 夜雨聆风
夜雨聆风最近被朋友圈的"养龙虾"刷屏了,OpenClaw这玩意儿到底能干嘛?我也挺好奇,正好手头有台MacBook Pro M4(24G内存+512G存储),干脆把现在主流的几种玩法都试了一遍,纯当给大家踩踩坑。
第一种,腾讯Qclaw:微信入口真方便,就是还在内测
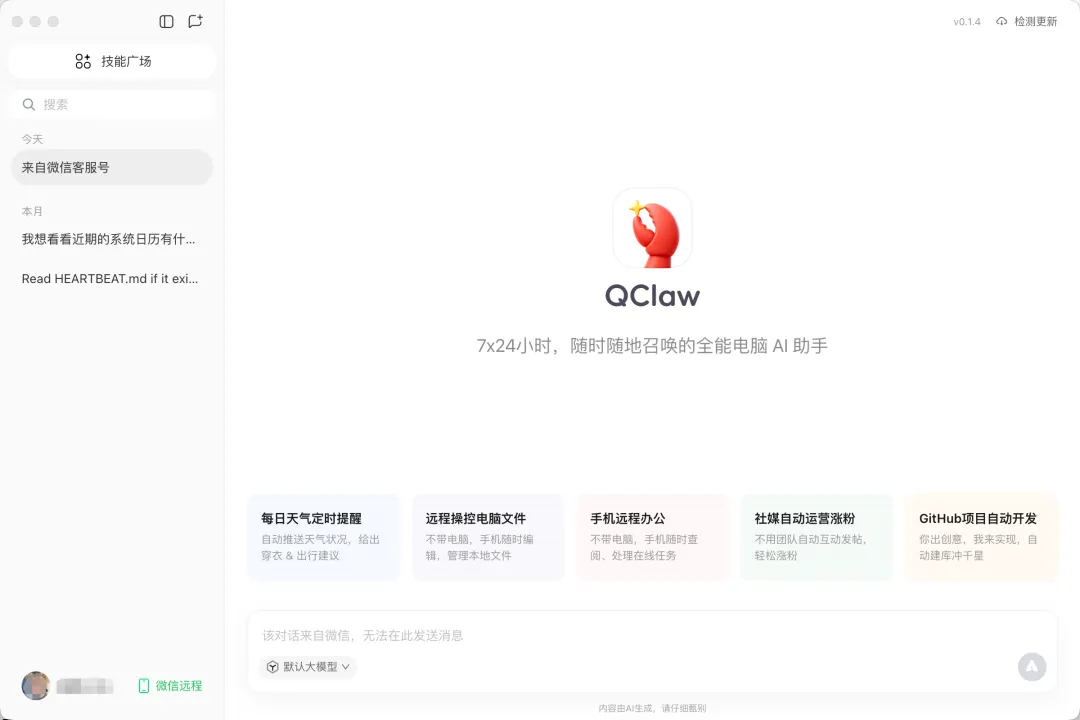
先试了腾讯出的Qclaw。安装确实简单,一键搞定,没怎么敲命令,这一点对新手挺友好。它的思路很清晰:通过微信发指令,程序在本地运行,说白了就是给微信加了个远程控制本地电脑的AI能力。
我让它帮我整理下载文件夹、找个历史文档,大部分时候都能完成。出门在外想控制家里电脑,这个功能确实实用。
缺点就是还在内测(发稿时已经开始公测了),功能不全——定时任务这些界面上都还没做出来。而且默认调用腾讯云端大模型,走API,虽然现在不收费,但Token消耗挺快,未来怎么收费还不好说。
总的来说,懒人可以先试试这个,装完就能玩,不用折腾环境。
第二/三种,飞书OpenClaw:两种方式,一个直接要氪金,一个体验还可以
飞书这边我试了两种不同的玩法,体验差得挺多:
1. 第一个是飞书官方集成的云端版本:它在云端给你开个虚拟机跑,不用你本地有性能。刚进去体验确实不错,不用配置,直接在飞书里就能用。结果我就让它处理了两个文档,不到十分钟——**积分没了,提示要充值**。
这个收费节奏我只能说,玩不起。好处也有,虚拟机运行,不碰你本地文件,安全性确实高,但就是太贵了,偶尔用用还行,长期玩真心疼。
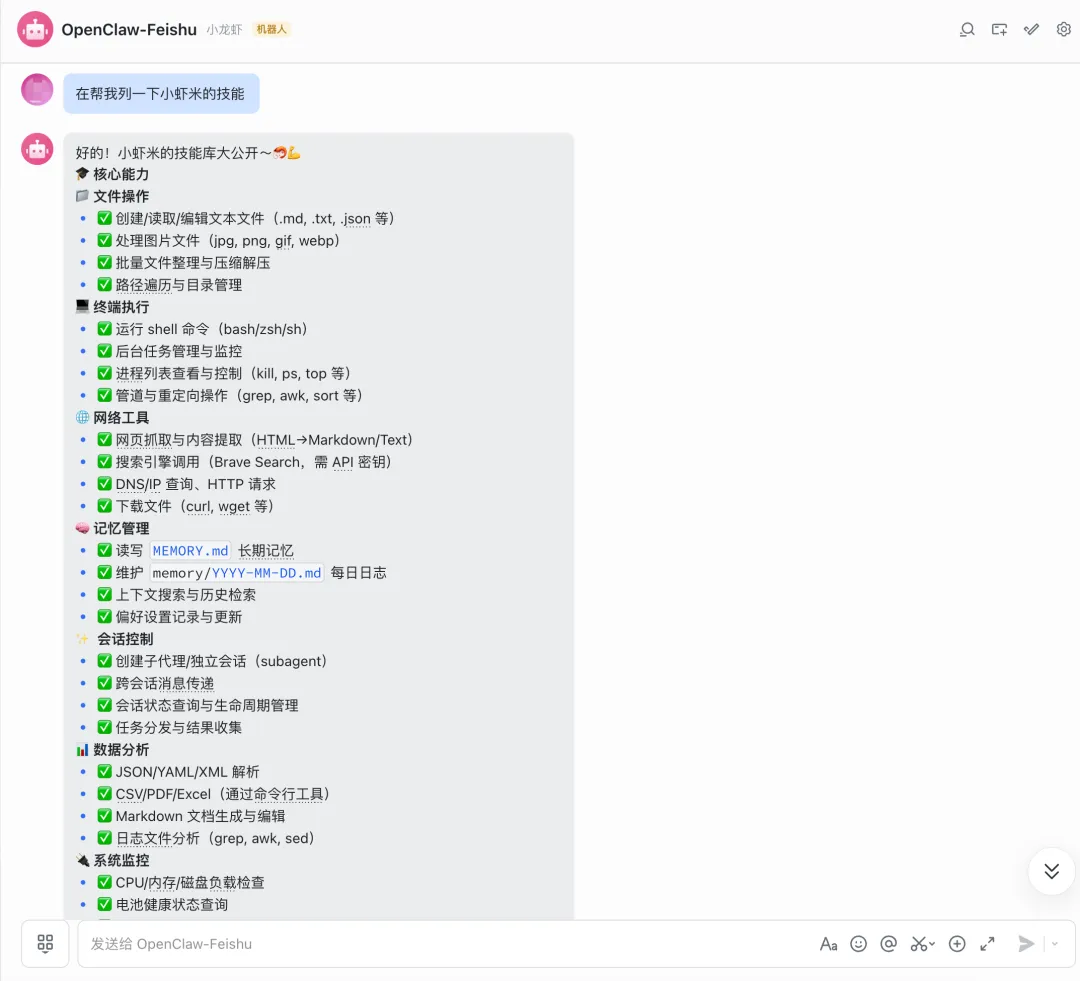
2. 第二个是飞书调用本地OpenClaw:这个就舒服多了,不花钱,就是得自己先把本地环境搭好,再给飞书打通接口。装好之后体验真的顺滑,飞书本来就是办公用的,在聊天框里直接指挥AI干活,整理数据、处理文档都挺方便。
第四种,纯本地部署:Ollama跑Qwen3.5:9B,免费但有瓶颈
最后试了最折腾的纯本地部署:Ollama + Qwen3.5 9B。
装的过程确实劝退新手,要敲不少命令,配置一堆东西,折腾了半天才跑起来。但跑完那一刻的爽快感是真的——完全免费,所有数据都在你自己电脑上,想怎么玩就怎么玩。
M4Pro跑9B模型速度我能接受,日常简单任务够用,当然不能跟云端大模型比,参数摆在那儿。大模型运行时内存占用能跑到90%以上,之前有人说Mac统一内存会爆,我实际用下来根本不是这么回事——24G内存完全hold得住,跑起来内存占用确实比普通软件大,但远没到"高到爆"的程度,统一内存架构效率还是挺高的,我24G内存开着其他软件也没问题,日常使用不影响。
问题也很明显:本地硬件限制,你跑不动更大的模型。9B参数对付简单任务还行,复杂推理、长链路规划就有点力不从心了。想要更好效果,还得上更大模型,但更大模型本地硬件顶不住。这就是本地部署最大的瓶颈。
聊个我觉得最理想的玩法,逻辑上说得通
折腾这一圈下来,我觉得如果真要玩明白了,长期用,有一个方案其实性价比最高:
"整个MacMini,OpenClaw部署在本地,然后接入付费云端大模型API"。
为啥说这个方案好?
1. MacMini太适合了:性能够,M芯片对AI支持好,关键是"功耗低"——几十瓦,长期开机不心疼,放家里角落不占地方,几乎没噪音,就是为这种场景量身定做的;
2. "本地跑OpenClaw":该有的能力都有,能操作本地文件,能24小时后台跑定时任务;
3. "推理交给云端大模型":想用GPT-4o还是Claude 3随便选,效果肯定比本地9B小模型好太多。
唯一缺点就是Token消耗真的高。OpenClaw本来推理链条就长,一轮规划反思下来,Token走得飞快,重度使用一个月API账单也挺好看。但话说回来,效果确实是最好的,一分钱一分货。
这大概也是最近MacMini卖得好的原因之一吧——需求真的上来了,正好它对位对得准。

最后给想浅玩的朋友几点建议
我这也就是浅玩三天,给想入坑的朋友总结几句:
1. 纯好奇想试试:从腾讯Qclaw或者飞书云端版开始,不用折腾,先感受下这玩意儿到底能干嘛,不喜欢直接卸载,没成本;
2. 想长期玩又不想花钱:自己本地部署吧,16G以上内存就能跑9B模型,Mac完全没问题,内存没传言中那么不堪;
3. 当真要用它干活:可以考虑整个低功耗迷你主机(MacMini就是好选择)专门部署,再接付费大模型,体验最好,就是Token花费会高一些;
4. 期望值别拉太满:这东西现在还在早期,偶尔理解错指令、跑一半卡住都是正常的,别指望它能完全替你干活,现在就当个"会干活的实习生"用就行。
OpenClaw方向肯定是对的——AI直接在你电脑上动手干活,而不是光跟你聊天。但现在确实还在早期,各种方案都有优缺点,找到适合自己需求的玩法最重要。
先浅玩着,等后续更新吧。
