 夜雨聆风
夜雨聆风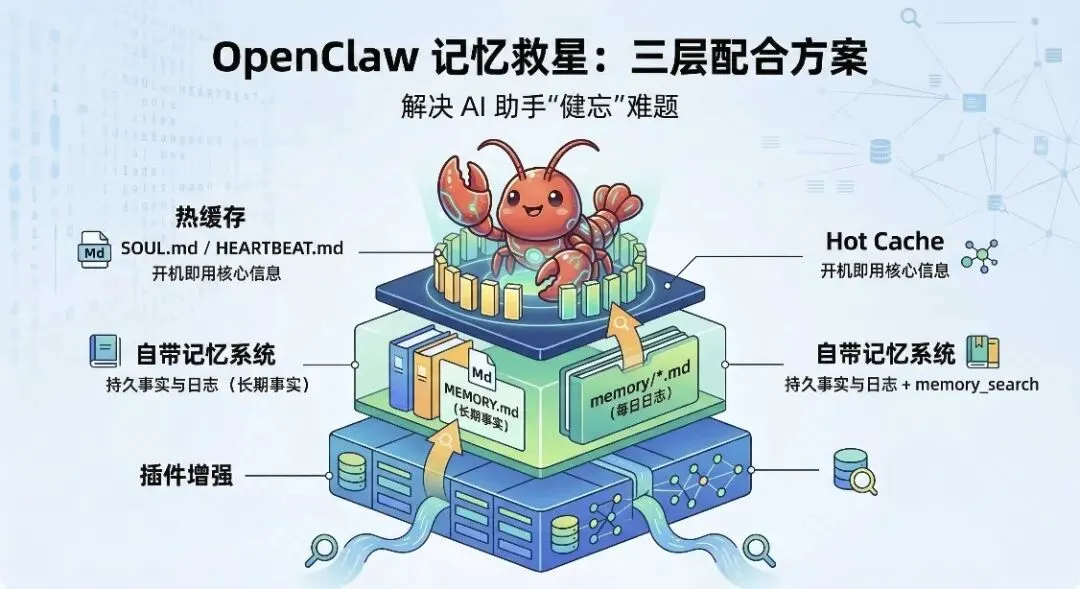
OpenClaw记忆优化方案
在 X 社区看到一个高频问题:
“用 OpenClaw 聊了三天,昨天刚配好的 API 权限,今天它就忘得一干二净,又问了我一遍。”
底下一堆人附和:
“我也是!上周搭的系统,这周它就不记得了。”
“每次都要重新提醒,太烦了。”
[问题/场景拆解]
先搞清楚:
OpenClaw 自带一套完整的记忆系统,不是“没记忆”。
OpenClaw 官方记忆现在已经默认支持向量搜索了!首先要升级到3.12及以上版本。
• 文件为事实标准:记忆就是工作区里的纯 Markdown 文件
• memory/YYYY-MM-DD.md:每日日志(追加),会话启动时读今天+昨天
• MEMORY.md(可选):精选长期记忆,仅在主会话/私密会话加载,绝不用于群组
• 自带工具:memory_search(语义搜索)+ memory_get(目标读取)
• 向量搜索默认开启:对 MEMORY.md + memory/*.md 建向量索引,支持混合搜索(BM25+向量)、MMR 多样性重排、时间衰减
• 使用 sqlite-vec(当可用时):在 SQLite 内部加速向量搜索
• 需要配置 embedding provider:OpenAI/Gemini/Voyage/Mistral/Ollama 等,否则会禁用
• 自动记忆刷入:会话接近压缩时,会静默提醒模型先写持久记忆
配合lossless-claw这个插件共同解决了大多数智能体面临的两大核心问题:
• 会话内失忆:在一次长对话中,由于滑动窗口机制而遗忘早期消息 -> lossless-claw 解决
• 会话间失忆:不同聊天或不同日期之间毫无记忆延续 -> 官方记忆(配置好 embedding 后)即可解决。
那为什么还会“忘”?
因为:
1. 如果没配置 embedding provider,官方记忆的向量搜索会禁用
2. 单会话上下文太长被裁剪后,中间的对话细节就没了
3. 重启会话后,默认只加载今天+昨天的日志,更早的细节需要 memory_search 才能捞到
还有人错误的尝试是:
• 把所有信息都塞到 SOUL.md 里,导致文件越来越臃肿,每次启动都烧一堆 Token
• 每次对话开头都重复一遍“你还记得吗?上周我们…”
• 干脆放弃,每次用都重新配置一遍
正确的思路是:
三层记忆配合:
• 热缓存(SOUL.md/HEARTBEAT.md):只放每次启动必须知道的核心信息
• 自带记忆(MEMORY.md + memory/.md + memory_search,配置好 embedding 后支持向量搜索*):持久事实和日常日志
• 插件增强(lossless-claw):会话内失忆解决
记忆不是记住所有东西,而是三层配合,在需要的时候能快速找到。 💬
[OpenClaw实战演示]
我先理清楚三层怎么配合,然后装作者推荐的 lossless-claw:
我:先跟我确认一下 OpenClaw 官方记忆的用法,然后帮我装 lossless-claw 插件,GitHub 链接是 https://github.com/martian-engineering/lossless-claw
OpenClaw:好的,先快速过官方记忆:
1. 决策/偏好/持久事实 -> 写 MEMORY.md
2. 日常笔记 -> 写 memory/YYYY-MM-DD.md
3. 想找之前的内容 -> 用 memory_search(**配置好 embedding 后支持向量搜索**)
然后看 lossless-claw README:
它用基于 DAG 的摘要系统替换了 OpenClaw 的内置滑动窗口压缩,在保持活动上下文在模型 token 限制内的情况下,保留了每条消息。
安装步骤:
1. 克隆仓库
2. 装依赖
3. 在 OpenClaw 配置里加插件路径和触发规则
要我现在执行吗?
装完之后,我让它生成了一条测试记忆,然后重启 OpenClaw:
我(重启后):你还记得刚才我们聊了什么吗?分两部分:
1. 官方记忆的用法
2. 装了什么插件
OpenClaw:等一下,我先用 lcm_describe 查一下最近的对话… 哦对:
1. 官方记忆用法:决策/偏好写 MEMORY.md,日常写 memory/YYYY-MM-DD.md,找内容用 memory_search(**配置好 embedding 后支持向量搜索**)
2. 刚装了 lossless-claw,它用基于 DAG 的摘要系统替换了 OpenClaw 的内置滑动窗口压缩,在保持活动上下文在模型 token 限制内的情况下,保留了每条消息
官方记忆(配置好 embedding 后)已经支持向量搜索了,不一定需要 memory-lancedb-pro 这个插件! 💬
[lossless-claw 参数配置说明]
lossless-claw 的配置示例:
{
"plugins": {
"entries": {
"lossless-claw": {
"enabled": true,
"config": {
"freshTailCount": 32,
"contextThreshold": 0.75,
"incrementalMaxDepth": -1,
"ignoreSessionPatterns": [
"agent:*:cron:**"
],
"summaryProvider": "anthropic",
"summaryModel": "claude-3-5-haiku"
}
}
}
}
}
参数说明:
• freshTailCount: 32
• 作用:保留最近 32 条原始消息不压缩
•说明:这是"新鲜尾部"的数量,确保最近的对话上下文保持完整、未经压缩的原始状态,让模型能获取最准确的近期交互信息
•contextThreshold: 0.75
• 作用:上下文使用率达到 75% 时触发压缩
•说明:当对话占用的 Token 量接近模型上下文窗口的 75% 时,插件开始对更早的消息进行摘要压缩,而不是等到满了再处理,起到"提前预警"效果
•incrementalMaxDepth: -1
• 作用:增量摘要的最大层级深度
•说明:-1 表示无限制,允许对摘要再生成摘要(多层嵌套);若设为 1,则只允许一级摘要,禁止"摘要的摘要",可减少信息损失但增加 Token 消耗
•ignoreSessionPatterns: ["agent:*:cron:"]**
• 作用:指定需要忽略压缩的会话模式
• 说明:使用 glob 模式匹配。示例中忽略了所有 agent::cron:* 格式的会话(即定时任务/Cron 类型的 Agent 会话),这些会话通常是短时执行的,无需记忆管理
[进阶配置技巧]
技巧 1:自定义 lossless-claw 的保留策略 + 配合官方记忆刷新
· 适用场景:想控制 Token 消耗,又不想丢太多对话细节,同时让官方记忆也能用到这些内容
· 具体操作:
• 在 lossless-claw 配置里设 freshTailCount: 25(保留最近 25 条不压缩),contextThreshold: 0.75(上下文使用率达到 75% 时触发压缩)
• 每天结束时,让 OpenClaw 扫一下当天的重要对话,自动摘要后写到 memory/YYYY-MM-DD.md 里
· 注意事项:别把 freshTailCount 设太大,否则还是会烧 Token
技巧 2:配置官方记忆的 embedding 支持向量搜索
· 适用场景:想用上官方记忆的向量搜索,解决会话间失忆问题
· 具体操作:
• 在 OpenClaw 配置里配置 agents.defaults.memorySearch.provider(比如 openai/gemini/ollama)
• 配置好对应的 API key(比如 GEMINI_API_KEY/OPENAI_API_KEY/OLLAMA_API_KEY)
• 然后就可以用 memory_search 搜 MEMORY.md + memory/*.md 里的内容了(支持混合搜索、MMR 多样性重排、时间衰减)
· 注意事项:如果没配置 embedding provider,官方记忆的向量搜索会禁用
技巧 3:给关键记忆打标签(支持双端)
· 适用场景:有些信息(比如 API 密钥、重要配置)想让它优先找到,无论是用官方工具还是插件工具
· 具体操作:
• 在对话里提“把这条记成「重要配置」标签”,同时让它写到 MEMORY.md 里并加上 ## 重要配置 标题
• 官方端用 memory_search 搜“重要配置”,能快速定位
· 注意事项:别打太多重要标签,否则上下文窗口占用太多AI会变笨
记忆不是存得越多越好,而是三层配合、有条理、能快速检索。 💬
[结尾]
OpenClaw 的记忆问题,
本质不是“没自带记忆”,
而是“不知道怎么配合官方记忆(配置好 embedding 后支持向量搜索)+ lossless-claw”——
搞清楚分层,配合好工具,它就能从“ chatbot”变成“真的懂你工作的助手”。
