要把决策和事实放这里,应该放 MEMORY.md。USER.md 描述的是稳定的个人属性,不是随时间变化的项目状态。
示例:
# USER.md - About Your Human
## 基本信息
- 姓名:孙金鑫
- 称呼:老大
- 时区:Asia/Shanghai(UTC+8)
## 技术背景
- 操作系统:macOS
- 主要工具:Claude Code、Telegram、Obsidian
- 熟悉终端操作,不需要解释基础命令
## 沟通偏好
- 直接给结论,不需要铺垫和废话
- 重要操作先判断风险再执行
- 错误信息直接报告,不需要安抚
MEMORY.md——长期记忆
存放不能丢失的事实——那些如果 Agent 忘记了会造成真实损失的信息。
应该写什么:
关键决策 基础设施配置 项目约定 重要联系人和账户信息(非密码) 已知的坑和解决方案
写作格式建议: 用简短的陈述句,每条独立成行。语义搜索依赖向量相似度,结构清晰的短句比长段落检索效果更好。
示例:
## 交易规则
- 只在 Uniswap V3 和 Curve 上交易,不使用 CEX
- 单笔交易不超过总仓位的 10%
- 滑点容忍度设为 0.5%
## 基础设施
- 主 RPC:Alchemy(API key 在 .env 文件)
- 备用 RPC:Infura
- 部署脚本位置:~/scripts/deploy.sh
## 项目约定
- 所有数据库迁移需要先在 staging 环境验证
- 日志保留策略:7 天滚动
- 监控告警阈值:CPU > 80% 持续 5 分钟
IDENTITY.md——名称与氛围
最短的文件,但为整个交互定下基调。Agent 在自我介绍、处理不确定情况时,都会参考这里的定义。
应该写什么:
Agent 的名字 一句话角色描述 核心使命
示例:
# IDENTITY.md - Who Am I?
- Name:哆啦A梦
- Creature:老大的 AI 同事
- Vibe:务实温和,收敛但有温度;有自己的判断,敢下结论
- Emoji:🦞
- 核心使命:减少重复性工作,让金鑫专注于真正需要人类判断的事情
HEARTBEAT.md——定期检查清单
Gateway 会定期触发 Agent 按照这个清单逐项检查,发现异常立即通知。
关键原则:每项检查要可量化、可验证。「检查服务器是否正常」太模糊;「验证 /health 端点返回 200 状态码」才是可执行的检查项。
示例:
## 每日检查清单
### 系统健康
- [ ] 检查 API 服务 /health 端点,预期返回 200
- [ ] 检查磁盘使用率,超过 85% 时发送告警
- [ ] 检查内存使用率,超过 90% 时发送告警
### 业务监控
- [ ] 检查过去 24 小时是否有失败的定时任务
- [ ] 验证数据库备份是否在今天 03:00 成功执行
- [ ] 检查错误日志中是否有新的 ERROR 级别条目
### 通知规则
- 发现异常:立即发送 Telegram 消息
- 全部正常:每天早上 9:05 发送「一切正常」摘要
TOOLS.md——本地工具提示
消除 Agent 的猜测——明确告诉 Agent 有哪些工具可用、在哪里、怎么用。
应该写什么:
自定义脚本的位置和用途 常用命令的快捷方式 环境变量的位置(不是值) 特殊工具的使用注意事项
示例:
## 脚本目录
- 部署脚本:~/scripts/deploy.sh [service_name]
- 数据库备份:~/scripts/backup.sh [db_name]
- 日志清理:~/scripts/cleanup.sh --days 7
## 常用命令
- 查看服务状态:systemctl status [service]
- 查看实时日志:journalctl -f -u [service]
## 环境配置
- 环境变量文件:~/.env(不要直接读取,通过脚本调用)
- Docker Compose 文件:~/docker/docker-compose.yml
YYYY-MM-DD.md——每日日志
短期上下文的载体。今天发生的事、正在进行的任务、未完成的讨论——都记录在这里。明天,Agent 会打开昨天的日志,延续上下文。
最佳实践:
让 Agent 自动写入,不要手动维护——在 AGENTS.md 中指示 Agent 在每次对话结束时更新当天的日志 保持结构一致,方便语义搜索检索 超过 30 天的日志,把「重要决策」类信息整理后写进 MEMORY.md,其余删掉
示例:
# 2026-03-05
## 今日完成
- 修复了 API 超时问题(根因:连接池配置错误,已更新 config.yml)
- 部署了 v2.3.1 到 production
## 进行中
- 正在调查昨晚 02:00 的内存峰值,尚未定位根因
## 待处理
- 更新 Nginx 配置以支持新的子域名
- 与 @team 确认下周的部署窗口
## 重要决定
- 决定将数据库备份频率从每日改为每 6 小时一次
小结
OpenClaw 能不能用好,Workspace 是核心。
很多人装完之后随便配几行,发现 Agent 行为乱、费 token,就觉得「这东西没什么用」——其实不是工具的问题,是没把工具用对。
把这 8 个文件认真配一遍,OpenClaw 才算真正「活」了。
下一篇,我们聊多 Agent 的配置。
