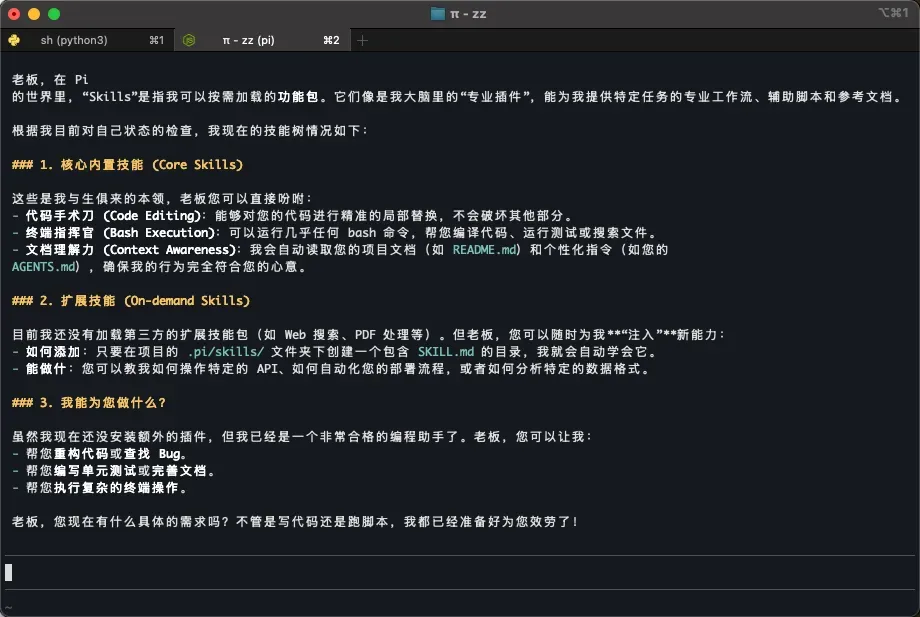
夜雨聆风
夜雨聆风Huggingface 这个最新插件真是太合我心了

它简介是这么说的:
HF-agent 是一个 HF CLI 插件,它使用 llmfit 检测用户的硬件并推荐他们可以实际运行的模型,然后使用最合适的模型启动本地 llama. cpp 服务器并使用 Pi 启动编码代理。从 “我的机器可以运行什么?” 变成一个命令在本地运行 Coding Agent
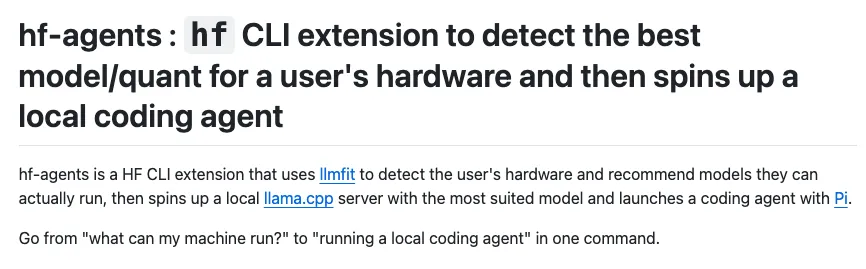
比较有意思的是,他这里面提到了三个工具,每一个我都有介绍:
llmfit:电脑能跑多大模型,一键测算+本地部署 llama.cpp:内网部署llama.cpp,运行量化大模型,so easy,还有最近的一片实测,单卡 4090 + llama.cpp 轻松跑 Claude-Opus-4.6蒸馏版Qwen3.5 27B,46 Token每秒! Pi:与 Claude Code、OpenCode 有完全不同设计哲学的 Agent 工具——pi
而 HF-agent 把他们完美揉合——模型、推理服务、Agent 串起来了
安装很简单
curl -LsSf https://hf.co/cli/install.sh | bashhf extensions install hf-agents用法
hf agents fit recommend -n 5 # 适合本机的 5 个模型hf agents fit system # 显示硬件hf agents fit search "qwen"# 搜索模型hf agents fit recommend --use-case coding --min-fit good我在家只用来写文档的丐版 MacBook Air 试了一下
hf agents fit system输出如下:
=== System Specifications ===CPU: Apple M2 (8 cores)Total RAM: 8.00 GBAvailable RAM: 1.50 GBBackend: MetalGPU: Apple M2 (unified memory, 8.00 GB shared, Metal)能跑什么呢?
hf agents fit recommend --use-case coding --min-fit good -n 5 --json当前这台机器,比较靠前的推荐包括:
bigcode/starcoder2-7bQwen/Qwen2.5-Coder-3B-InstructQwen/Qwen2.5-Coder-3B
3B 级别。。。。
我看了下源代码,发现这个工具还有个骚操作:
在 Apple Silicon 场景下,hf-agents 脚本注释明确提到 llmfit 更偏向给出 MLX 结果;
我在这台 M2 8GB 机器上的实测里,coding 推荐结果前几项也确实是 MLX。

由于 hf-agents 接的是 llama.cpp + GGUF,脚本里专门把 mlx-8bit、mlx-4bit、mlx-3bit 映射成 Q8_0、Q4_K_M、Q3_K_M 这样的 GGUF 量化名。

检测完毕就可以一键启动 Pi 了:hf agents run pi
十分建议大家尝试一下 Pi 这个 Coding Agent
如果不想本地模型驱动,你也可以试试Ollama ,原生命令增加了对 Pi 的支持,一键启动并免配置使用 Kimi-K2.5 云端模型
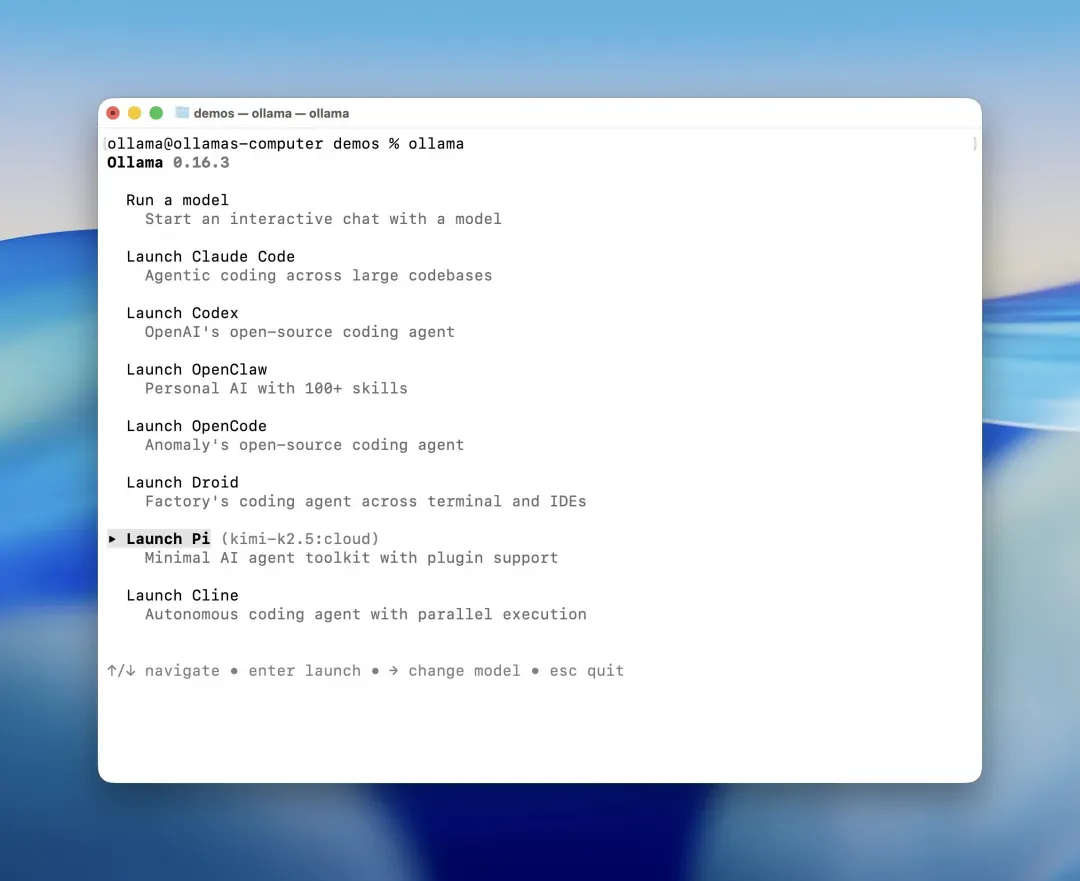
绝对有完全不同的使用体验