和你分享一个非常简单、但能让效率提升 2 倍、Token 节省 20 倍的硬核技巧。我们会聊聊如何让 AI 放弃笨重的 “看图说话”,直接从网页背后掏出结构化的 API 数据。1. 前言
在折腾 AI Agent 浏览器自动化的同学,可能都遇到过这种让人抓狂的场景:为了让 AI 抓取某个内部系统的表格数据,你不得不指挥它打开页面、等待那一堆沉重的 DOM 树加载完毕,然后再截取一长串的 Snapshot 喂给 LLM。结果呢?Token 消耗瞬间爆炸,动辄上万点的消耗不仅烧钱,还因为数据太长经常被截断,AI 面对那一堆乱七八糟的 UI 噪音(各种 ref、nth、button)还要反应大半天,速度慢得像蜗牛爬。做浏览器自动化或抓内部系统数据时,难道成本一定要这么 “爆炸” 吗?2. 先给结论(TL;DR)
- 思路降维打击:把沉重的浏览器 Snapshot 换成精准的 API Evaluate 模式。
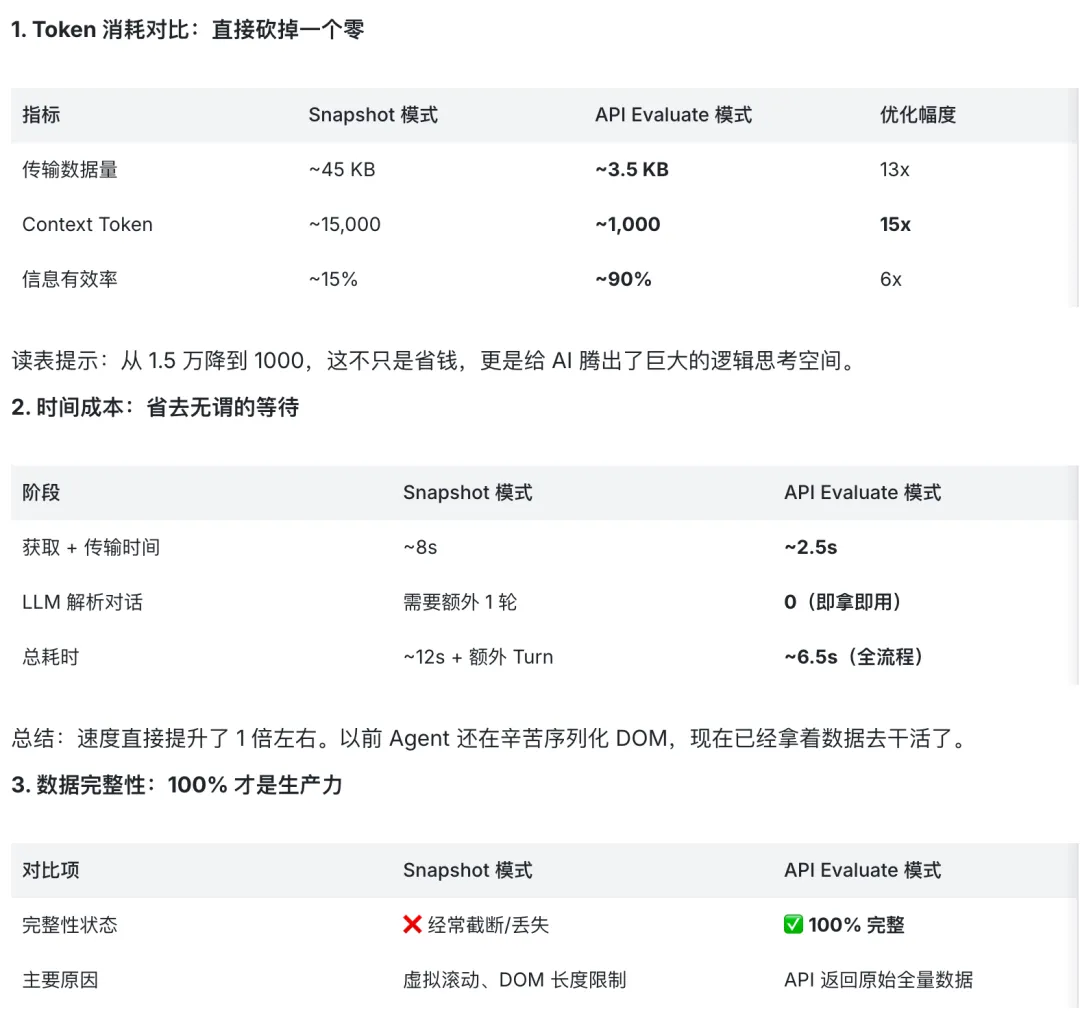
- Token 暴减:同样的任务,Token 消耗能从 15,000 直接降到 1,000 左右,降低 15-20 倍。
- 速度起飞:端到端耗时直接减半,从 12 秒 + 缩短到 6.5 秒,1 轮对话即搞定。
- 数据不丢:告别虚拟滚动导致的截断,数据完整性直接拉到 100%。
- 适用广泛:所有基于 Web 的数据平台、BI 系统、代码仓或任务管理工具通杀。
核心洞察:Web 页面本质上只是 API 数据的 “皮肤”。AI Agent 真的不需要辛苦地去 “看皮肤”,它完全可以直接读取皮肤下的数据骨架。3. 为什么 Snapshot 又慢又贵?
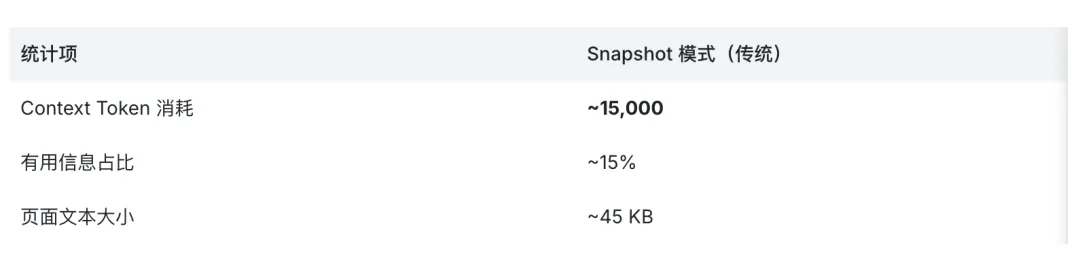
在传统的 AI 浏览器自动化流程里,我们通常是这么干的:打开页面 → 等待渲染 → Snapshot(抓 DOM 树)→ 喂给 LLM → AI 解析提取看着挺顺,但在实际操作中,这个流程藏着三个让你成本飞涨的 “无底洞”:一个普普通通的数据表页面,Snapshot 出来的文本往往有 45-80 KB。把这些全都塞进 Context,每一秒都在烧你的 Token。你真正想要的数据(比如字段名、数值)其实只占页面的 15% 甚至更少。剩下的全是 UI 框架产生的 “噪音”:什么 nth-child、各种 button、img 标签,对 AI 来说全是干扰。AI 拿到 DOM 后,还得额外花一轮对话去苦苦 “理解”:这是哪一列?这个数据跟那个表头对应吗?我们在查询一张 54 个字段 的内部数据表结构时,用 Snapshot 方式轻轻松松就吃掉了 15,000 个 tokens。而这其中,真正的有效信息其实不到 1,000 tokens。剩下的 14,000 个 token,你全花在了传输那些没用的 UI 噪音上。4. 一个思路转变:让 Agent ‘调接口’ 而不是 ‘看页面’
既然 AI 也是个 “程序”,为什么不让它用程序最擅长的方式交流呢?几乎所有 Web 系统背后都有 API 支撑,我们完全可以指挥 Agent 像前端开发查 Bug 一样,直接去掏接口数据。Step 1:假装 “看” 页面,实则借 Cookie首先让浏览器正常打开目标页面。这一步的目的不是为了截 Snapshot,而是为了让浏览器帮我们处理好登录态和 Cookie。只要页面开了,认证就生效了。Step 2:一键 “嗅探” 真正的 API 接口在页面加载后,让 Agent 执行一行 JS 代码,从浏览器的性能条目里把所有请求列出来。performance.getEntriesByType('resource') .filter(e => e.name.includes('/api/') || e.name.includes('/v2/')) .map(e => e.name)
这里有个小技巧:通过关键词(比如 /api/、/v2/ 或者你业务相关的名称)过滤,就能精准定位到那个喂数据的核心接口。找到 API 之后,直接在当前同一个标签页(Tab)里执行 fetch 调用。为什么要同 tab?因为这样可以完美复用刚才的 Cookie 认证,零成本搞定鉴权!// 直接拿走结构化的 JSON 数据fetch('/api/v2/data-stores?qualifiedName=xxx&withSchema=true') .then(r => r.json()) .then(data => JSON.stringify(data))
看,拿到的直接是干干净净的 JSON,AI 甚至都不需要解析,拿起来就能用。5. 实测:省 15-20 倍 Token,速度翻倍
光说不练假把式,我们把两种方式放在一起硬碰硬比一下。还是以刚才提到的那个 54 个字段的数据表为例:6. 为什么这招这么省?把 ‘给人看的’ 换成 ‘给程序用的’
为什么 API 模式能有这么夸张的降幅?秘诀就在于它把 “人机界面” 变成了 “机机界面”。结论:同样的语义,JSON 比 DOM 简洁 10 倍。Snapshot 模式下,为了表示一个 “用户 ID”,它得返回一堆 cell、ref 标记、一堆样式属性;而 API 只需要一行简洁的 {"name": "user_id"}。用 Snapshot,AI 得先分析 “第 3 列是啥”,再分析 “第 5 行在那”。用 API,数据已经是完美的结构化 JSON,AI 只需要直接取值,完全不需要猜测。很多高级组件库为了性能只渲染可见的 20 行,100 行的数据得滚动 5 次。但 API 不管这些,一次调用,全量返回,再也没有懒加载、DOM 截断的烦恼。⚠️ 什么时候不适合(需要兜底)
如果遇到以下情况,这招可能失灵,建议继续用 Snapshot 兜底:- 页面数据全是在前端本地计算出来的,没有明显的后端数据 API。
- 后端 API 加密非常变态,无法通过简单的 Evaluate 复用 Cookie。
- 完全由 Canvas 渲染的复杂可视化图表,没有原始数据接口。
8. 把这套方法变成你的固定动作(Checklist)
下次给你的 Agent 写 Skill 或写 Prompt 时,记得对照这个清单检查一下:
9. 把方法论变成可复用能力:snapshot-to-api
如果你觉得每次手动搞这些太麻烦,好消息是:我们已经把这套方法论打包成了一个开箱即用的 OpenClaw Skill —— snapshot-to-api。它不是为了取代你的原有效率,而是作为一个 “加速插件”。安装后,Agent 在执行任何浏览器任务时,都会自动尝试寻找并沉淀 API 路径,实现自动化的 “自我进化”。npx clawhub@latest install snapshot-to-api
- 当你对 Agent 说 “帮我优化这个抓取过程” 时。
打开页面(借用认证 Cookie)→ Network 发现数据 API→ 原地测试 API 响应→ 提取 JSON 数据→ 将 API 逻辑沉淀回原 Skill(实现加速)
下次当你发现 Agent 的浏览器操作又大、又慢、又贵时,别急着加内存或换模型,先试试这招 “调接口” 的黑科技吧!
 夜雨聆风
夜雨聆风