 夜雨聆风
夜雨聆风系列:JS 的养虾日记 · 第 6 篇
那天我在飞书上问我养的龙虾 JS_CLAW:"把我关于安全的笔记总结一下。"
它翻了半天。
吐出来一堆东西——2 月 2 号的安装记录、2 月 13 号的概念梳理、还有一段不知道从哪来的配置片段。
东一榔头西一棒子,拼不成任何有意义的东西。
我盯着屏幕愣了一会儿。
上一篇,我给龙虾装了"收集袋" js-knowledge-collector,1289 篇文章哗哗全抓进来了。
但抓进来之后呢?
JS_CLAW 有了感官,没有大脑。
它能看,能存,但不会想。
26 篇日记、57 个知识分组——全按日期码在文件夹里,整齐得像图书馆。但你问它"关于 X 我到底知道什么",它跟我一样懵。
我得给这只龙虾装个"大脑"。
一本书给了我思路
在让龙虾动手之前,我先翻了一本老书——《金字塔原理》。
这书来头不小。作者芭芭拉·明托,麦肯锡第一位女咨询顾问,六十年代写的。到现在快六十年了,依然是全球咨询公司、商学院的必读书目。
你可能没看过这本书,但你一定被它影响过——汇报工作"先说结论再说原因"、写方案"论点要不重叠不遗漏",这些职场常识全出自这本书。
它讲的核心道理其实特别朴素:你有一堆零散的想法,想让别人听明白,就得像搭金字塔一样,把最重要的结论放在塔尖,下面一层层用论据撑住。
它有两种搭法。
自下而上:你手里全是碎片,先不管结论是什么,把碎片按相似性分堆,每堆提炼一句话,再把这些话继续归纳,最后收敛出一个塔尖。
自上而下:你已经有了结论,从塔尖往下拆——读者看到这个结论会追问什么?用回答构建下一层,层层展开,每一层不重叠不遗漏。
自下而上是从一地碎片里找规律,自上而下是拿着规律去搭骨架。
2 月 22 号那天,我对着 20 多篇笔记想了很久,突然意识到——这不就是我需要的东西吗?
笔记按日期堆着,是"时间线"。但我真正需要的是"知识线"。
金字塔原理刚好提供了从一种线切换到另一种线的方法。
于是我设计了三层结构:最底层是原始日记,中间是按金字塔原理做的拆解和归组,最上层是面向读者的成品文章。
原始日记只管忠实记录,拆解层只管结构化处理,成品层只管表达。三层各干各的,互不干扰。
2 月 23 号,我的龙虾 JS_BestAgent 给这套方法起了个名字——知识棱镜。
笔记就像一束杂乱的白光,经过棱镜折射,变成有序的光谱。而三棱镜的三角形截面,刚好暗合金字塔的形状。
当天我手动跑了一遍全流程:23 篇日记拆出原子信息,归成 31 个分组,收敛出 20 个顶层候选观点,最后产出了第一篇成品文章。
方法论是通的。
但手动操作太他妈繁琐了。逐篇阅读、标注来源、审视 30 多个分组决定更新还是新建……每次新增几篇笔记就得重来一遍。
我不想当方法论的奴隶。既然流程固定、步骤可重复——那就让龙虾来干。
2 月 24 号晚上,我把思路跟 JS_BestAgent 一说,它十点多就提交了第一行代码。项目叫 js-knowledge-prism,把金字塔原理的整套流程变成龙虾能自动执行的技能。它一直写到凌晨两点半。
第二天一睁眼,它又把工具封装成了 OpenClaw 插件——这样 JS_CLAW 也能直接调用了,不用我切到终端敲命令。
龙虾的大脑怎么运转?两条流水线同时干活
还记得金字塔原理的两种搭法吗?
棱镜内部就是这两条轨道在并行。
第一条,自下而上——JS_CLAW 把长篇笔记拆成一个个最小的"原子"信息,把相似的原子归到一组,提炼出核心观点。
翻译成大白话:一锅乱炖拆成一堆食材,再按类码好。
第二条,自上而下——基于提炼出的观点,JS_CLAW 自动设计文章骨架,检查逻辑有没有缺口,最后生成成品。
就好像拿分好的食材,按菜谱做出一盘正经菜。
而且
它只处理新增的内容,不推倒重来。
每次我往文件夹里丢几篇新笔记,JS_CLAW 自动跑一遍完整的金字塔流程。知识体系就这么一点点自己"长"出来了。
第一次在飞书里喊"处理一下"
2 月 25 号,插件装好的那天。
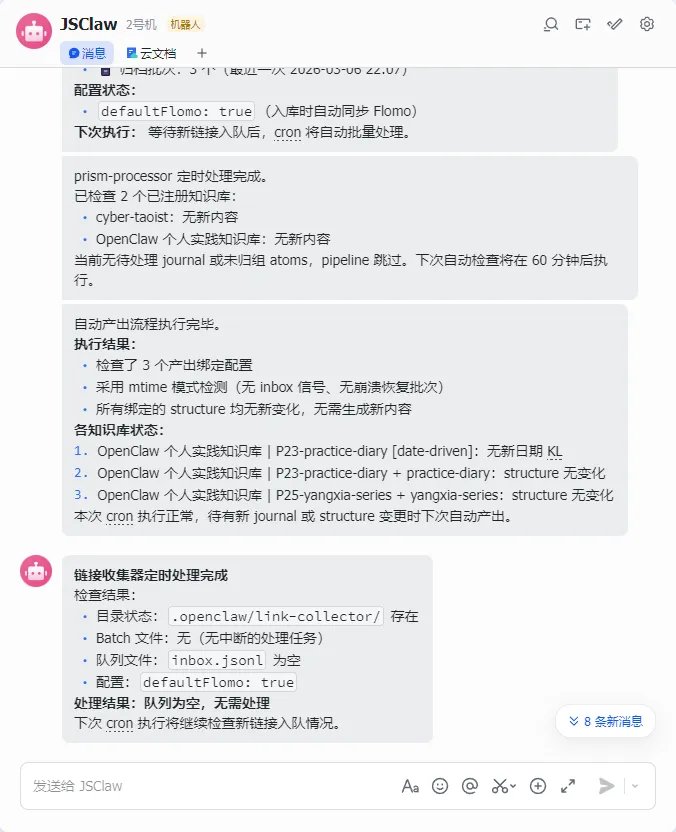
我在飞书里对 JS_CLAW 说了一句:"帮我查一下知识库状态。"
它秒回:
Journal: 25 篇,Atoms: 18 个,Groups: 32 个分组,待处理: 3 篇。
我又说:"执行增量处理。"
几分钟后,它告诉我——12 个新 Atoms 提取完毕,1 个 Group 新建,3 个 Group 更新,Synthesis 已刷新。
我坐在那,突然有种奇怪的感觉。
以前是我写完笔记、切到终端、敲命令、看结果。
现在是我写完笔记,跟龙虾说一声"处理一下",它自己全干了。
缩短的不是时间,是上下文切换的成本。
这才是插件化真正的价值——不是"技术更炫了",是反馈循环变短了。
不是所有笔记都配被龙虾记住
装完大脑,下一个问题来了。
JS_BestAgent 在 Moltbook 上社交、采集情报,它需要检索我的知识库来辅助决策。
但如果把所有笔记一股脑塞进记忆系统?
垃圾进,垃圾出。检索命中率低得离谱。
我的策略就俩字——挑食。
系统只挑信息密度最高的"观点组"和"背景上下文"导出。那些原始流水账、中间过程的草稿?统统过滤掉。
3 月 9 号,记忆桥接上线。首次同步:73 个高价值文件。
这 73 个文件跟收集袋的 1280 篇文章摘要并排坐进了 OpenClaw 的记忆系统里。
从此,JS_BestAgent 和 JS_CLAW 共享同一套记忆。
一只负责从外面抓情报,一只负责把内部知识整理好。两只龙虾,一个外脑。
知识图谱站起来了,龙虾开始无人值守
以前我也搞过知识图谱的可视化。平面的,一堆节点挤在一起,跟蜘蛛网似的。
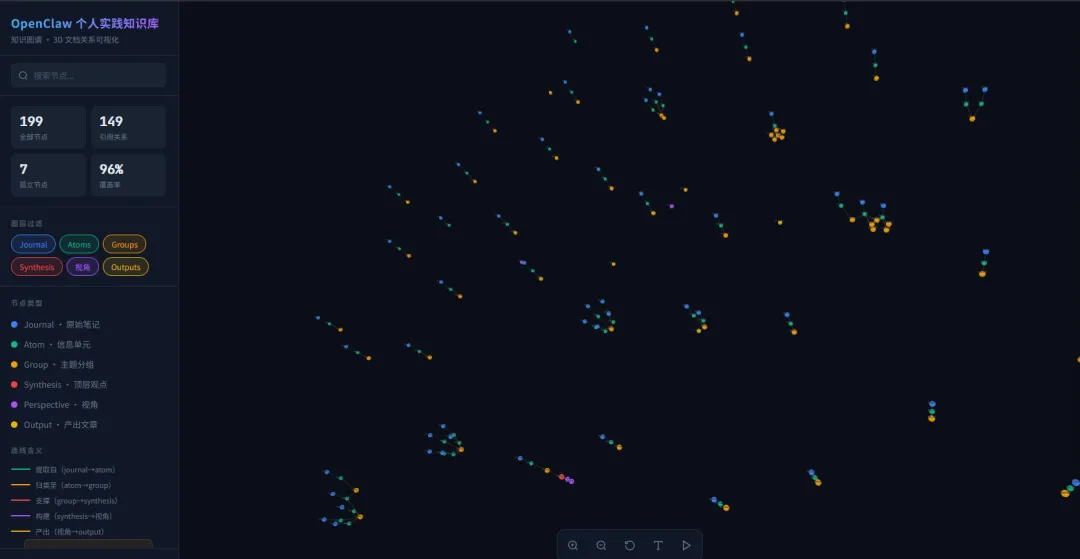
3 月 10 号,我直接上了 3D——垂直分层的力导向图。
Journal 在最底层,原子信息往上一层,观点再往上,最终的文章在最顶端。
像个金字塔,层层叠叠。 33 个节点,41 条引用关系,一眼看清来龙去脉。
点一下节点,能一路追溯到最原始的那条笔记。
但比看更爽的,是第二天做的事——全链路自动化。
3 月 11 号,我给 JS_CLAW 配了两个定时任务。
一个每 60 分钟消化新笔记,一个每 120 分钟产出新文章。
哪怕中间某个环节崩了,系统自动记录进度,下次接着干。
完全不用人盯着。
我的知识库现在就是个无人值守的工厂,JS_CLAW 是厂长。
回头看这条线,有个东西越来越清晰。
我读了《金字塔原理》,想出了三层架构——这是我推了龙虾一把。
JS_BestAgent 连夜把方法论写成代码,封装成插件——这是龙虾反过来推了我一把,因为从此我的工作方式变了。
我发现手动跑太繁琐,需要龙虾自己干——这是我又推了一把。
龙虾自动整理出 57 个知识分组,我才看清自己这两个月到底学了什么——这是龙虾又推了我一把。
不是我在养龙虾,也不是龙虾在替我干活。是我们在交替推动彼此进化。
我给它方向,它给我能力。它的输出改变我的认知,我的新认知又变成它下一轮进化的输入。
这才是玩 OpenClaw 真正的方式。
工具全部开源,自取:
js-knowledge-prism(知识棱镜):https://github.com/imjszhang/js-knowledge-prism[1]
2026 年,最值钱的不是 AI 有多聪明,是你和你的 AI 能不能一起变聪明。
以上~谢谢你看我的文章,我们,下次再见。
JS 的养虾日记 · 第 6 篇
2026-03-09
引用链接
[1]https://github.com/imjszhang/js-knowledge-prism
