 夜雨聆风
夜雨聆风2026 年开年,中国互联网大厂集体做了同一件事——养龙虾。
腾讯一口气推出了三款产品:QClaw、Lighthouse、WorkBuddy,分别面向个人用户、开发者和企业。马化腾亲自转发相关内容,深圳总部甚至排起了千人长队体验安装。
月之暗面的 Kimi Claw 直接在网页端一键部署,号称一分钟搞定,电脑关机还能在云端继续跑。MiniMax 的 MaxClaw 直接集成在自家 Agent 网页端,不需要服务器也不需要 API Key。
智谱做了客户端版本,百度做了零部署托管服务,字节的飞书 ArkClaw 也上线了,连七牛云都推出了支持 9 大聊天渠道的 LinClaw……
腾讯云首页
整个行业的节奏,用一位知乎作者的话说: “相当于所有人同时收到了同一份竞品分析报告,然后各自冲进了研发室。”
但如果你仔细看,会发现一个有意思的事:大多数产品做的事情几乎一模一样。
帮你在云端部署一个 OpenClaw → 绑上自家的 AI 模型 → 接上微信或飞书 → 收你一个月一两百块的订阅费。
本质就是:OpenClaw 是一道菜的食谱,大厂做了个“预制菜”卖给你。
这场混战中,大家抢的是用户、是 Token 消耗量、是 Agent 入口。
OpenClaw 的价值非常多,它包括浏览器操控,包括多渠道接入,也包括技能市场,它实现了agent“能帮你干活”这件事本身。
但它更深层次的价值在于:
第一次让普通人看到,AI 对你的了解,可以存在你自己手里。
这句话什么意思?往下看。
在聊大问题之前,我们先看一个具体的东西
OpenClaw 的工作区里有一个文件叫
用户偏好
喜欢简洁沟通,不爱听寒暄废话
工作汇报偏好用表格,不要长篇大论
每天早 9 点到晚 11 点活跃
工作情况
正在负责 Q2 市场推广方案
用飞书和 Notion 协作
上司是张总,汇报时要多用数据说话
重要记录
1 月 15 日:客户 A 觉得上次方案太贵
2 月 3 日:新供应商签约了,合同到年底
就是这么朴素。没有什么向量数据库、没有知识图谱、没有高深的技术架构——就是一个普通的文本文件,记录了 AI 对你这个人的理解。
而且这个文件存在你自己的电脑上。你可以打开看,可以手动改,可以复制到 U 盘里带走。
这件事为什么值得单独拿出来说?
因为在 OpenClaw 之前,所有 AI 产品对你的了解,都锁在它们自己的服务器里。
ChatGPT 记住了你的偏好?→ 存在 OpenAI 的云端,你看不到具体内容 Claude 了解了你的工作方式?→ 存在 Anthropic 的系统里,你带不走 Kimi 对你的理解?→ 存在月之暗面的数据库里,你没法检查它到底记对了没有

openai官网关于数据存储的回答
你不知道 AI 记住了什么(可能记错了),你没办法修正它的理解(可能有偏差),更没办法把它搬到别的平台去。
OpenClaw 第一次把这种控制权还给了用户。
虽然方式很粗糙——就是一个 Markdown 文本文件——但它传递了一个理念:
AI 对你的了解,应该属于你,不属于某个公司。
而现在大厂们蜂拥做“国产龙虾”时,恰恰是在反方向走——它们把 OpenClaw 本来存在你电脑上的记忆,搬到了自家的云端服务器。你的 AI 记忆从
方便了吗?确实方便了。但代价是什么?这就是接下来要聊的。
想象一下两年后的场景
你已经深度使用了某个 AI 助手整整一年。它记住了你几百个客户的脾气,你几千次开会的决策,你处理各种棘手问题的套路,甚至知道你疲倦时容易在邮件里写错别字。
这时候,市面上出了一个明显更好的 AI——更快、更准、还便宜一半。你想换。
但换了之后,新 AI 对你一无所知。它不认识你的客户,不了解你的项目,不清楚你的习惯。要重新“培养”它到现在这个水平,又得花好几个月。
你被困住了。 不是因为现在的 AI 有多好,而是因为换的代价太高。
这跟十年前换手机一模一样。那时候从 iPhone 换安卓,意味着照片没了、聊天记录没了、App 配置没了。很多人不是不想换,是换不起。
而 AI 记忆的迁移,比手机数据迁移难一百倍。照片是标准格式的,一张张拷过去就行。但“AI 对你这个人的理解”是模糊的、上下文相关的、很难用统一格式描述的。
更要命的是,这种“困住”会越来越严重——
AI 从“偶尔问一下”变成了“每天一起工作八小时”,积累的信息量完全不同 手机、电脑、眼镜、耳机上都有 AI,但它们各自独立、互不相通 公司的业务流程开始跑在 AI 平台上,换平台成本高到老板不敢想
简单说: AI 越了解你,你就越走不掉。
而大厂们现在做的,恰恰是在加速这个“走不掉”的过程。
“用户被平台锁住”这件事不新鲜,跟大家聊三个故事
1980 年代,每个网络公司都有自己的邮件系统,互不相通。AOL 用户只能给 AOL 用户发邮件,CompuServe 只能发给 CompuServe。后来 SMTP 协议统一了标准,任何邮箱都能给任何邮箱发邮件。
为什么能成? 因为那时候没有任何一家公司大到能独占市场。你坚持封闭,用户就只能跟你自己的用户通信,体验差,人就走了。所以大家被迫选择互通。
这对 AI 的启示:如果市场分散,行业可能自发走向标准化。但如果某几家巨头已经锁定了大部分用户,它们就没动力开放了。
换运营商可以不换号码,这件事听起来理所当然。但运营商恨透了这个政策。“换号码太麻烦”是它们留住用户最好的武器——你的号码绑着所有朋友、客户、银行、快递,你换得起吗?
所以手机号携带不是运营商“想通了”,而是被政府强制的。
美国 FCC 2003 年强制实施
中国工信部 2019 年全国推行
这对 AI 的启示:当 AI 助手变成数字生活的基础设施,政府很可能会出手。欧盟 GDPR 已经有“数据可携带权”的条款了——公司必须在用户要求时把数据以可读格式导出。这个法规目前还没明确覆盖“AI 记忆”,但方向已经很清楚了。
Linux 的故事最励志。没有政府逼微软支持 Linux,也没有行业协议。一个芬兰大学生写了个系统内核,全世界的程序员一起完善它,最终从玩具项目变成了全球服务器的主流系统。
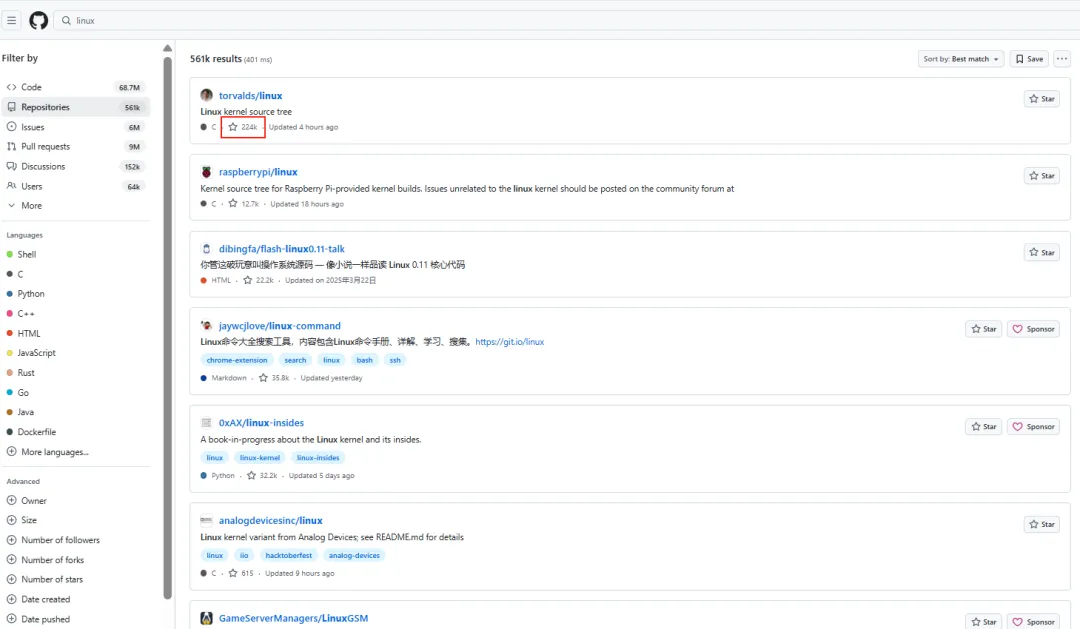
github上Linux的star数已经达到22.4w
github上Linux的star数已经达到22.4w
微软不是“妥协”了,是发现自己的 Azure 云上 Linux 用量超过了 Windows——不适配就是跟钱过不去。
那 AI 这次最可能走哪条路?
我的判断:短期靠开源社区先做出来,长期靠政府监管倒逼巨头跟进。
指望巨头自己开放是很难的,对他们来说,没有足够的利益驱动,是绝对不可能去主动拆自己的围墙的。但如果开源社区先把标准做出来、用户先用起来,形成一定的规模,再加上政府看到“AI 锁定效应”对市场竞争的伤害而出手干预——两股力量合在一起,事情就有可能成。
说了这么多“应该做”,那到底要做什么?
一套让 AI 记忆可以自由迁移的标准,至少要解决四件事:
存在本地电脑最安全,但电脑坏了就没了 存在云上方便同步,但又被云服务商绑定了 目前最务实的折中: 端到端加密的云同步 ——数据在云端但只有你能解密
今天用 Claude,明天想换 GPT。你的记忆数据不能包含“只有 Claude 才懂”的内容,必须是任何 AI 都能理解的通用格式。这也是为什么自然语言写的 Markdown 比某种专有格式更有前途。
你可以随时导出全部 AI 记忆 你可以随时删除 你可以随时决定谁能看到
你今天觉得华为的智能眼镜好用,就用华为的眼镜跟 AI 对话。明天觉得苹果的手机更顺手,就切到苹果手机。后天发现某个新模型特别聪明,一键切换。
无论你换什么设备、换什么模型、换什么平台——
这对行业意味着什么?
手机厂商不能再靠“你的数据在我这里跑不了”留住你了,必须靠硬件真的好用 AI 模型不能再靠“绑在某个平台里”获客了,必须在能力上真的比别人强 Agent 软件不能再做“什么都行但什么都一般”的大杂烩了,必须在自己的领域做到极致
竞争的本质从“谁锁得住用户”变成了“谁服务得好用户”。
对用户是大好事。对行业里的平庸产品是末日——用户可以自由流动时,会毫不犹豫地涌向最好的那个。
谁来做这件事?
大公司不会主动做。 你能自由离开就等于它没有了护城河,这不符合商业逻辑。
开源社区最可能先动手。 OpenClaw 已经种下了种子,它的 Markdown 记忆方案虽然粗糙,但让几十万用户第一次体验到了“AI 记忆存在自己手里”的感觉。如果有人在这个基础上做出更完善的标准,就会形成事实标准。
小公司反而有动力推动。 对小型 AI 创业公司来说,“你的数据随时可以导出,换任何平台都能用”反而是卖点。用户最怕小公司倒了记忆就没了,承诺可携带反而降低了信任门槛。
政府最终会出手。 当 AI 助手深入到足够多人的日常生活,当“换平台”的成本高到限制市场竞争,监管就会来。就像当年强制手机号携带一样。不是“会不会”的问题,是“什么时候”的问题。
所有大厂都在抢着做 OpenClaw 的“预制菜”版本。它们看到了 Agent 入口的价值、Token 消耗的营收、用户数据的壁垒。这些都没错。
但它们几乎都忽略了 OpenClaw 最有远见的那个设计:一个存在你自己电脑上的
这个文件很小、很粗糙、很不完美。但它做对了一件事——
让人们看到了一种可能性:我的 AI,可以属于我。
SMTP 统一了邮件,让你可以用任何邮箱给任何人发邮件。手机号携带让你可以换运营商不换号码。
下一个被标准化的,也许就是你的 AI 身份——
让你带着你的 AI,自由穿梭在任何设备、任何模型、任何平台之间。
这颗种子已经种下了。至于什么时候长成大树,取决于开源社区能不能做出足够好的标准,取决于政府什么时候出手,也取决于越来越多的人开始问出那个关键的问题:
凭什么我的 AI 记忆,不能带走?
