 夜雨聆风
夜雨聆风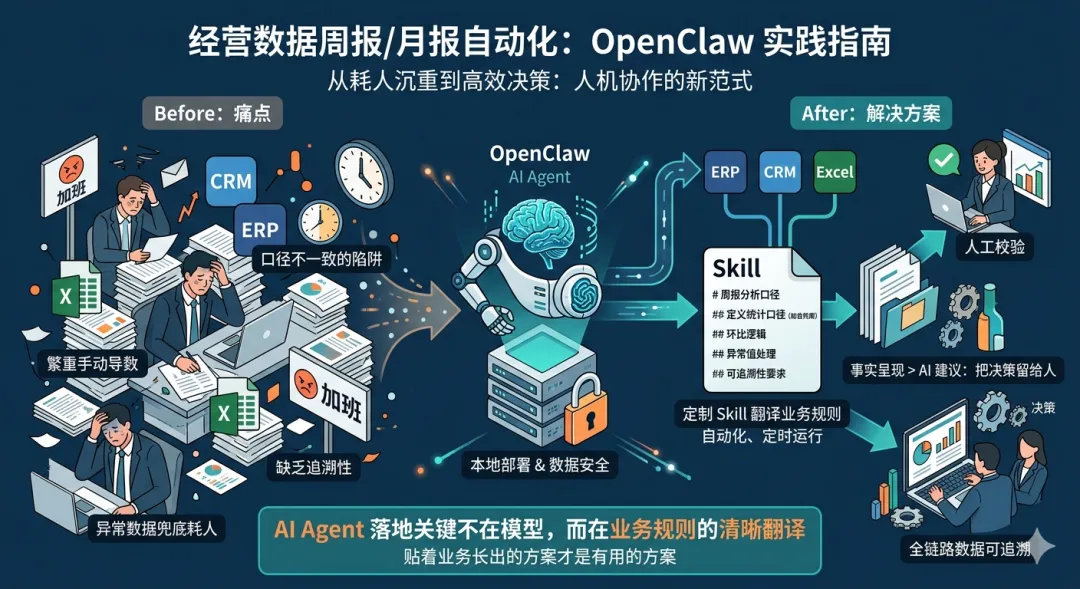
在跟企业打交道的过程中,有一类需求被反复提起:经营数据的周报/月报自动化。
场景几乎一模一样——每到周五或月末,财务部或运营部从 ERP、CRM、Excel 里手动导数据,拼成一份十几页的经营分析报告。同比环比、区域对比、异常标注,三个人干一整天,有时候还得加班到晚上。
这件事情本身不复杂,但很耗人,而且越是做得认真的公司,这份报告越厚、流程越重。
我最近在想:能不能用 OpenClaw 把这件事跑起来?不是想象中的"能不能",是真的搭了一个原型,跑了一遍,记录一下结果和问题。
为什么是这个场景
先说一下为什么我觉得"经营周报"是一个值得认真对待的 AI 落地场景。
去年底以来,"AI Agent"这个概念很热。前几天英伟达 GTC 大会上黄仁勋直接说:"每家公司都应该制定自己的 OpenClaw 战略。" 英伟达甚至发布了 NemoClaw——OpenClaw 的企业版,专门解决安全和隐私问题。
但概念归概念,企业真正愿意花钱解决的问题,往往不是听起来最酷的那个,而是每周都在重复、每次都很痛、但又不得不做的那个。
经营周报就是这样的东西。它有几个特征特别适合用 AI 来做:
- 数据来源固定
:通常就是 ERP + 销售系统 + 几个 Excel,不会每周换 - 分析逻辑稳定
:同比、环比、排名、异常检测,规则清晰 - 输出格式标准
:老板要看的东西每周都差不多 - 执行频率高
:每周一次,投入产出比明确
换句话说,这活儿"脏"但不"难",是 AI Agent 最擅长的领域——重复性高、规则明确、不需要太多创造力。
我搭的方案长什么样
OpenClaw 的核心能力是本地部署的 AI 智能体,它不是一个聊天窗口——它可以读写文件、执行脚本、访问数据库、定时运行任务,而且所有数据都在本地,不上传到任何第三方。
这一点对企业来说非常关键。经营数据涉及收入、利润、客户信息,传到公网大模型上,大部分老板心里是过不去的。
整套方案的架构大致分四步:
① 数据接入
通过 API 或脚本把各个数据源(金蝶/用友、企业微信、Excel 文件夹)的数据定时拉到本地数据库。这一步最繁琐,因为每家企业的系统不一样,接口文档的质量也参差不齐。
② 编写 Skill(分析指令)
OpenClaw 的能力扩展靠一种叫 Skill 的机制——本质上是一个 Markdown 文件,里面写清楚"从哪取数据、算什么指标、用什么口径、输出什么格式"。相当于把财务主管脑子里的分析逻辑,翻译成 AI 能执行的标准化指令。
这是整个方案里最核心的环节,也是最容易出问题的环节。后面会展开说。
③ 定时执行
配一个 cron 定时任务,比如每周五下午5点自动触发。OpenClaw 自己醒过来跑完全流程,把报告生成到指定目录,或者推送到企业微信/飞书。
④ 人工校验
跑完之后,由业务主管过一遍数字,确认无误再发给管理层。
几个绕不开的深坑
方案看起来逻辑很清晰,但真正动手搭的时候,有几个问题是反复出现的。
第一,口径对齐问题。
这是最容易被忽视、也最容易出事的。ERP 里的"本周"可能是自然周(周一到周日),但销售部门按排班周统计(周二到下周一)。两边差一天,某笔大额退货记录落在不同的统计周期里,毛利率就可能被算成负数。
人工做报表的时候,财务知道要手动调日期,AI 不知道,Skill 里没写,它就不会去想。
这意味着,写 Skill 的人必须对业务口径了然于胸。 这不是技术问题,是业务理解问题。
第二,异常数据的兜底。
新开的门店只营业了3天,AI 照常算环比——和上周满勤数据一比,收入"暴跌"60%。这不是真实下降,是样本不可比。
类似的情况很多:促销周 vs 正常周、春节前后、系统故障导致的数据缺失……这些"例外情况"都需要在 Skill 里提前设好规则。否则 AI 会老老实实输出一个在数字上正确、但在业务上毫无意义的结论。
第三,也是我认为最重要的一点:AI 不应该给"建议"。
测试的时候,我让 AI 在报告末尾加了一段"经营建议"。它写了这么一句:
"建议重点关注某门店的利润异常,考虑调整定价策略或成本结构。"
问题是,这条建议是基于一个口径错误的数据生成的。数字本身就是错的,但建议读起来头头是道。
这件事让我想了很久,后来我把"建议"模块删掉了,报告只呈现事实和数据异常,判断和决策留给人来做。
在上个月我做 AI 风控实验的时候也得出过一个类似的结论——AI 对自己处理的数据对不对,是没有"痛感"的。格式正确、逻辑通顺,对它来说就算完成任务了,至于那个数字会不会导致老板做出错误决策,它不焦虑。
所以,至少在现阶段,AI 最可靠的能力是"把散的数据理干净",最不可靠的能力是"告诉你应该怎么做"。
第四,可追溯性。
报告里的每一个数字,必须标注来源(从哪个系统拉的、查询条件是什么、统计周期是几号到几号)。否则业务主管拿到报告没法校验,也没法向管理层解释某个数字的来龙去脉。
这一点在 Skill 设计里很容易被遗漏,但在企业实际使用中是刚需。
这套方案适合什么样的企业
说实话,不是所有企业都适合现在就上这套东西。
适合的:
数据源相对集中(主要在1-2个系统里),接口可用 报表格式和分析逻辑稳定了至少半年以上 有一个懂业务口径、能写清楚规则的人(不一定是技术人员)
暂时不适合的:
数据还散在各种微信群和纸质单据里,连电子化都没做完 报表格式每个月都在变,分析逻辑还没沉淀下来 希望 AI "自己就能搞定一切",不愿意投人做规则梳理和校验
后者需要的不是 AI,是先把基础数据治理做了。
一个感受
GTC上黄仁勋说的那个"AI Agent 拐点",我是认同的。但真正动手做企业项目之后会发现,拐点不在模型多聪明,而在业务规则有没有被翻译清楚。
写这套方案里的 Skill,花在理解"他们的周报到底怎么算的"上的时间,比花在写代码上的时间要多得多。
AI 能跑得很快。但如果喂给它的规则是模糊的、口径是错的、例外情况没有覆盖——它只会更快地输出一个错误的结果。
如果你的企业有其他需求,评论区可以聊聊——每家公司的数据环境和分析口径都不一样,通用方案往往装不进去,真正能用的方案都是贴着业务长出来的。
