 夜雨聆风
夜雨聆风背景
当你用AI聊天、写代码、操作终端时,其实每一次交互都在产生大量“反馈信号”:用户是否追问、工具是否执行成功、界面是否变化,这些都是对智能体行为最真实的评价,甚至还包含明确的改进建议。
但问题是这些信号几乎都被浪费了。
现有强化学习方法,要么依赖提前收集好的离线数据,要么只用最终结果作为奖励,既无法利用实时交互中的“评价信息”,也无法吸收其中的“改进指令”。结果就是:AI在被使用的过程中,并不会真正变得更好。
针对这个问题,研究者提出了OpenClaw-RL。它的核心思路很直接:把所有交互产生的后续信号统一转化为训练数据,让智能体在聊天、写代码、调用工具的过程中持续学习,在被使用的同时不断进化。
热力评分:95分
关键亮点:将实时交互产生的 next-state 信号拆解为“评价 + 指导”两类统一纳入在线强化学习,并通过 Binary RL + Hindsight-Guided OPD 实现从标量奖励到 Token 级监督的闭环优化,同时以全异步架构打通多场景 Agent 训练。
数据亮点:仅需约 36 次交互即可触发显著性能提升,个人智能体评分从 0.17 提升至 0.76,通用多场景任务在引入过程奖励后相较仅结果奖励出现稳定且可观的提升。
是否开源:已开源。
方法亮点
OpenClaw-RL的核心可以概括为三点:异步解耦的训练基础设施、两种互补的信号利用方法,以及面向长任务的过程奖励机制。
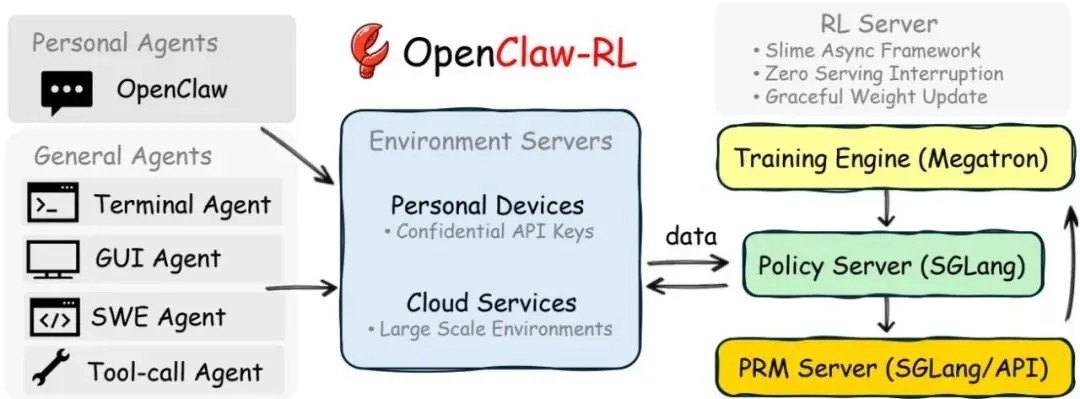
OpenClaw-RL 基础设施概览
一、全异步解耦架构:让“边用边训练”成为可能
OpenClaw-RL构建了一个完全解耦的异步系统,将整个流程拆分为四个独立循环:策略服务、环境交互、奖励判断、策略训练,彼此之间互不阻塞。
系统同时支持两类智能体:私人智能体部署在本地,通过加密API连接服务器,保障隐私;通用智能体部署在云端,支持终端、GUI、SWE、工具调用等多种环境并行运行。
整体流程为:策略服务(SGLang)→ 环境(HTTP/API)→ 奖励判断(PRM)→ 策略训练(Megatron)
这种设计有一个关键变化:当前请求在响应的同时,上一轮在打分,更早的数据在训练,实现真正的在线闭环。对私人智能体来说训练不会打断当前交互,对通用智能体缓解长任务带来的延迟问题。
此外,系统引入了会话感知机制:主轮次负责核心回复/工具执行并进入训练;副轮次负责辅助操作并不参与训练。这样只保留“高价值交互”,提升训练信号质量。
该架构具备很强扩展性,可统一支持多种真实场景,并通过后台线程记录JSONL日志,保证训练与服务解耦,同时便于调试与回溯。
二、两种信号利用方法:从“能打分”到“能指导修改”
OpenClaw-RL的关键突破在于把后续状态信号拆成两类,并分别建模。
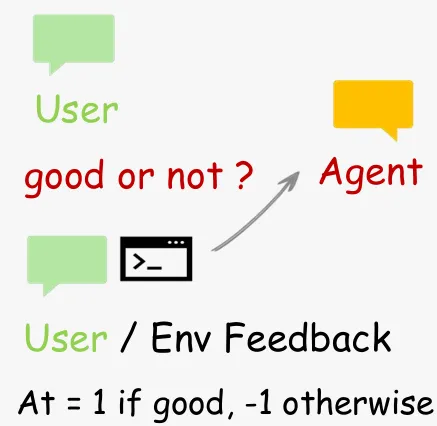
1. Binary RL:把反馈变成标量奖励
Binary RL将后续状态中的评价信息转化为离散奖励(+1 / -1 / 0):
• 通过PRM对动作进行多次独立评估并投票; • 输出稳定的奖励信号(具体公式参考论文)。
2. Hindsight-Guided OPD:把反馈变成Token级监督
Binary RL只能判断“好不好”,但无法回答“怎么改”。
OPD解决的问题是把后续状态中的“改进建议”转化为Token级训练信号。
核心流程分为四步:
• 提取结构化提示:用Judge模型把用户的后续状态信号提炼成简洁的、可执行的提示,不是直接用用户的原始回复,Judge模型会过滤掉噪音,只留下改进方向。 • 过滤并选择高质量提示:从多个并行的Judge输出里,选择最长的有效提示,如果没有有效提示就放弃这个样本。 • 构造增强上下文:把提取出的提示加到原来的用户消息里,相当于给模型创造一个“如果用户提前告诉该怎么改,会怎么回复”的场景。 • 计算Token级优势:模型在增强上下文下生成原动作的log概率,减去原模型在原上下文下的log概率,这个差值就是每个Token的调整方向——正的说明要提高这个Token的概率。
相比传统蒸馏方法,此方法不需要外部教师模型、不依赖离线数据、直接利用在线交互信号。
整个流程本质上在做一件事:模拟如果一开始就知道正确提示,模型会怎么生成。
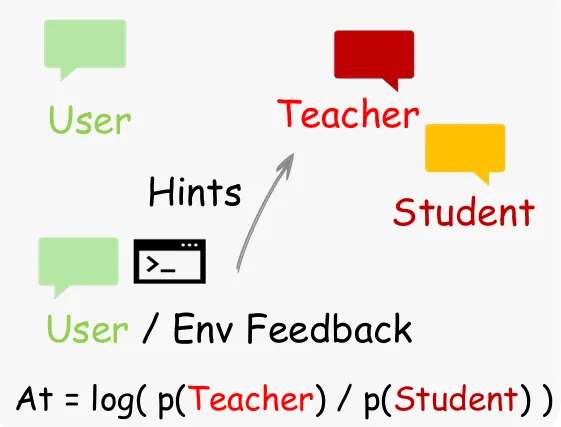
对话中的在线策略蒸馏
3. 两者结合:同时保证“覆盖面”和“精细度”
Binary RL和OPD是完全互补的,Binary RL覆盖所有有评价信号的交互,提供广泛的梯度信号;OPD针对有具体改进方向的交互,提供高精度的Token级监督。三、过程奖励:解决长任务的信用分配问题
在长任务中,仅使用最终结果奖励会导致中间步骤缺乏反馈。
OpenClaw-RL引入过程奖励:
• 使用PRM对每一步动作打分; • 将过程奖励与最终奖励结合,作为训练信号。
这样每一步都有反馈,显著缓解“信用分配”问题。
同时,为适应真实场景状态难以对齐的问题,方法采用按步骤索引分组归一化,在保证简单性的同时提升稳定性。
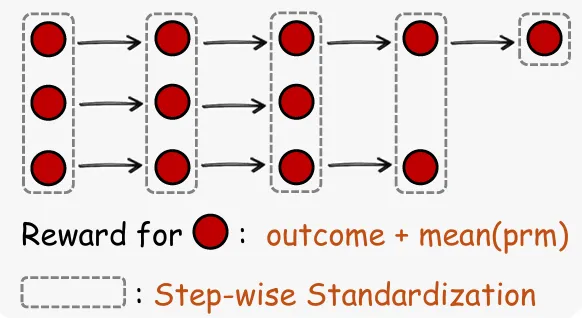
智能体强化学习轨迹中的过程奖励
实验结果
研究者从个人智能体个性化和通用智能体跨场景训练两个方向验证了OpenClaw-RL的效果,整体结论很明确:
不仅学得快,而且能稳定泛化到多种真实场景。
一、个人智能体:少量交互即可显著个性化
实验构建了两个典型场景:
• 学生场景:学生用OpenClaw做作业,希望回复的风格像人类手写的,避免被发现用AI; • 教师场景:老师用OpenClaw批改作业,希望评语友好且具体。
实验用Qwen3-4B作为基础模型,每收集16个样本就触发一次训练,结果显示:
• 组合方法(Binary RL + OPD)效果最优:8次更新后,学生场景的个性化得分从0.17涨到0.76,老师场景从0.22涨到0.90; • 单独方法存在明显短板:单独用Binary RL的话,8次更新后只有0.25的得分,提升很小;单独用OPD的话,前期慢,但后期有效(16次更新达0.72)。
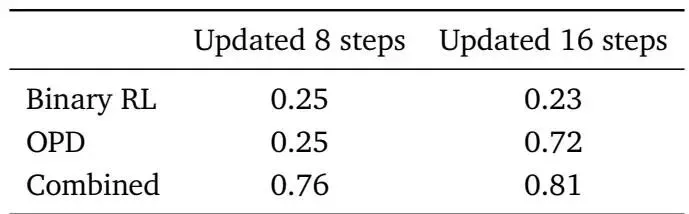
Binary RL提供快速反馈,OPD提供精细调整,只有两者结合才能又快又准。
从具体的例子也能看出变化:学生场景里,原来的回复有明显的AI风格,格式混乱的计算步骤,经过训练后,回复的步骤更自然,没有生硬的标注;老师场景里,原来的评语很冰冷,只说答案正确,经过训练后,评语会指出具体的拼写错误,还会鼓励学生。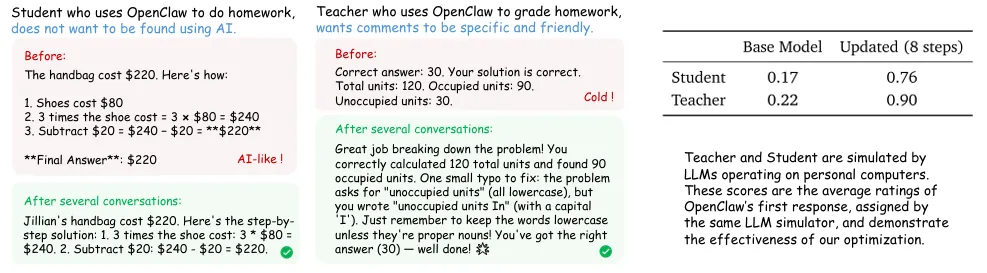
二、通用智能体:多场景稳定提升
实验覆盖四类典型Agent场景:终端、GUI、SWE、工具调用,并采用大规模并行环境训练。
结果显示,OpenClaw-RL在四个场景里都能有效提升模型性能:
• 终端智能体:准确率随RL步骤稳步上升,100步左右接近0.5; • GUI智能体:准确率从0.26涨到0.33; • SWE智能体:Pass@1在30步左右达到0.18以上; • 工具调用智能体:准确率从0.08涨到0.17左右。
这说明同一套训练框架可以跨场景稳定生效,而不是只对单一任务有效。
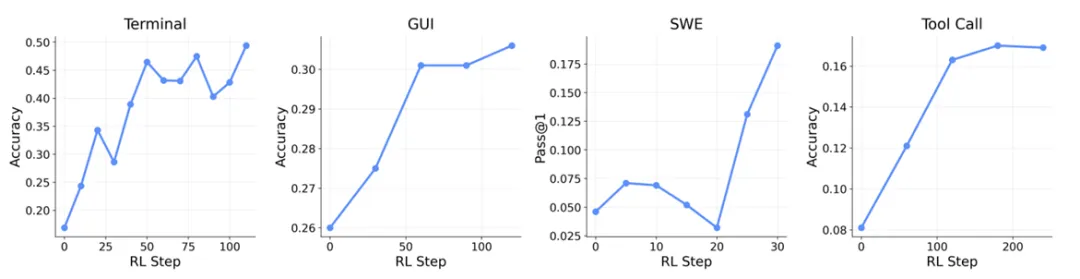
框架支持通用智能体可扩展强化学习
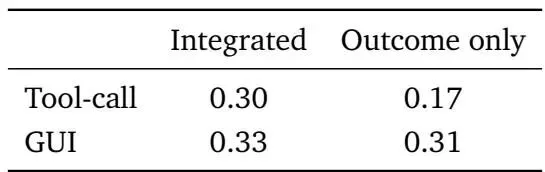
三、过程奖励:长任务提升更明显
在长任务中,引入过程奖励(PRM逐步打分)后:
• 工具调用:0.17 → 0.30 • GUI任务:0.31 → 0.33
结论与展望
这项工作的价值在于重新定义了智能体的学习方式:把每一次真实交互都转化为训练信号,并通过统一框架同时吃掉“评价信息”和“改进指令”。
无论是个人助理的个性化,还是终端、GUI、代码等复杂场景的通用智能体,它都提供了一条可落地的路径,让系统在使用过程中持续进化。同时,全异步解耦的工程设计也让“边服务边训练”真正可行,兼顾了效果与效率,这种从方法到系统的闭环能力,在当前Agent研究中并不多见。
论文与代码地址
论文地址:https://arxiv.org/abs/2603.10165
开源地址:https://github.com/Gen-Verse/OpenClaw-RL
