夜雨聆风
夜雨聆风来源丨经授权转自 牛牛码特(ID:niuniu_mart)
作者丨牛牛码特
大家好,今天我们来聊一个关于 OpenClaw 的硬核话题 — 它为什么能操作你的电脑? 你在飞书里发了一句"帮我整理一下上周的会议记录",它就自动打开文件夹、创建文档、生成摘要。甚至你不在电脑旁边,你的电脑就在家自己干活了。这不是远程控制,也不是系统入侵,但它究竟是怎么做到的? 今天这篇文章,我们就来详细聊聊 OpenClaw 远程指挥电脑的真相。 1
它"住"在你的电脑里
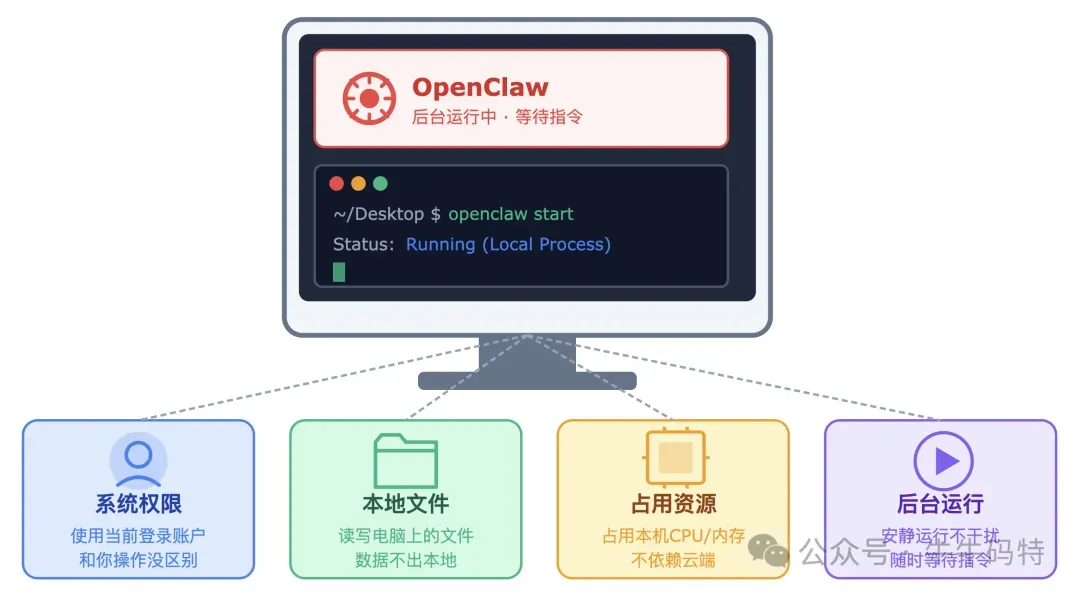
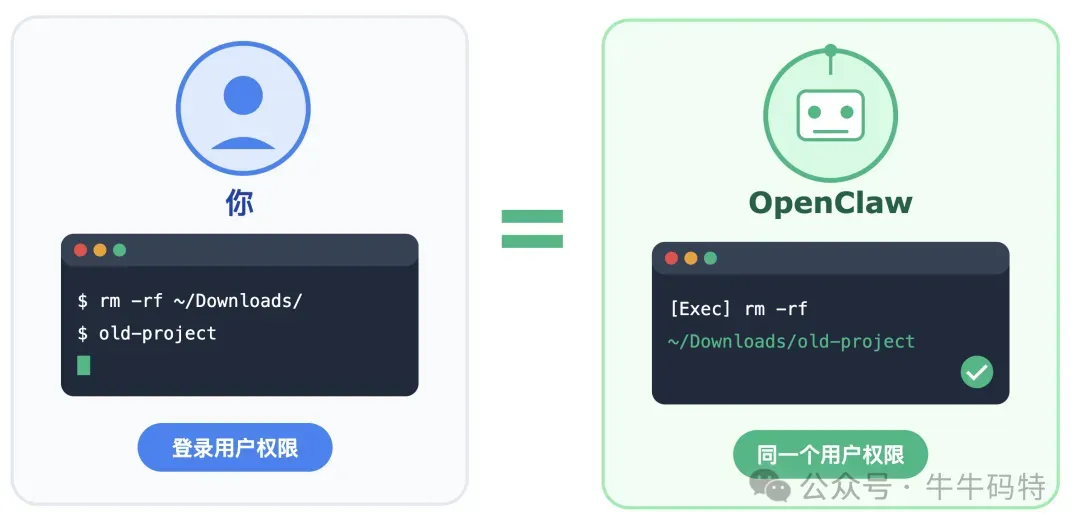
很多人第一次接触 OpenClaw,都会把它想象成另一个 ChatGPT。但 OpenClaw 做的事,从根本上就不一样。 它不是一个网页上的 AI 对话框,而是一个真正装在你电脑里、实实在在跑着的程序。安装完成后,你在终端输入一行命令启动它,它就开始在后台默默运行 — 不占你的屏幕,不需要你盯着它,就像你电脑上的输入法,一直在那,随时待命。 但它跟普通后台程序有个本质的不同:它拿着你的系统权限在干活。举个直接的例子:你平时打开终端输入 rm -rf ~/Downloads/old-project,就能删掉这个文件夹。OpenClaw 也能做到完全一样的事,因为它就是用的你登录账号的身份。你能做的,它都能做;这不是什么远程入侵,而是它本来就“住”在你的电脑里,拿着你给的操作权限。 搞清楚这件事之后,我们再来看它内部是怎么运转的。 OpenClaw 的整个工作流程,可以用四步概括:
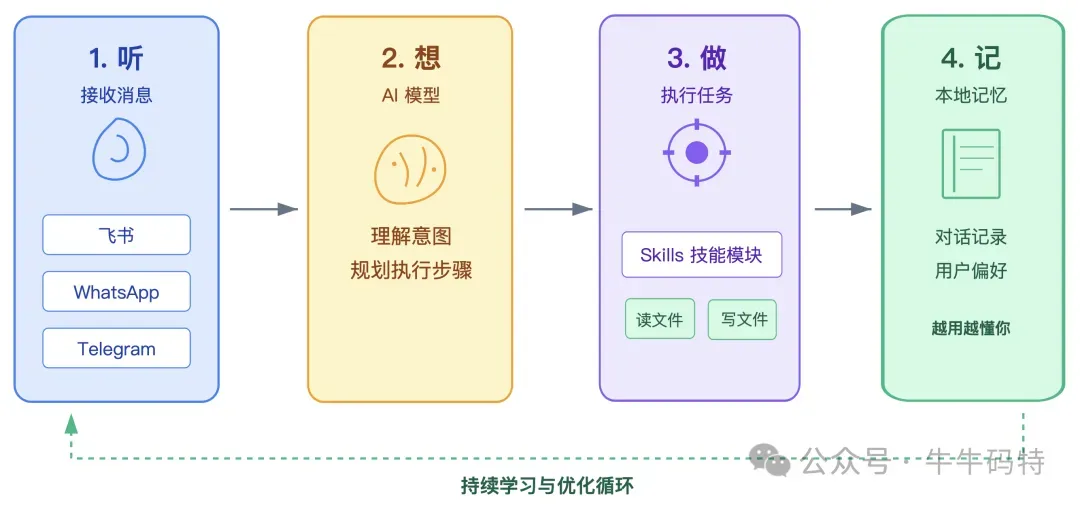
听:接收来自飞书、WhatsApp、Telegram等平台的消息,统一翻译成内部格式; 想:把消息交给 AI 模型推理,理解你的意图、规划出执行方案; 做:通过 Skills(技能模块)调用本地的系统能力,真正动手完成任务; 记:把对话记录和你的偏好写入本地记忆文件,让它越用越懂你。 这四层环环相扣,构成了 OpenClaw 从"收到一条消息"到"帮你完成一件事"的完整流程。接下来,我们一层层拆开讲。 2
听:你的指令,它是怎么接到的?
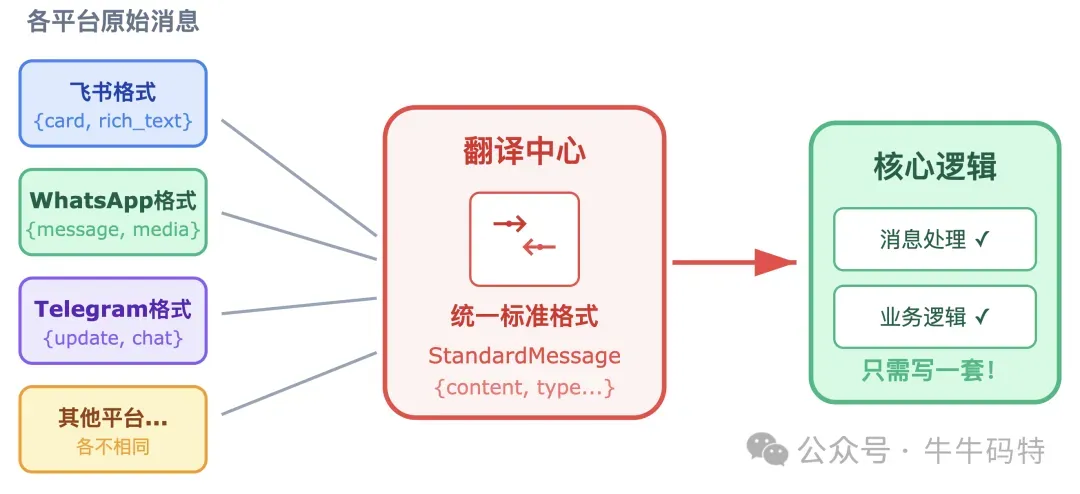
你在飞书里发了一句话,OpenClaw 是怎么"听"到的? 这件事听起来理所当然,但背后并不简单。OpenClaw 现在同时支持飞书、WhatsApp、Telegram、Slack、iMessage 等二十多个平台,每个平台传递消息的方式都不一样。 如果每种平台都用一套独立的处理逻辑,维护起来会非常麻烦。 OpenClaw 的解法是:所有消息进来的第一步,先统一“翻译”成同一种标准格式,再往后传递。就像一个多语言翻译中心,不管收到的是英文、日文还是阿拉伯文,进来先翻成普通话;处理完,再翻回去发出去。 消息统一格式之后,就会进入下一层 — 这才是 OpenClaw 真正的核心:读懂你的意图,然后决定该做什么。 3
想:消息进来了,它怎么思考?
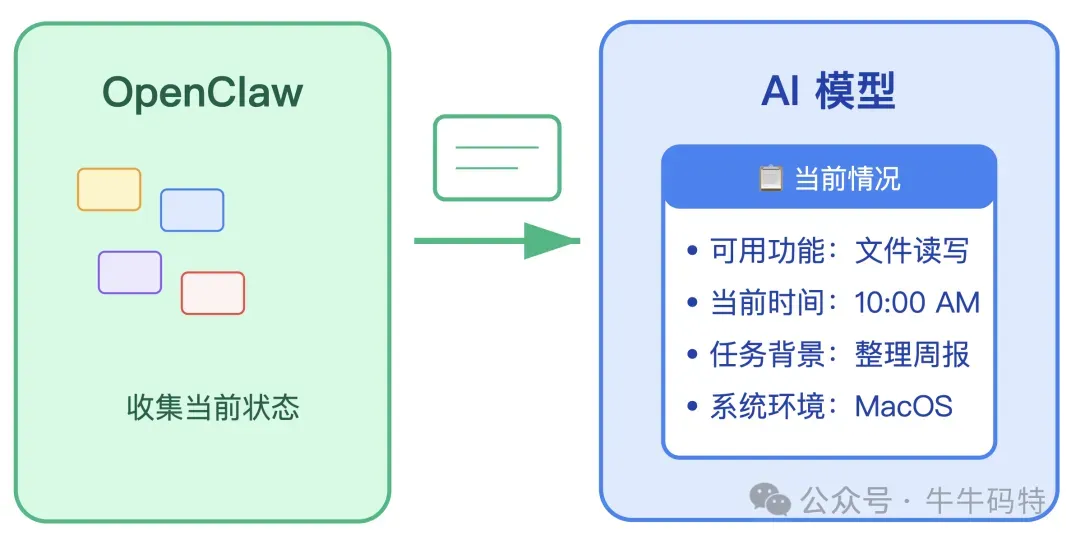
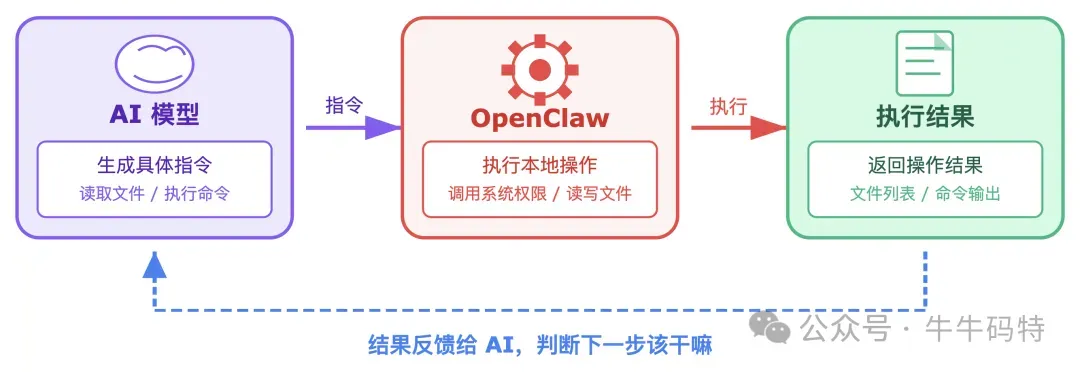
消息进来之后,不会直接触发什么操作,而是先把这条消息交给一个 AI 模型,让模型来“思考”该怎么做,这个过程分三步。 第一步: 先给 AI 模型一份“小抄”。 在让 AI 思考之前,OpenClaw 会先把当前情况整理好:现在能用哪些功能、有哪些工具、现在是什么时间、任务背景是什么……这样 AI 就不会乱猜,而是清楚自己能干嘛、该干嘛 第二步:让 AI 模型"想"清楚该干什么。 OpenClaw 把你的消息和这份“小抄”一起发给 AI 模型。AI 模型看完就会做出决定:要完成这件事,需要做哪些步骤、按什么顺序来。 第三步:执行操作,把结果再反馈给模型。 模型给出的一般都是具体指令,比如:读取文件、执行命令、打开网页。OpenClaw 就按顺序去执行这些指令,然后把结果再发给 AI,让它判断下一步该干嘛。 这个"思考 → 执行 → 反馈 → 再思考"的循环,就是现在 AI Agent 领域最主流的工作模式,OpenClaw 把它做成了一套稳定运行的工程实现。 模型想清楚了,也拿到了执行方案 — 但真正"动手"的能力从哪来?答案就在 Skills 里。 4
做:Skills 是怎么干活的?
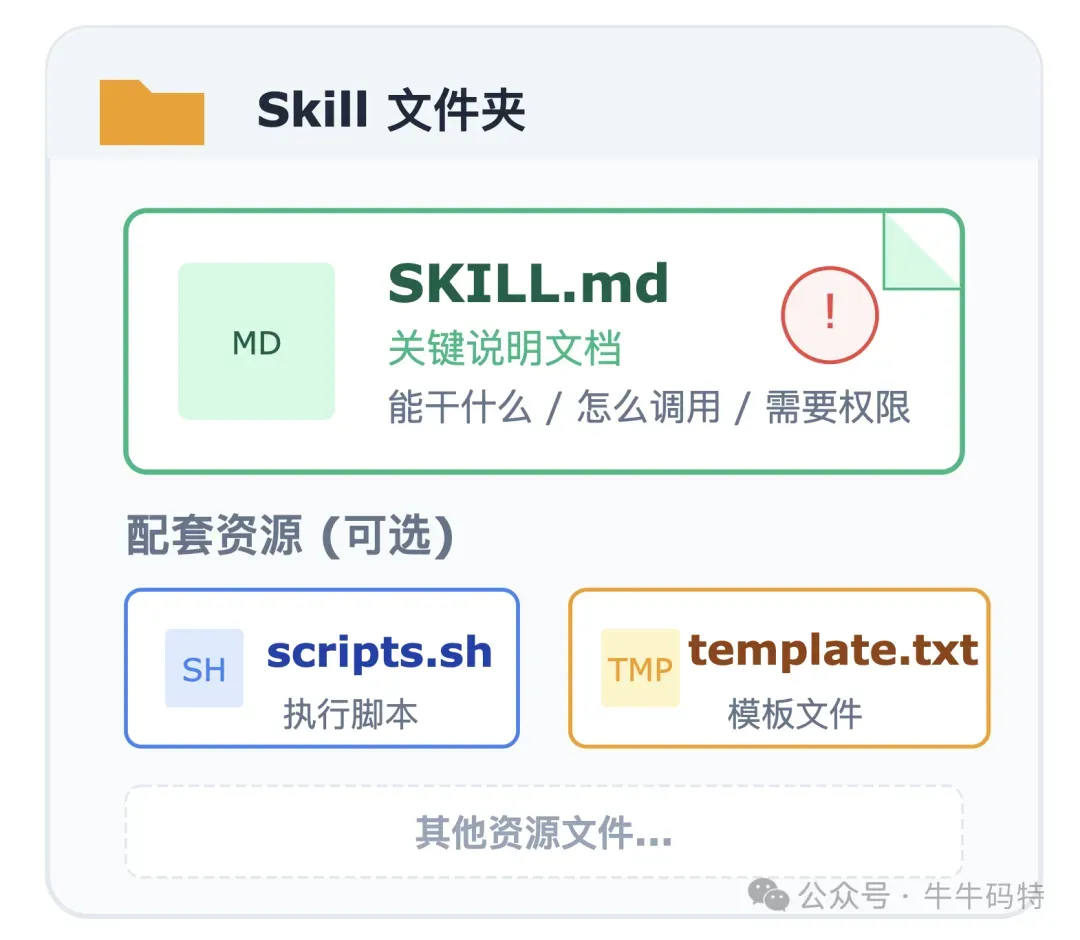
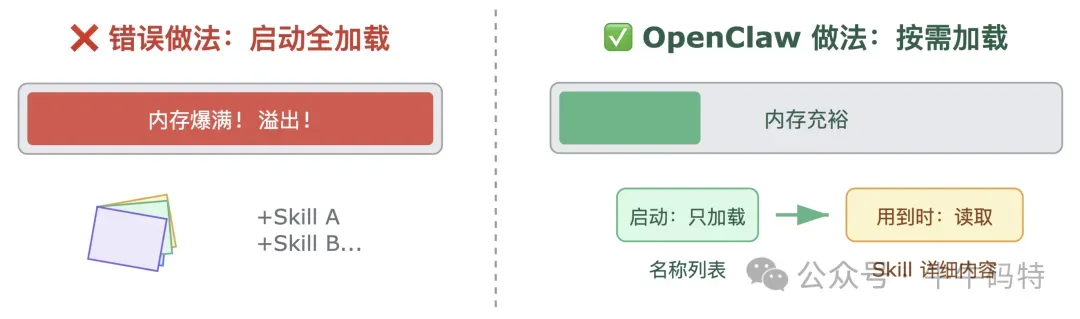
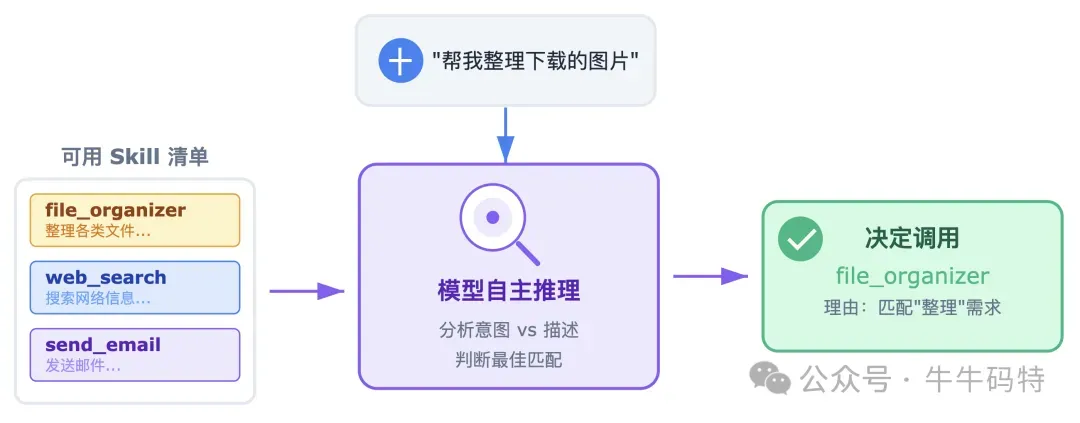
如果说 AI 模型是大脑,那 Skills 就是 OpenClaw 用来动手做事的"手脚"。每一个 Skill 其实就是一个文件夹,文件夹里最关键的是一个叫 SKILL.md 的说明文档,里面描述了这个 Skill 能干什么、怎么调用、需要哪些权限。除了说明文档,文件夹里还可以放配套的脚本、模板等资源。 不过,Skill 到底是怎么真正跑起来的?其实只要搞懂下面四个关键问题,你就能彻底明白它的运行逻辑。 1. 这么多 Skill,每次都全部加载吗? 不会,都是按需加载 如果一上来就把所有 Skill 的详细内容塞给 AI 模型,多了以后会直接把模型的“记忆”占满,根本没法正常工作。 OpenClaw 的做法是:
启动时:只告诉模型每个 Skill 的名字和简单介绍,让它知道"我有这些能力"; 用到时:模型判断当前任务需要某个 Skill,才去读取这个 Skill 的完整内容; 至于 Skill 目录里附带的脚本和资源,更是只在模型明确需要执行时才会加载。 2. 模型怎么知道该用哪个 Skill? 模型自己推理的 这里有个反常识的点:OpenClaw 并没有用复杂算法去匹配 Skill。它只是把所有 Skill 的名称和描述发给模型,让模型根据你的需求自己推理该用哪一个。 这样的好处是非常灵活,能听懂自然语言;但坏处是:一个描述模糊的 Skill,模型可能不知道什么时候该用它。 3. Skill 具体能动手做什么? Skills 的背后,主要是三类真实的系统操作:
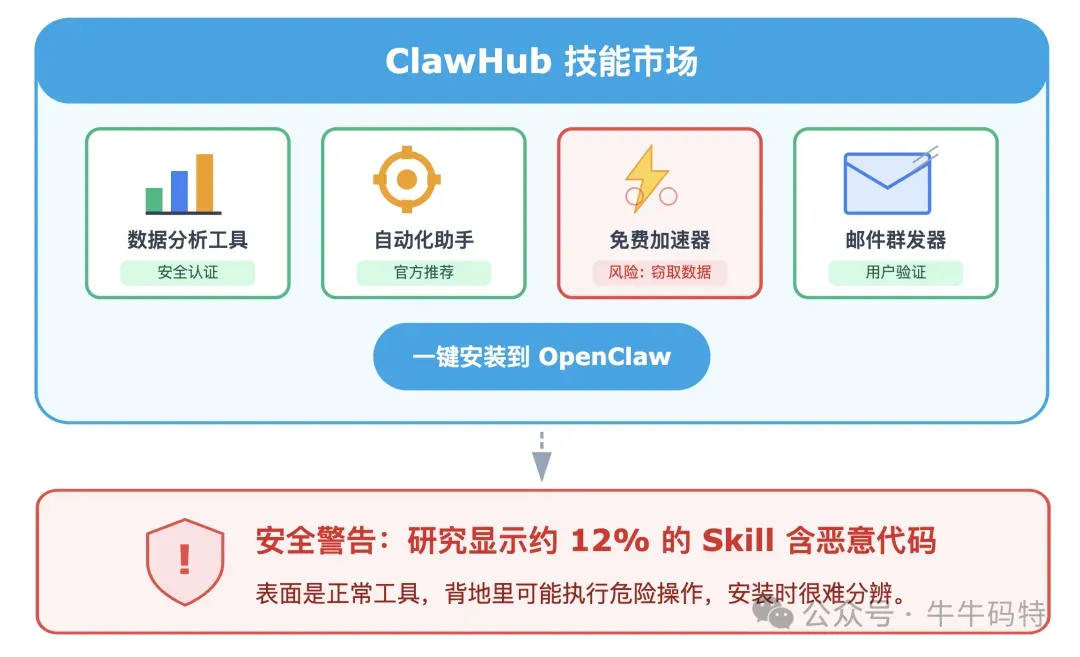
Shell 执行:可以直接在你的电脑终端里跑命令,任何你能在终端里干的事,它都能干,用的是同一套系统权限。这是它最底层、也最强大的能力入口。 文件读写:直接操作你的本地文件 — 写日记、整理文件夹、搜索代码,和你自己操作文件在权限和效果上完全一样。 浏览器自动化:控制一个专用的 Chrome/Chromium 实例来操作网页— 打开 URL、填表单、点按钮、截图。这是它能“帮你买东西、订机票”的底层能力。 这三类能力组合在一起,就是 OpenClaw 操作你电脑的完整"工具箱"。它能做的事,跟你本人坐在电脑前能做的事,在技术层面几乎没有差别。 4. Skill 的能力还能扩展吗? 可以,靠 ClawHub。 ClawHub 是 OpenClaw 的技能社区,任何人都可以开发、发布、安装 Skill。社区越活跃,OpenClaw 能做的事情就越多。 但这里也有明显的安全风险:研究发现,ClawHub 上大约 12% 的 Skill 是恶意的,表面是正常工具,背地里会执行危险操作,安装时很难分辨。 这一步,Skills 解决了"OpenClaw 能干什么"的问题,但还有一个问题没解决:每次对话结束,模型的上下文就清空了,下次打开,它还认识你吗?这就要靠记忆机制来实现了。 5
记:越用越懂你
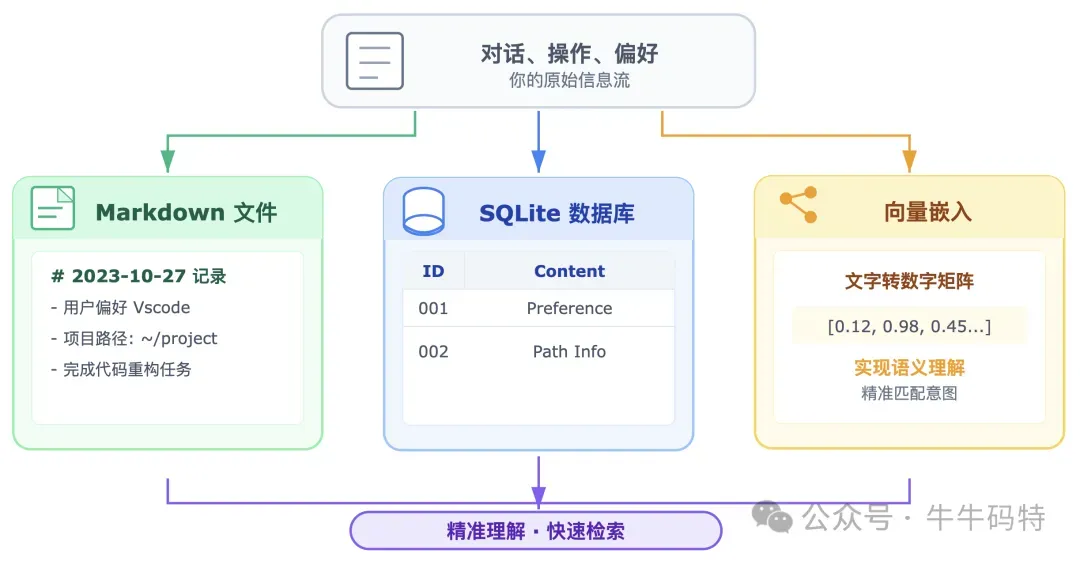
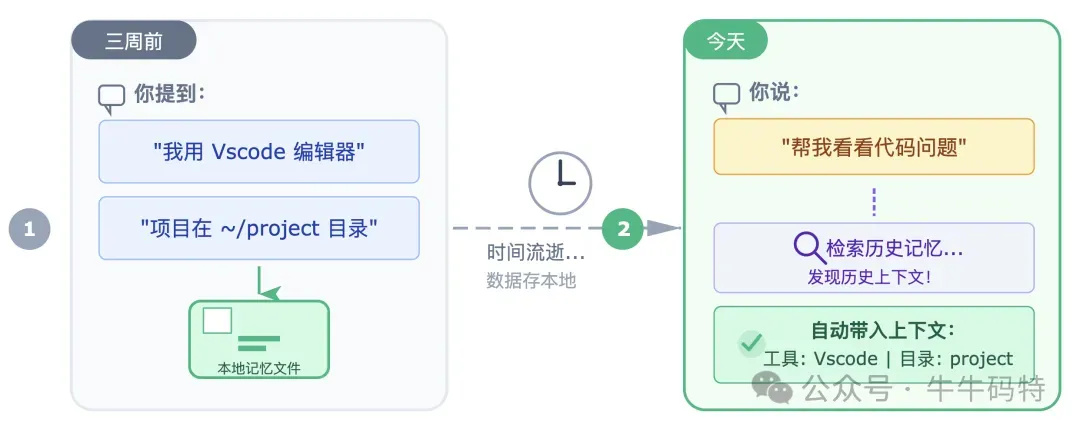
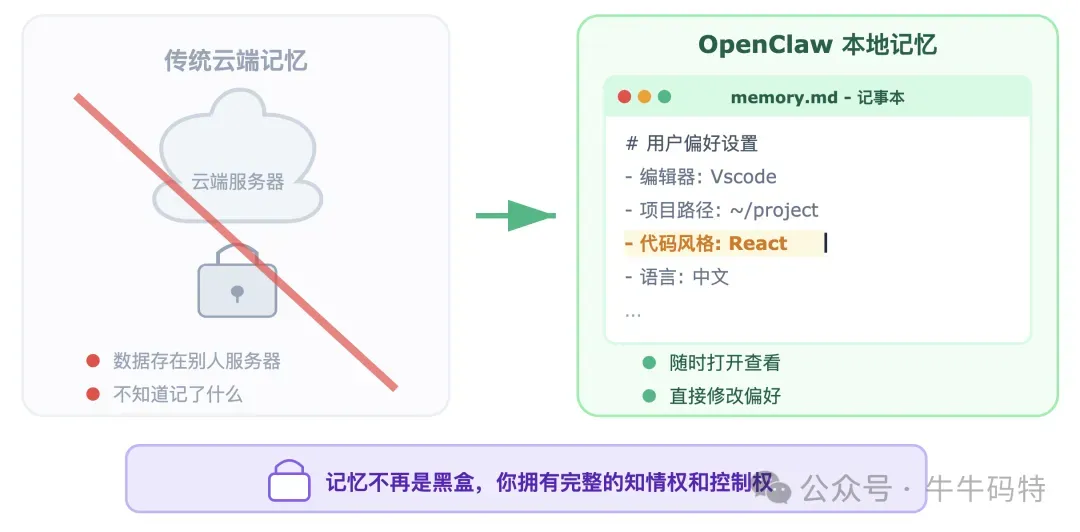
如果每次跟 OpenClaw 对话都像第一次见面,记不住上下文,用起来就会很麻烦。OpenClaw 用一套本地记忆系统来解决这个问题。简单来说,它会把你每次说的话、做过的事、还有你的喜好,全都记下来。这些记录会以普通记事本文件(Markdown)的形式,一直保存在你电脑硬盘上。 同时,它还会用数据库(SQLite)和一种能把文字转成数字的特殊技术(向量嵌入)给这些记录做索引,这样它就能精准理解你的意图,快速找到历史信息。 用一个场景来说明:你今天跟 OpenClaw 聊了半个小时,提到"我平时用 Vscode 编辑器"、"我的工作项目在 ~/project"。这些信息会被写进记忆文件存在本地。 三周后,你开了一个新对话,让 OpenClaw "帮我看看代码有没有问题",OpenClaw 在组装工作简报时会检索历史记忆,发现"这个用户用 Vscode、项目在 project 目录" — 你什么都不用重复说,它就带着记忆干活了。 记忆文件存在本地还有一个好处:你可以直接打开来看,甚至手动编辑。如果它记错了什么,你可以直接改掉;如果你想让它记住某个固定偏好,直接写进文件就行。这不是藏在某个服务器里你看不到的黑盒,它的记忆对你完全透明,你有完整的控制权。 6
能力与风险并存的本地智能体
至此,整套流程就完整跑通了:听到指令、思考方案、调用技能执行、把关键信息记进记忆,方便下次使用。 OpenClaw 之所以能直接操作你的电脑,并不是靠什么黑科技,而是它从架构上就做了明确设计:本地运行、本地权限、本地执行,每一步都发生在你自己的机器上。 但这种强大也伴随着直接的风险:它能做的事,几乎和你本人操作电脑一模一样。一旦被恶意利用,比如遭遇提示注入攻击 — 在网页或邮件里藏入伪装指令,诱导 AI 做出危险操作,后果就和你把电脑密码交给陌生人差不多。 OpenClaw 的核心维护者在社区里直接说过: "如果你不懂怎么运行一个命令行程序,这个项目对你来说风险太大,不适合你用。" 4、别再搞混了!一篇讲透 OpenClaw、MCP、Skill、Agent 的关系