 夜雨聆风
夜雨聆风OpenClaw 架构解析(上):消息如何变成 AI 行动
你在飞书里发了一句「帮我查一下明天北京的天气」,3 秒后收到了一条精确到小时的天气预报。
这 3 秒里发生了什么?消息从飞书服务器出发,穿过 OpenClaw 的六层管道,交给 AI 大脑理解意图、调用工具、拿到结果,再原路返回变成你看到的那条回复。
这 3 秒的背后,是一套经过精密设计的消息流水线——从协议翻译到意图理解,从队列调度到流式回发,每一步都有明确的分工。
今天我们拆开这个过程,看看 OpenClaw 这个 120 万行 TypeScript 的「AI 特工指挥部」,到底是怎么把一条普通消息变成 AI 行动的。
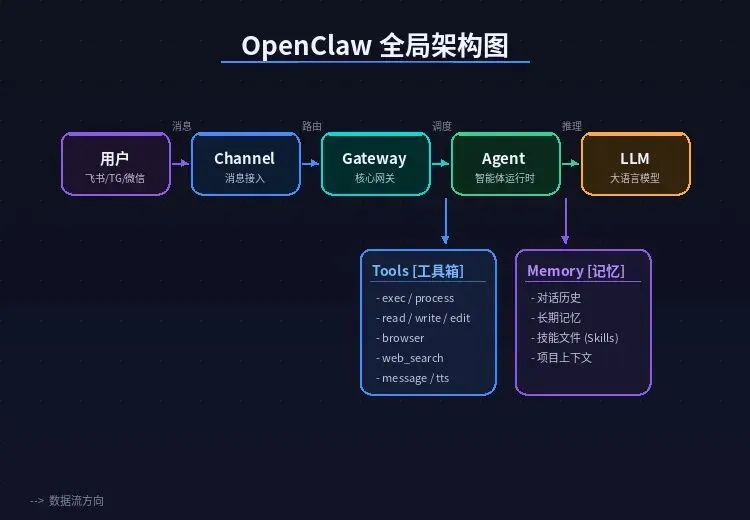
全局架构鸟瞰
先看全景。OpenClaw 的架构可以用一句话概括——单进程 Node.js,撑起了从消息接入到 AI 执行的全部链路。
数据流是这样走的:
消息渠道(Telegram / 飞书 / Discord / ...) → Channel Plugin(统一格式) → Auto-Reply 消息管道(路由 + 预处理) → Agent Runtime(LLM 调用 + 工具执行) → Block Streaming(流式分块) → Channel Plugin(格式化回发) → 消息渠道五个核心角色各司其职:
●Gateway:指挥中枢,单进程承载一切,对外提供 WebSocket + HTTP 双协议
●Channel Plugin:万能翻译官,把 22+ 种渠道的消息翻译成统一格式
●Auto-Reply 管道:六层流水线,从收到消息到发出回复的完整调度
●Agent Runtime:AI 大脑,负责与 LLM 交互、调用工具、多轮推理
●Memory:长期记忆,向量搜索 + 全文检索的混合后端
这篇文章聚焦前三个——Gateway、Channel 和消息管道。Agent Runtime 的故事留给下篇。
Gateway:指挥中枢
如果把 OpenClaw 比作一个操作系统,Gateway 就是它的内核。所有渠道适配器、Agent 运行时、浏览器控制、定时任务……全部跑在 Gateway 这一个 Node.js 进程里。
为什么选择单进程?答案是极致的部署简洁性——npm install -g openclaw 一条命令装完,不需要 Redis、不需要消息队列、不需要容器编排。对于个人 AI 助手这个场景,单进程意味着零运维成本。代价当然也有:任何一个组件的阻塞都可能影响全局。OpenClaw 选择用异步 I/O + Lane 并发控制来化解这个问题,而不是引入多进程架构的复杂度。
启动流程:12 步点火
Gateway 的入口是一个 800 多行的 startGatewayServer() 函数,启动过程分 12 个阶段。精简来看,核心步骤是这些:
配置加载(Zod schema 校验) → Secrets 激活(API Key 快照) → Auth 引导(自动生成 Token) → Plugin 加载(扫描 extensions/ 目录) → Channel 启动(按配置逐个启动渠道适配器) → WS + HTTP Server 创建 → Sidecar 启动(Browser / Canvas / Tailscale) → Cron 引擎启动 → Config 热重载监听器值得注意的是,Gateway 的返回值极其精简——只暴露一个 close() 方法:
type GatewayServer = { close: (opts?: { reason?: string; restartExpectedMs?: number | null; }) => Promise<void>;};启动完毕,Gateway 就像一个安静的守卫——你只能叫它关门,其他一切都通过协议交互。这种「最小表面积」的 API 设计,体现了一个原则:Gateway 是控制面,不是产品本身——产品是运行在它之上的 AI Assistant。
WS + HTTP 双协议
Gateway 对外暴露的是单端口(默认 18789),同时承载 WebSocket 和 HTTP 两套协议。
WebSocket 是主力——采用 JSON-RPC 2.0 格式,注册了 80+ 个 RPC 方法。CLI、macOS App、iOS/Android Node 都通过 WS 连接。核心方法包括:
●chat.send / chat.abort:消息收发与中断
●sessions.list / sessions.reset:Session 管理
●config.get / config.set:运行时配置读写
●exec.approval.request:命令执行审批
HTTP 做的事情更有趣——它实现了完整的 OpenAI-compatible API:
POST /v1/chat/completions → OpenAI 格式请求POST /v1/responses → OpenResponses 规范GET /health → 健康检查POST /api/channels/*/webhook → 渠道 Webhook 回调这意味着任何能调 OpenAI API 的客户端,都能直接对接 OpenClaw——你的 Agent 瞬间变成了一个私有 LLM 网关。Cursor、Continue 这类开发工具配上 OpenClaw 的 HTTP 端点,就能用你自己的 Agent 作为后端,工具调用能力一个不少。
配置热重载:改配置不用重启
这是 Gateway 最优雅的设计之一。config.yaml 被文件 watcher 监听,任何修改都会触发变更检测。系统会把变更分成两类:
Hot Reload(热重载)——不需要重启: - Channel 启停 - Heartbeat 间隔调整 - Browser 配置变更 - Cron 任务增删
Cold Restart(冷重启)——必须重启: - 端口变更 - TLS 开关 - Auth 模式切换
热重载的实现是增量式的——只重启变更的组件。比如你修改了 Telegram 的配置,Gateway 会精确地只重启 Telegram 适配器,其他渠道纹丝不动。
背后的实现也值得一看:系统对配置变更做 diff,生成一个 ReloadPlan,精确标记哪些组件受影响:
type ReloadPlan = { channelsChanged: boolean; // Channel 需要重启 heartbeatChanged: boolean; // 心跳间隔变了 cronChanged: boolean; // 定时任务变了 needsRestart: boolean; // 是否需要冷重启 restartReason?: string; // 冷重启的原因};这套热重载机制的另一个好处是 Secrets 管理——API Key 的切换是原子操作。系统先 prepare 新的 Secrets 快照,验证通过后再原子切换。如果验证失败,回退到上一次的 last-known-good 快照,不会出现「Key 换了一半,一部分请求用新的一部分用旧的」这种尴尬局面。
Channel Plugin:万能翻译官
OpenClaw 支持 22+ 种消息渠道:Telegram、Discord、Slack、WhatsApp、Signal、飞书、Line、iMessage、IRC、Matrix……每个渠道的消息格式、能力边界都不一样。
Channel Plugin 要解决的核心问题只有一个:让上层代码不需要知道消息从哪来。
统一的 Plugin 接口
每个渠道适配器都实现同一套接口。接口按职责拆成了十几个 Adapter——消息发送、流式输出、线程管理、安全策略各归各管:
type ChannelPlugin = { id: ChannelId; // "telegram" | "feishu" | ... meta: ChannelMeta; // 名称、图标、排序 capabilities: ChannelCapabilities; // 能力声明 // 核心能力 outbound?: ChannelOutboundAdapter; // 发送消息 streaming?: ChannelStreamingAdapter; // 流式输出 security?: ChannelSecurityAdapter; // 安全策略 actions?: ChannelMessageActionAdapter; // 投票、反应、按钮 // Agent 扩展 agentPrompt?: ChannelAgentPromptAdapter; // 注入渠道提示 agentTools?: ChannelAgentToolFactory; // 渠道专属工具};其中 ChannelCapabilities 是一个精巧的能力声明结构——每个渠道启动时告诉系统「我能做什么」:
type ChannelCapabilities = { markdown?: boolean; // 支持 Markdown? inlineButtons?: boolean; // 能发内联按钮? reactions?: boolean; // 能加表情反应? editMessage?: boolean; // 能编辑已发消息? typing?: boolean; // 能显示"正在输入"? maxMessageLength?: number; // 单条消息长度上限};上层消息管道会根据这些能力自动适配——Telegram 支持消息编辑,就用 Draft Stream 模式实时更新;Discord 单条消息限 2000 字,就自动分块发送。
20+ 适配器的规模差异
适配器之间的代码量差距惊人:
Telegram 和 Discord 各写了 4 万行,不是因为它们难接,而是因为功能太丰富——贴纸识别、Draft Stream、Thread 绑定、内联查询……每个平台特色功能都做了深度适配。
一条飞书消息怎么变成统一格式
当你在飞书发了一条消息,数据流是这样的:
飞书服务器 → Webhook → Gateway HTTP → Feishu Plugin.onMessage() → 解析飞书消息体(富文本 / 图片 / 文件) → 媒体下载到本地暂存 → 构建 MsgContext → 交给 Auto-Reply 管道MsgContext 是所有渠道共用的统一消息格式:
type MsgContext = { CommandBody: string; // 消息文本 CommandSender: string; // 发送者名称 MessageProvider: string; // "feishu" | "telegram" | ... MessageTo: string; // 目标 chat ID MediaPath?: string; // 本地媒体路径(如果有附件) SenderIsOwner?: boolean; // 是不是管理员};从这一刻起,上层再也不关心这条消息来自飞书还是 Telegram——它只是一个 MsgContext。这正是 Channel Plugin 层存在的意义:把 22 种渠道的差异吸收掉,给消息管道一个干净统一的输入。
同样的逻辑反过来也成立——Agent 回复时只需要生成标准的 ReplyPayload(文本 + 可选的媒体/按钮),Channel Plugin 负责把它翻译成飞书的富文本卡片、Telegram 的 HTML 消息或 Discord 的 Embed。上层完全不需要操心格式适配。
消息管道:六层流水线
好了,消息已经穿过 Channel 变成了统一格式。接下来它要经历 Auto-Reply 管道的六层处理。这是整个 OpenClaw 最精密的部分——6.6 万行代码,每一层只做一件事。
完整链路
① Channel 收到消息 → dispatchInboundMessage()② 命令解析 → /status? /reset? /model? 拦截处理③ 内容预处理 → Link Understanding + Media Understanding④ 排队决策 → Queue Policy(enqueue / discard / interrupt)⑤ Agent 调用 → runReplyAgent() → Pi Agent Runtime⑥ 流式回发 → Block Streaming → Channel.send()逐层拆解。
第一层:消息分发。dispatch.ts 是管道入口。它做的事情不多——把 MsgContext 最终化(补全缺失字段),然后交给 dispatchReplyFromConfig() 做路由决策。路由的核心是解析 Session Key——格式为 {channel}:{chatId},比如 telegram:12345 或 feishu:oc_abcdef。
第二层:命令检测。 如果消息以 / 开头,系统会先检查是不是内置命令。OpenClaw 注册了十几个斜杠命令——/status 看状态、/reset 清空对话、/model sonnet 切换模型、/thinking high 开启深度思考。命中命令就直接返回结果,不走 Agent。
第三层:内容预处理。 两个重要的预处理步骤: - Link Understanding:消息里有 URL?提取网页内容注入上下文 - Media Understanding:消息里有图片?交给 Vision 模型描述;有语音?交给 Whisper 转录
经过这一步,Agent 拿到的不是一个孤零零的 URL 链接,而是完整的网页摘要。这些预处理对 Agent 的回答质量影响巨大——很多用户发消息时会随手贴个链接,如果 Agent 看不到链接内容,就只能泛泛而谈。
第四层:排队决策。 如果 Agent 正在处理上一条消息,新消息怎么办?这就是 Queue Policy:
type QueueAction = | "enqueue" // 排队等待(默认) | "discard" // 丢弃 | "interrupt"; // 中断当前,处理新的默认是排队,最多排 5 条,队列满了就丢弃。这避免了用户疯狂发消息导致 Agent 瘫痪的问题。
第五层:Agent 调用。 核心函数 runReplyAgent() 做了五件事——发送「正在输入」信号、调用 Pi Agent Runtime 执行 LLM 推理、运行 Followup(如果 Agent 需要后续对话)、刷新 Memory 索引、统计 Token 用量。
这里有一个精巧的 Fallback 机制:如果默认模型(比如 Claude)不可用,系统会自动切换到备选模型(比如 GPT-4)重试。更细粒度的是 Auth Profile 轮转——同一个模型配了多个 API Key,Key A 限流了自动切 Key B,Key B 也挂了再切 Key C。用户完全无感知,只是回复可能慢了半秒。
第六层:流式回发。 Agent 的输出是逐 token 流式到达的。Block Streaming 管道把 token 流聚合成合适大小的文本块再发送——不会让用户等到全部生成完才看到回复,也不会每个 token 都发一条消息(太碎片化)。
Block Streaming:流式输出的艺术
Block Streaming 是 OpenClaw 消息管道的点睛之笔。它的配置参数直接影响用户体验:
const pipeline = createBlockReplyPipeline({ minChars: 30, // 首块最小字符数 maxChars: 4000, // 单块最大字符数 breakPreference: "paragraph", // 优先在段落边界断开});Telegram 还有一个特殊的 Draft Stream 模式——不发新消息,而是持续编辑同一条消息。用户看到的效果就像 ChatGPT 网页版那样,文字在一条消息里逐渐「生长」出来。而对于不支持消息编辑的渠道(比如某些 IRC 客户端),系统会自动降级为分块发送。
这种基于 ChannelCapabilities 的自适应策略贯穿了整个 Block Streaming——有能力就用最好的方式,没能力就优雅降级,永远不会因为渠道限制而报错。
Queue Policy:为什么需要排队
你可能觉得排队机制多余——Agent 不够快就并发不就行了?
不行。同一个 Session 里的消息必须串行处理,因为对话有上下文依赖。你说了「帮我分析这段代码」,紧接着说「用 Python 重写」——第二条消息依赖第一条的结果。如果并发执行,第二条消息看不到第一条的分析结果,回复就会驴唇不对马嘴。
OpenClaw 用 Lane 系统实现了精确的并发控制:
Session Lane(同一 session 内串行) → Global Lane(全局并发上限)每个 Session 一个队列保证对话顺序,全局 Lane 控制总并发防止系统过载。简洁,但有效。

回顾:一条消息的完整旅程
把上面的内容串起来,一条飞书消息从发出到收到回复,完整路径是这样的:
你在飞书输入:"帮我查一下明天北京的天气" → 飞书服务器 Webhook → Gateway HTTP 端点 → Feishu Channel Plugin 解析消息 → 构建 MsgContext → dispatch.ts 分发 → Session Key: "feishu:oc_xxx" → 命令检测:不是斜杠命令,继续 → 内容预处理:无 URL、无媒体,跳过 → Queue Policy:Session 空闲,直接执行 → Agent Runtime:LLM 理解意图 → 调用 weather 工具 → 拿到结果 → Block Streaming:聚合文本块 → Feishu Channel Plugin 格式化发送 → 你看到了天气预报整个链路,6 层管道,每一层干净利落。
下篇预告:AI 大脑如何思考和行动
这篇文章我们走完了消息的「外部旅程」——从渠道进来,穿过管道,到达 Agent 门口。但最精彩的部分还没讲:Agent Runtime 到底怎么工作的?
下篇将深入 OpenClaw 的 AI 执行引擎:
●Pi Agent Runtime:18.5 万行代码的 LLM 调用核心——多轮工具循环、Auth Profile 轮转、Context Overflow 自动压缩
●40+ 内置工具:从文件读写到浏览器控制,Agent 的「手脚」是怎么接上的
●Memory 系统:向量搜索 + BM25 全文检索的混合记忆——Agent 怎么记住你说过的话
●ACP 子 Agent 编排:当一个 Agent 不够用,怎么 spawn 一群子 Agent 协同工作
●安全模型:从 DM Policy 到 Exec Approval,多层防御是如何贯穿全栈的
Gateway 是指挥部,Channel 是翻译官,管道是流水线——但真正让 OpenClaw 与众不同的,是那个 18.5 万行的大脑。
下篇见。
