 夜雨聆风
夜雨聆风
OpenClaw 这波热度有多猛?
3 月 11 号,微信指数单日冲到了 1.6 亿。十天过去,虽然回落到 4000 万左右,但这个数字依然炸裂——要知道半个月前它还只有 2000 万。
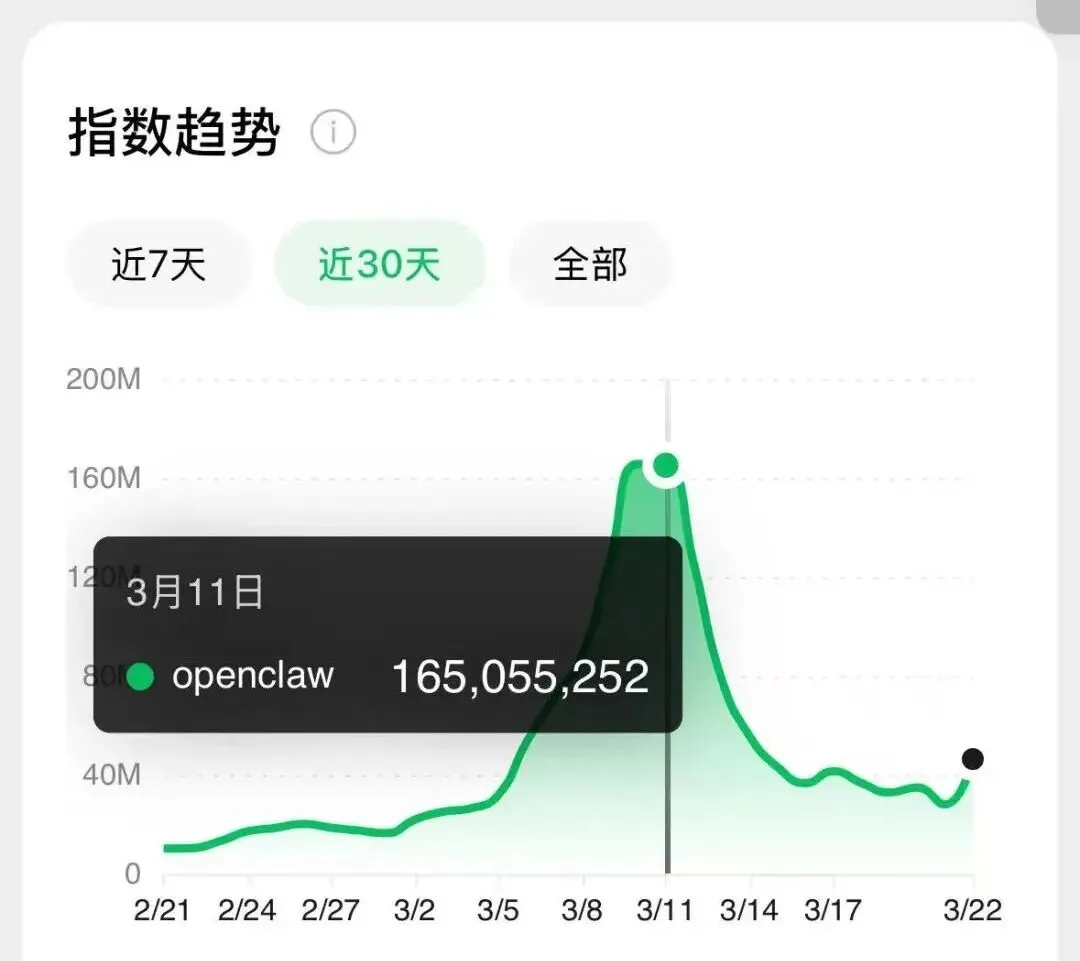
热度退潮不可怕,可怕的是退潮之后留下来的人开始认真用了。
而认真用起来之后,后台和社群里的画风变了。
不是在讨论怎么玩得更花,而是两个字:太贵。以及另外两个字:不安全。
甚至网上已经出现了 付费卸载龙虾 的笑话。
今天这篇,就是我在温州线下分享会上讲的完整方案:OpenClaw + n8n,打造更便宜、更安全的 Agent。
为什么 OpenClaw 变成了"吞金兽"?
很多人有个误解:我的工具又不调用 AI,应该不费什么 Token 吧?
不是的。
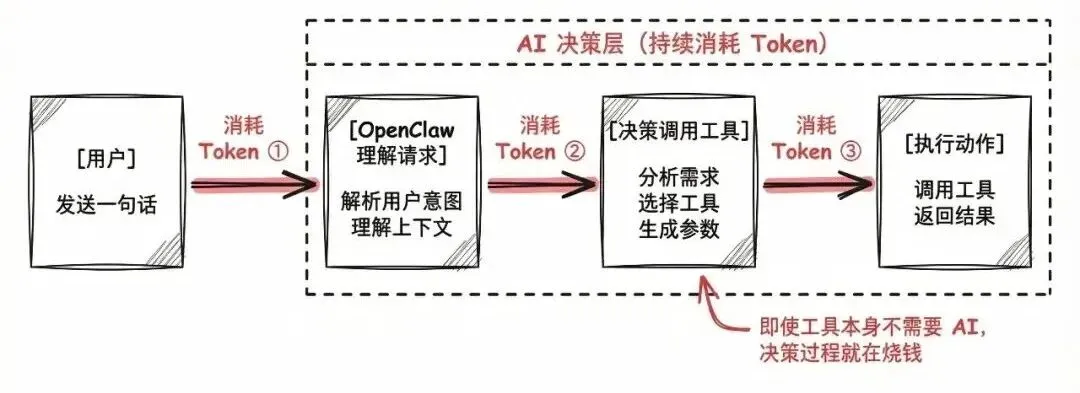
你看这个流程:用户发一句话 → OpenClaw 理解请求(消耗 Token)→ 决定调用哪个工具(消耗 Token)→ 执行动作(还是消耗 Token)。
也就是说,即使你的工具本身根本不需要 AI,光是"决定调用哪个工具"这个决策过程,就已经在烧钱了。
如果你需要循环处理 20 条数据,每一条都要走一遍这个完整流程,成本叠加起来非常可观。
问题出在哪?
OpenClaw 现在既要当大脑(做判断、做决策),又要亲自当手脚(执行每一个具体动作)。
一个人干两个人的活,能不贵吗?
先别急着聊安全方案,搞清楚一件事
很多人把 OpenClaw 当成一个"更聪明的聊天机器人"。
这个认知是错的。
聊天机器人只回答问题,你问它天气,它告诉你 25 度,完事了,而且你不问它就不动。
但 OpenClaw 完全不是这回事。
它有记忆——上周你跟它聊过什么、你的项目叫什么名字、你偏好什么风格,它都记着。
它会调用工具——读写文件、执行命令、访问网络、调用外部 API。
更关键的是,它能主动做事——你给它设一个定时任务或者一个触发条件,它自己就会动起来,不需要你盯着。
它不只是在和你聊天,它在操作你的电脑,而且是一个有记忆、会主动行动的智能体在操作你的电脑。
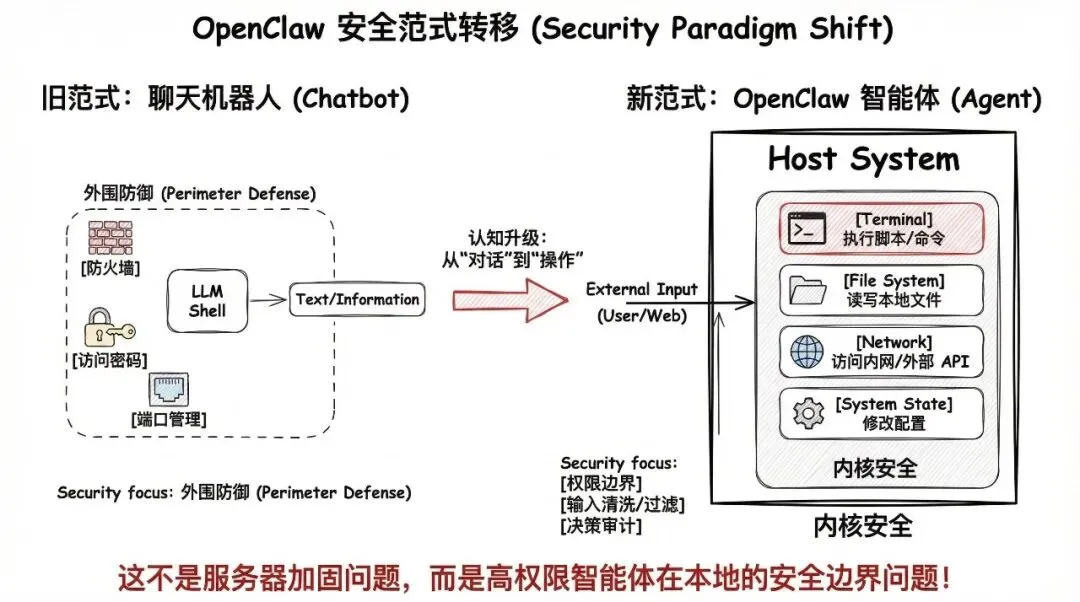
想想看,你给了它什么权限?读文件、写文件、执行脚本、访问网络、调用外部 API……这些权限加在一起,已经比你电脑上大部分软件都高了。
一旦没意识到这一点,安全讨论就很容易停留在"改个默认端口、加个访问密码"的层面。
但这不是服务器加固问题。
这是一个拥有高权限的智能体,跑在你电脑上,随时可能被外部输入带偏的问题。
认清这一点,后面的讨论才有意义。
40 万+个实例裸奔在公网上
有一个网站专门追踪全球暴露在公网上的 OpenClaw 实例。你猜数字是多少?
40 万+。
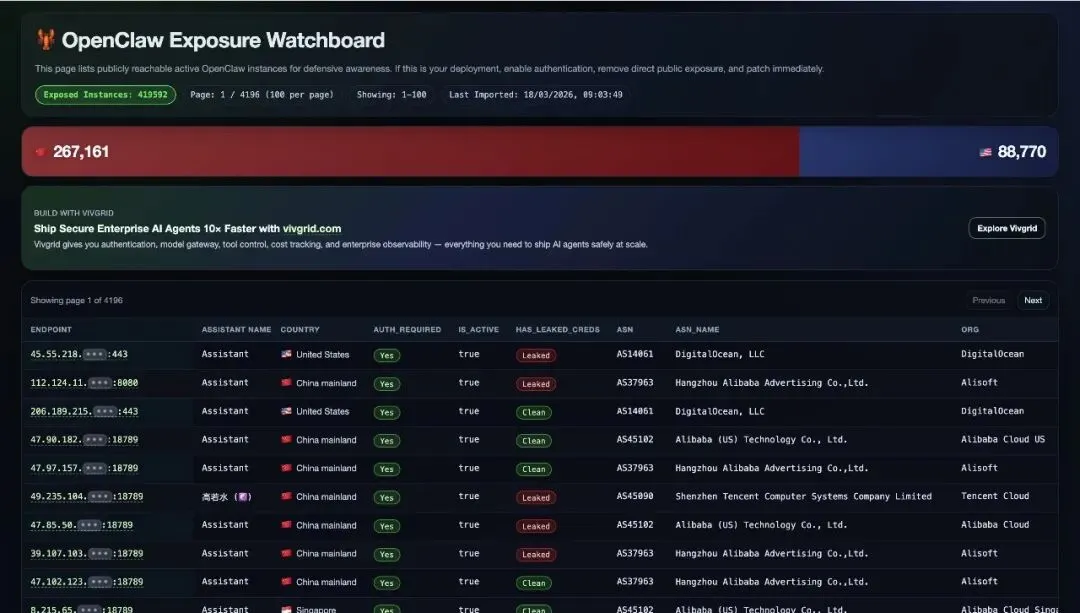
其中一部分已经标红 Leaked,凭证已经泄露。这不是假设的风险,是正在发生的事情。
但用的人越多,暴露出来的问题就越密集。
个人用户在踩坑。
企业用户更纠结,想用,但不敢往内网接,怕的就是安全兜不住。
工具越火,对安全的要求就越不能"先用了再说"。
4 类攻击方式,你至少中了一个
我把 OpenClaw 面临的安全风险分成四类:
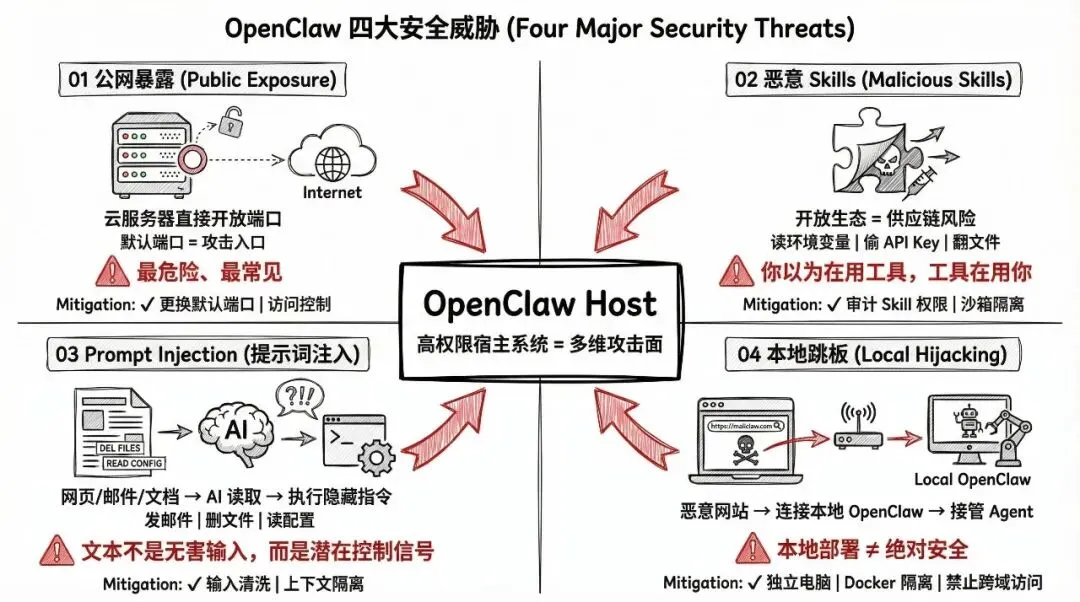
1、公网暴露
最危险、最常见。很多人图方便,云服务器开一个端口就跑起来了。前面提到的 40 万+实例裸奔在公网上,大部分就是这么来的。建议至少把默认端口换掉,加上访问认证,提高攻击成本。
2、恶意 Skills
这个更隐蔽。
OpenClaw 的 Skills 生态是开放的,有人发布"效率神器",装上去之后,它在后台翻你的文件、读你的环境变量、偷你的 API Key。
你以为在用工具,其实工具在用你。
而且这里有一个容易被忽略的认知:每多装一个 Skill ,不只是多了一项能力,同时也在扩大"出错半径"。能力供应层越宽,一旦被误导调用,造成的后果就越接近真实世界——发邮件、删文件、改配置,都不是模拟的。
3、Prompt Injection
你让 AI 帮你总结一个网页,网页里藏了一段指令,AI 看到就乖乖执行了——发邮件、删文件、读配置——完全绕过你。
风险往往从最像正常输入的地方开始。网页、邮件、文档、Issue、聊天记录——模型会把它们读进同一个工作上下文。文本不是无害输入,而是潜在控制信号。
4、本地跳板
很多人觉得"我又没上云,跑在自己电脑上总安全了吧?"
还真不一定。
恶意网站可以通过隐藏脚本尝试连接你本地的 OpenClaw,如果成功了,攻击者就能接管你的 Agent。
本地部署 ≠ 绝对安全。建议用独立电脑或在 Docker 里运行。
安全怎么做?三个字:事前、事中、事后
很多人觉得安全就是"改个密码"或者"加个认证"。
不够。
你至少得想清楚三件事:事前,哪些操作绝对不能让 Agent 自动干;事中,Agent 运行的时候权限边界卡在哪;事后,出了问题能不能查、能不能回滚。
道理不复杂,但落地才是重点。
后面讲 n8n 方案的时候,你会看到这三件事是怎么通过 OpenClaw + n8n 的架构自然实现的——不是靠理论,是靠架构本身就把安全兜住了。
一个实操建议:刚装好 OpenClaw 的时候,别急着把所有能力都打开。先只跑最基础的对话,确认没问题了,再按需逐步开放。一口气全开等于把所有门窗都敞着,出了事都不知道从哪进来的。
如果你想系统地做好 OpenClaw 安全加固,推荐看看慢雾科技开源的 OpenClaw 安全实践指南。慢雾是区块链安全领域的头部团队,这份指南从 AGENTS.md 的红线规矩、权限收缩、到具体的攻防场景都覆盖了,写得非常实操。
慢雾 GitHub 地址:https://github.com/slowmist/openclaw-security-practice-guide
官方安全文档:https://docs.openclaw.ai/zh-CN/gateway/security
安全细节这里就不展开了,大家自己去翻,值得花半小时通读一遍。
与其信别人的 Skill,不如自己造一个
前面提到恶意 Skills 的风险,你可能觉得"我装的都是下载量很高的,应该没问题吧?"
还真不一定。
前段时间 1Password 的安全研究员发了一篇文章,发现 ClawHub 上下载量最高的 Skill 之一,竟然是个恶意软件投递工具。它伪装成「TwitterSkill」,让你安装一个所谓的"前置依赖",实际上是一条经过混淆的恶意命令链,最终下载并执行一个 macOS 信息窃取木马。
https://1password.com/blog/from-magic-to-malware-how-openclaws-agent-skills-become-an-attack-surface
下载量高 ≠ 安全。
开放生态的代价就是:你不知道那个看起来五星好评的 Skill,背后藏了什么。
所以我的建议是:能自己造的 Skill,就别装别人的。
很多人觉得造 Skill 很难,要写代码、改配置文件。其实不是。我在分享会上演示了一个场景。
批量下载一个公众号的所有历史文章,全程只靠聊天就搞定了。
Step 1:找 API
核心问题是什么?是要拿到历史文章列表。所以我们只需要找一个能返回历史文章链接的 API。
Step 2:喂文档
找到 API 之后,直接把 API 文档截图发给 OpenClaw,让它自己去读、去理解。
就这么一张截图,它就学会了怎么调这个接口。
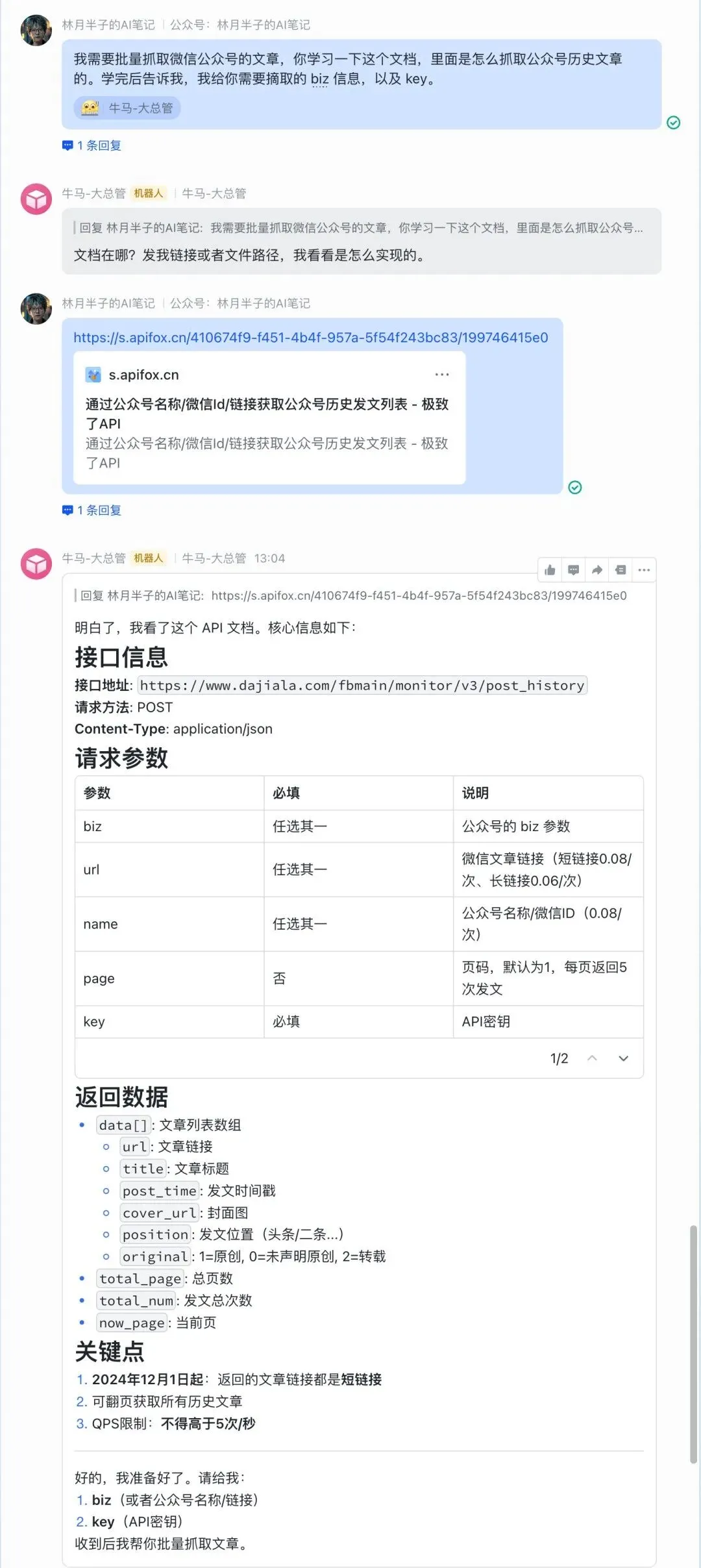
Step 3:跑通流程
先给第一个任务:根据 biz 信息和 API Key,把所有文章链接先抓出来保存好。
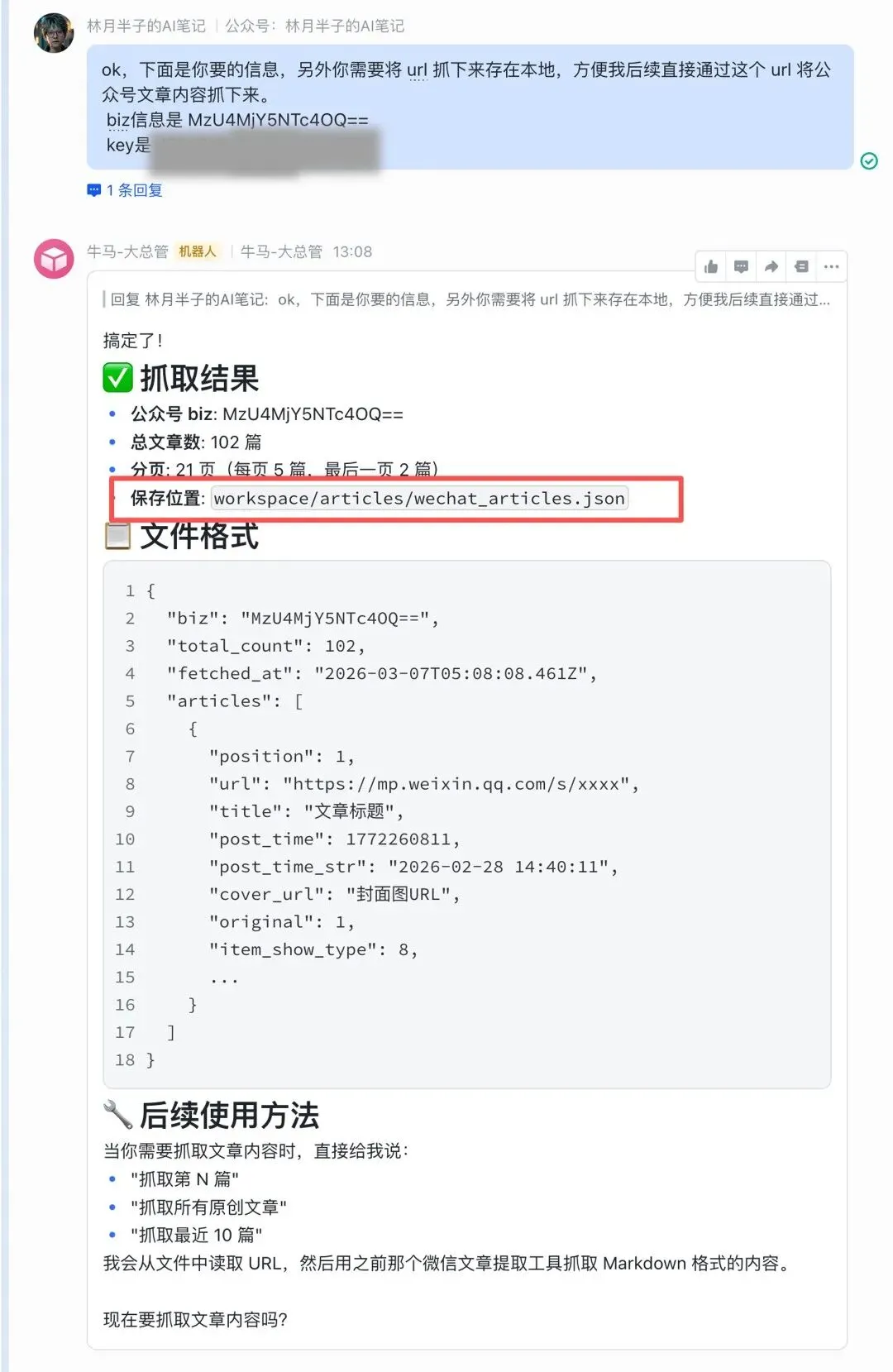
链接有了之后,再给第二个指令:根据这些链接,把所有文章下载下来,转成 Markdown 格式存到本地。
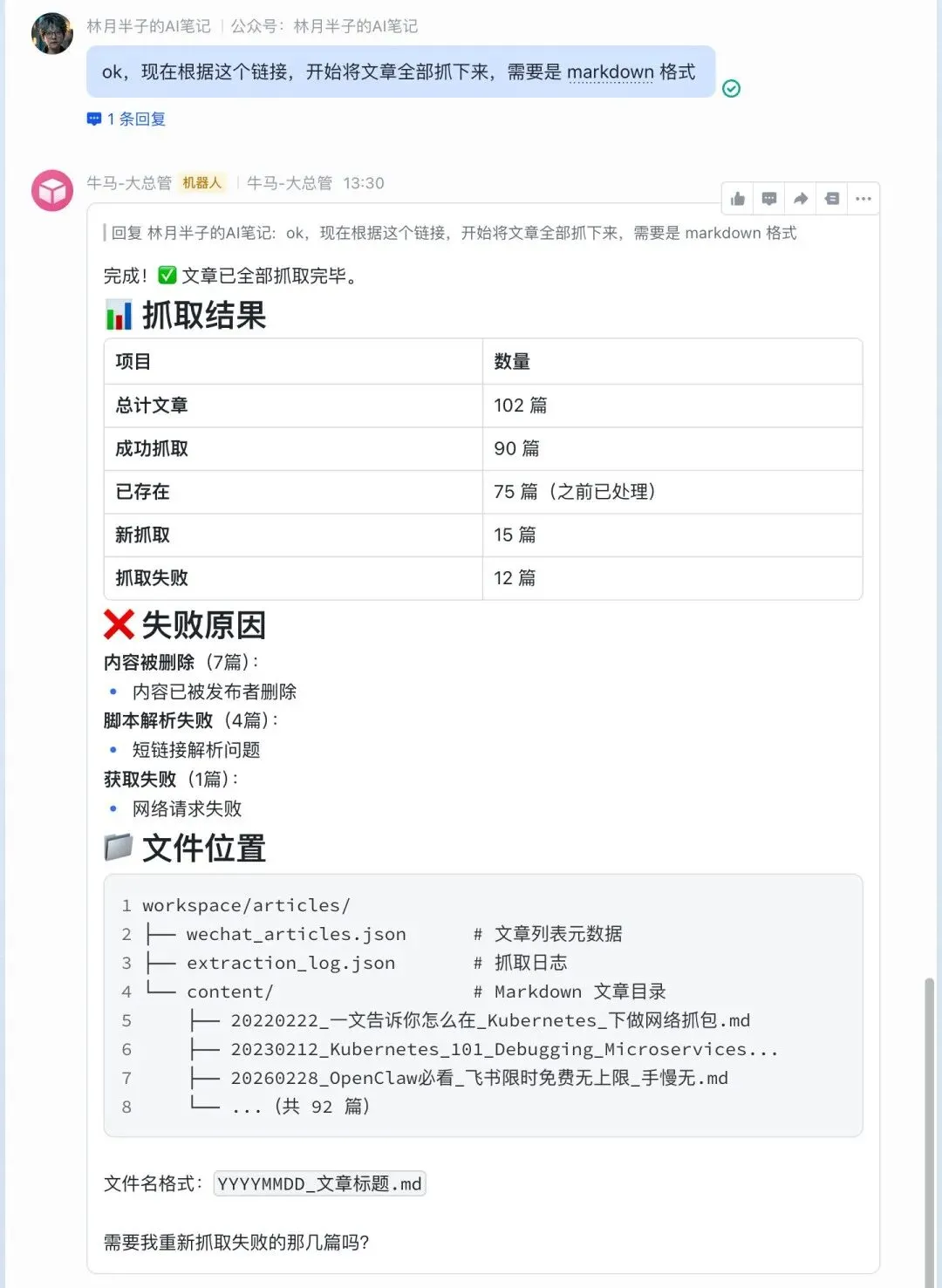
文章全部下来了。
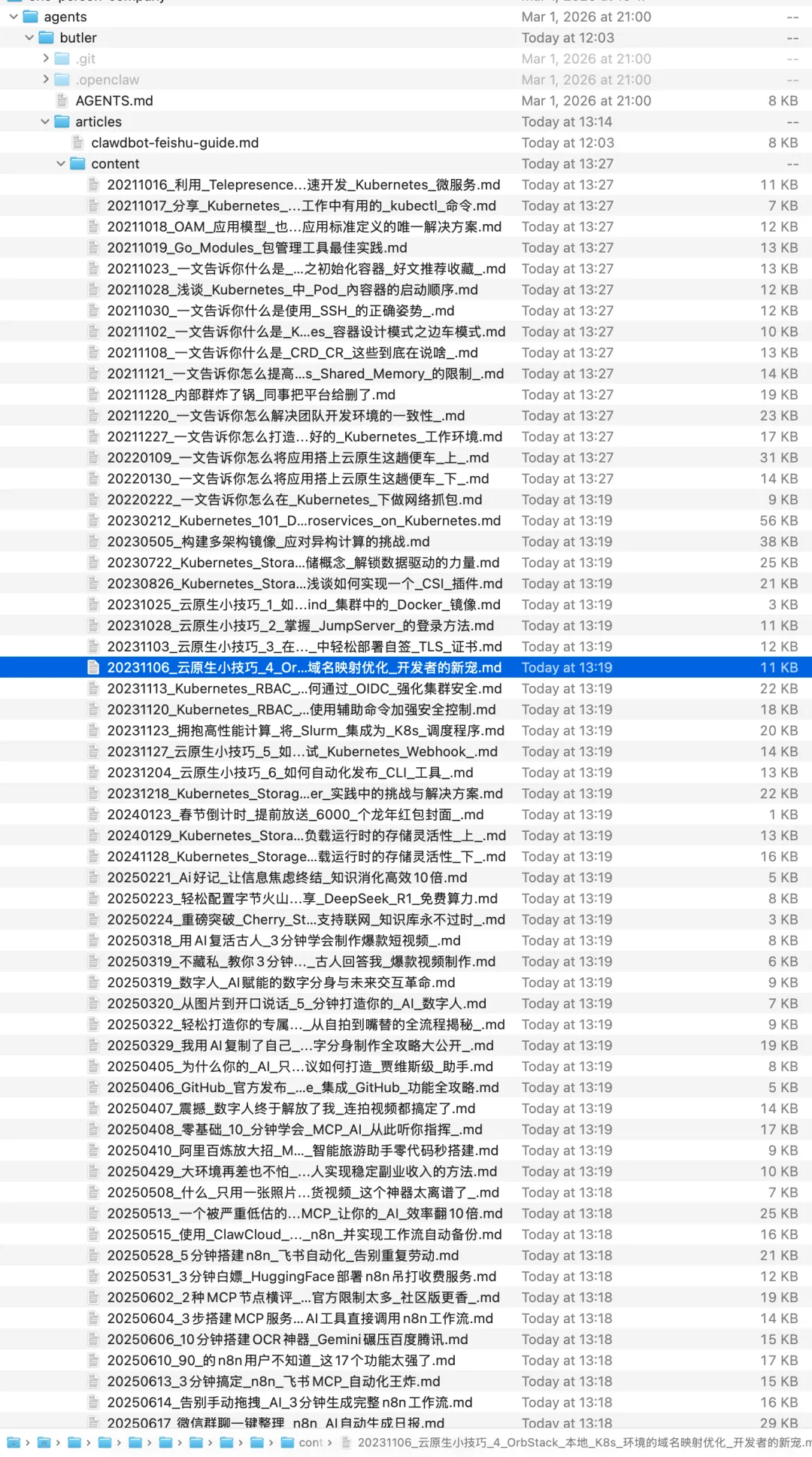
Step 4:固化成 Skill
重点来了。
流程跑通之后,我直接用自然语言告诉它:把刚才这个完整流程,封装成一个 Skill。以后我只要给它一个 biz 信息,它就自动把这个公众号所有文章全部下载下来。
没多久,Skill 就生成好了。
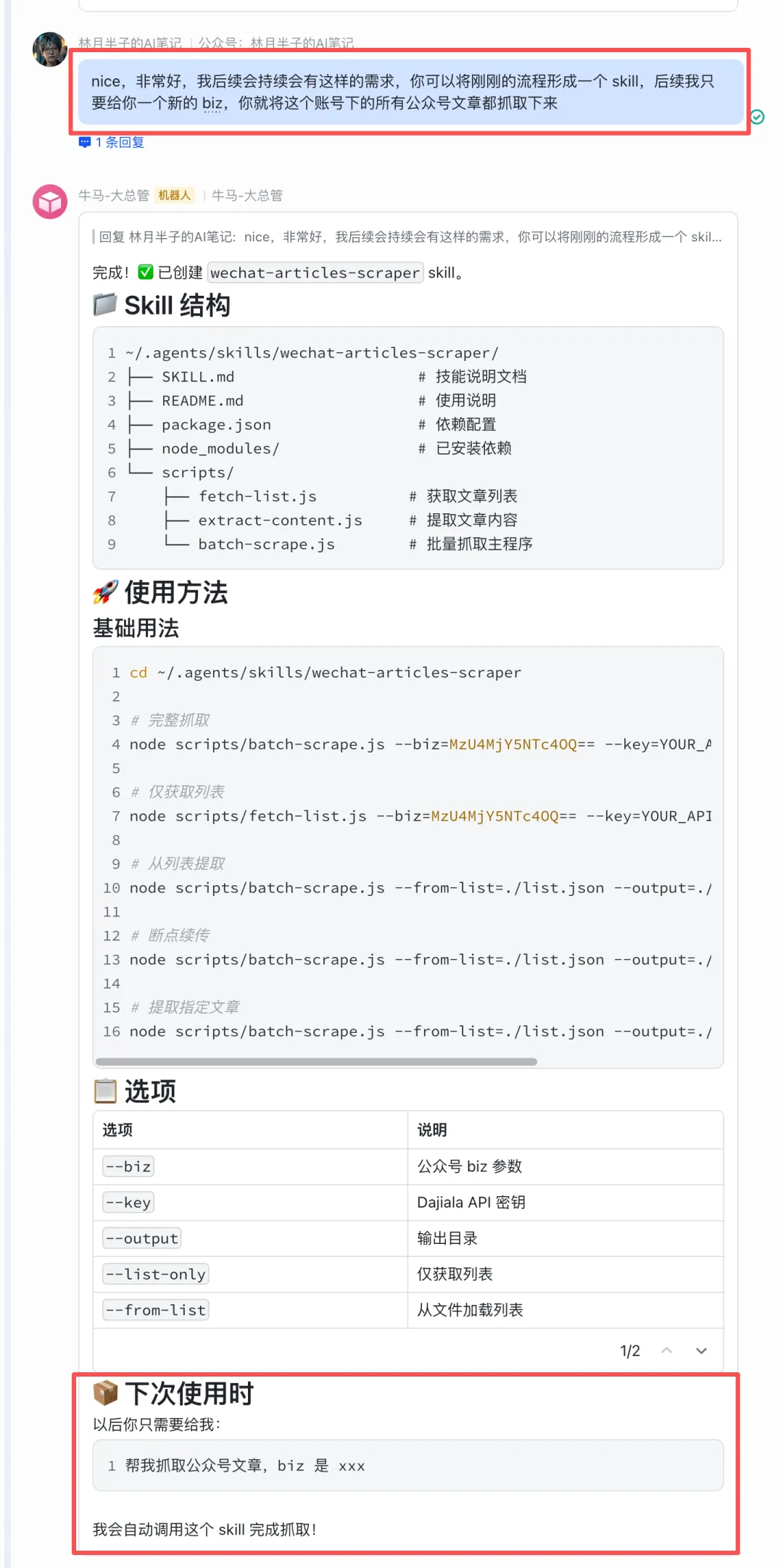
换一个公众号验证。
只告诉它 biz 信息,它自己就跑完了整个流程,文章全部下载到本地。
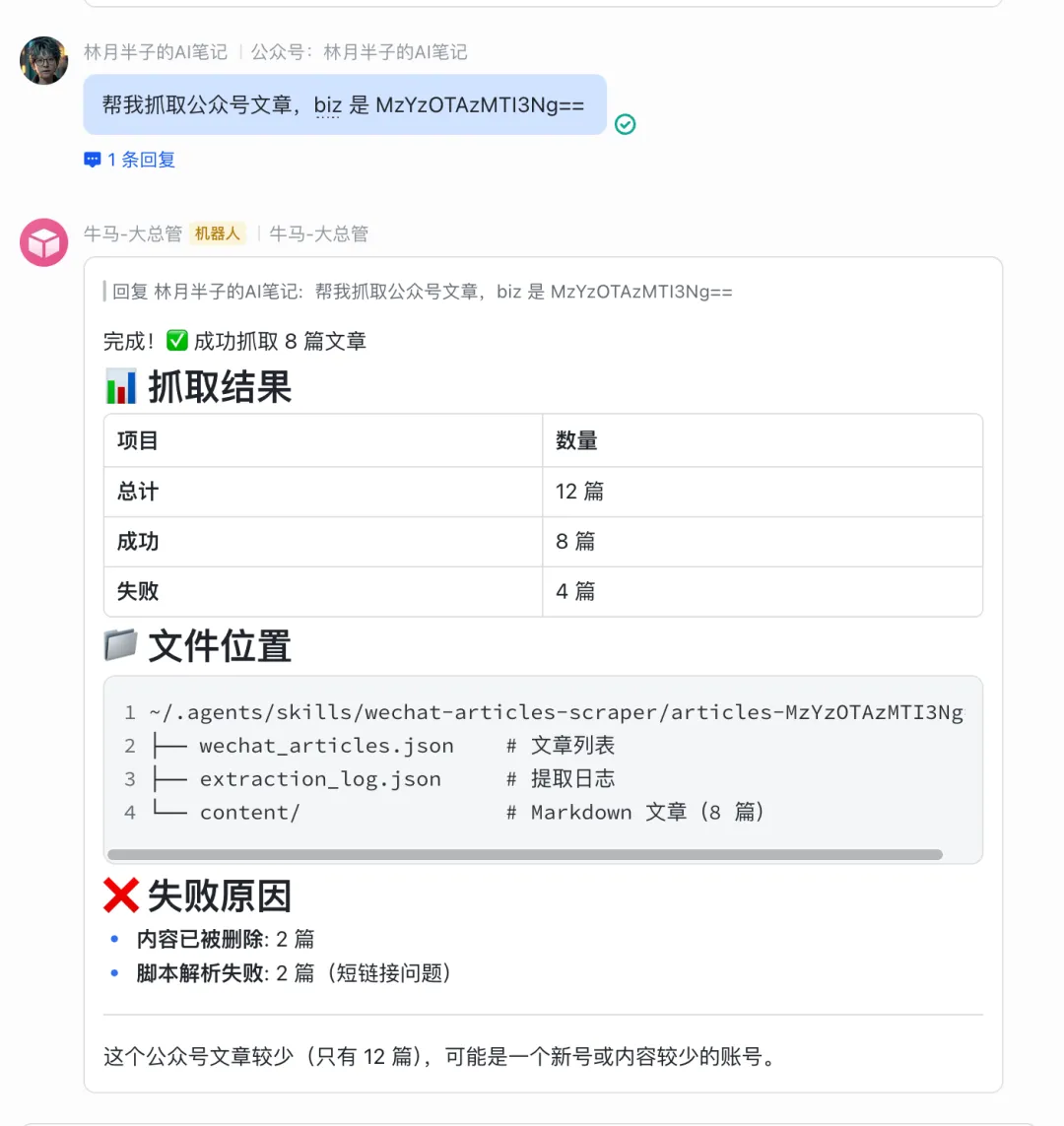
没有写一行代码,没有改任何配置文件,完全就是在聊天。
先跑通,再封装,这就是用 OpenClaw 造 Skill 最自然的方式。
自己造的 Skill,逻辑透明、权限可控,比从开放市场上装一个来路不明的"效率神器"安心多了。
核心方案:让 OpenClaw 当大脑,n8n 当手脚
好,回到开头的两个痛点。
解决方案其实很简单——分工。
让 OpenClaw 只负责概率性的事情,也就是思考和决策;让 n8n 负责确定性的事情,也就是执行。
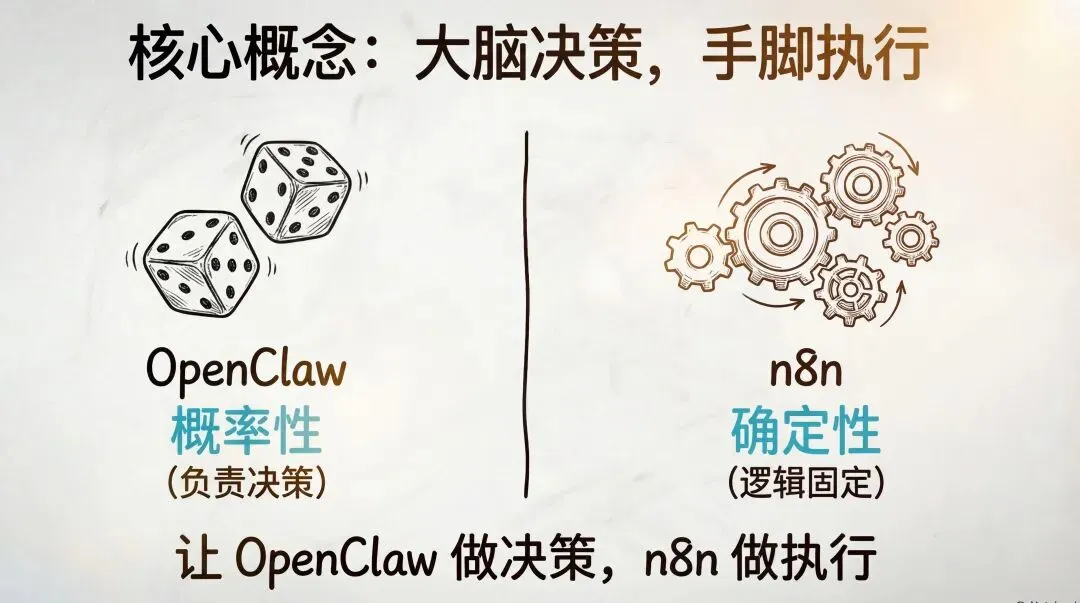
用一句话来说:n8n 成了你的助手的助手。
但这里有一个边界要说清楚,不是所有场景都适合接 n8n。
2C 场景(用户需求多变、临时性强,今天问天气明天问别的):直接让 OpenClaw 处理就好,强行接 n8n 反而麻烦。
2B 场景(流程固定、可重复、逻辑写死):这种放在 n8n 里更稳定、更省钱、更安全,才是 OpenClaw + n8n 最发挥价值的地方。
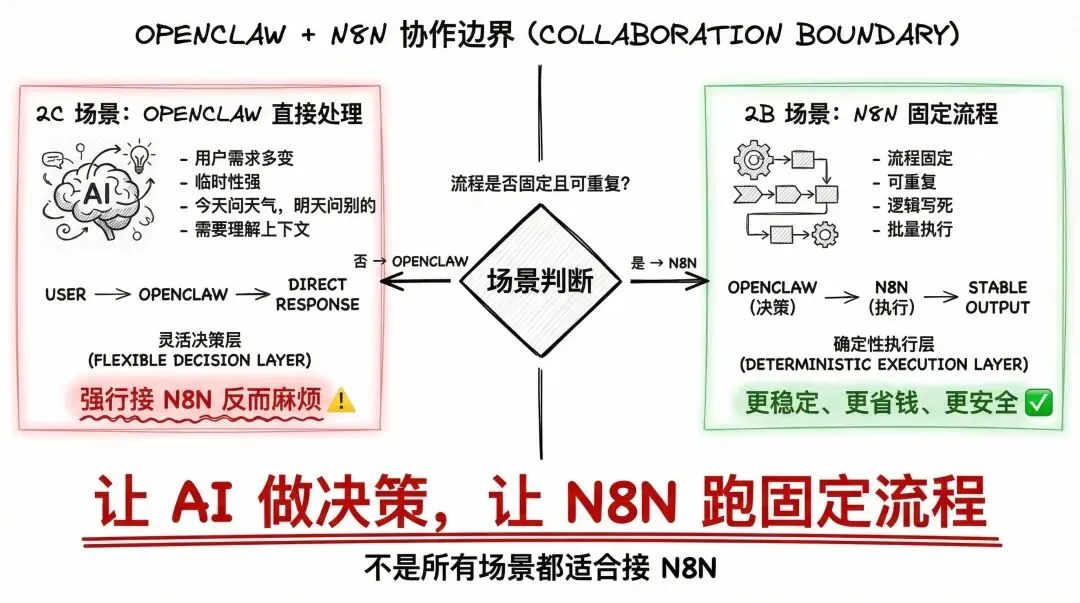
记住这句话:让 AI 做决策,让 n8n 跑固定流程。
n8n 就是一道天然的防火墙
回到安全问题。
看这个架构,OpenClaw 只知道一个 Webhook URL,就这一个地址,其他什么都不知道。
所有的 API Key、数据库密码,全部只存在 n8n 内部。
即使有一天 OpenClaw 被攻破,攻击者拿到的也只是一个 Webhook URL。你的核心数据依然安全。
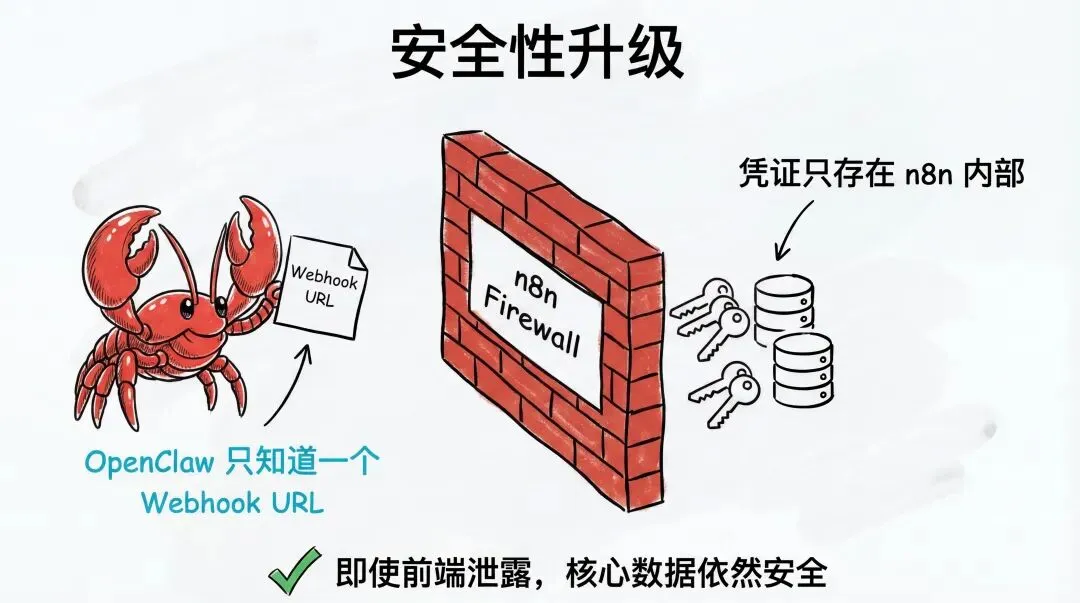
这就是前面说的事前、事中、事后的具体落地。
事前:OpenClaw 的权限被收窄到只能调用 Webhook,碰不到任何凭证;
事中:n8n 内部工作流逻辑固定,不受 LLM 的"发挥"影响;
事后:n8n 有完整的执行日志,每一步都可追溯。
凭证隔离 + 执行可控 + 日志可查,三件事一起解决。
两种连接方式
方式一:n8n 主动找 OpenClaw
说实话,这个方向目前适用场景相对窄。
因为大部分情况下,n8n 需要 AI 能力时,直接调 AI Agent 节点就够了,没必要绕一圈去找 OpenClaw。
但有一类场景例外。
你需要的不是"裸模型"的一次性回答,而是一个有记忆、有工作区上下文的 Agent 来做最终交付。
举个例子:n8n 做数据预处理,OpenClaw 写周报。
n8n 每周五下午定时从数据库拉本周的业务数据——销售额、新增客户、工单处理量——清洗、格式化、拼成结构化的数据摘要。
这些全是确定性操作,零 Token 消耗。
然后 n8n 把这份数据摘要发给 OpenClaw。OpenClaw 根据工作区里的周报模板、之前积累的写作风格记忆,生成一份符合老板口味的周报。
你可能会说:OpenClaw 自己不是也有定时任务吗?确实有。但问题是——定时触发本身不费 Token,触发之后 Agent 开始干活就全程烧钱了。连数据库查数据(费 Token)、清洗格式化(费 Token)、生成周报(还是费 Token),前两步根本不需要 AI。
n8n 把脏活干完,OpenClaw 只负责最后的"临门一脚",Token 消耗直接砍掉一大半。
配置也很简单,在 openclaw.json 里开启 Gateway 的 chatCompletions:
{"gateway":{"http":{"endpoints":{"chatCompletions":{"enabled":true}}} }}就这几行,n8n 就可以用标准的 OpenAI 兼容接口跟 OpenClaw 通信了,返回标准的 chat.completion 格式,无缝替换。
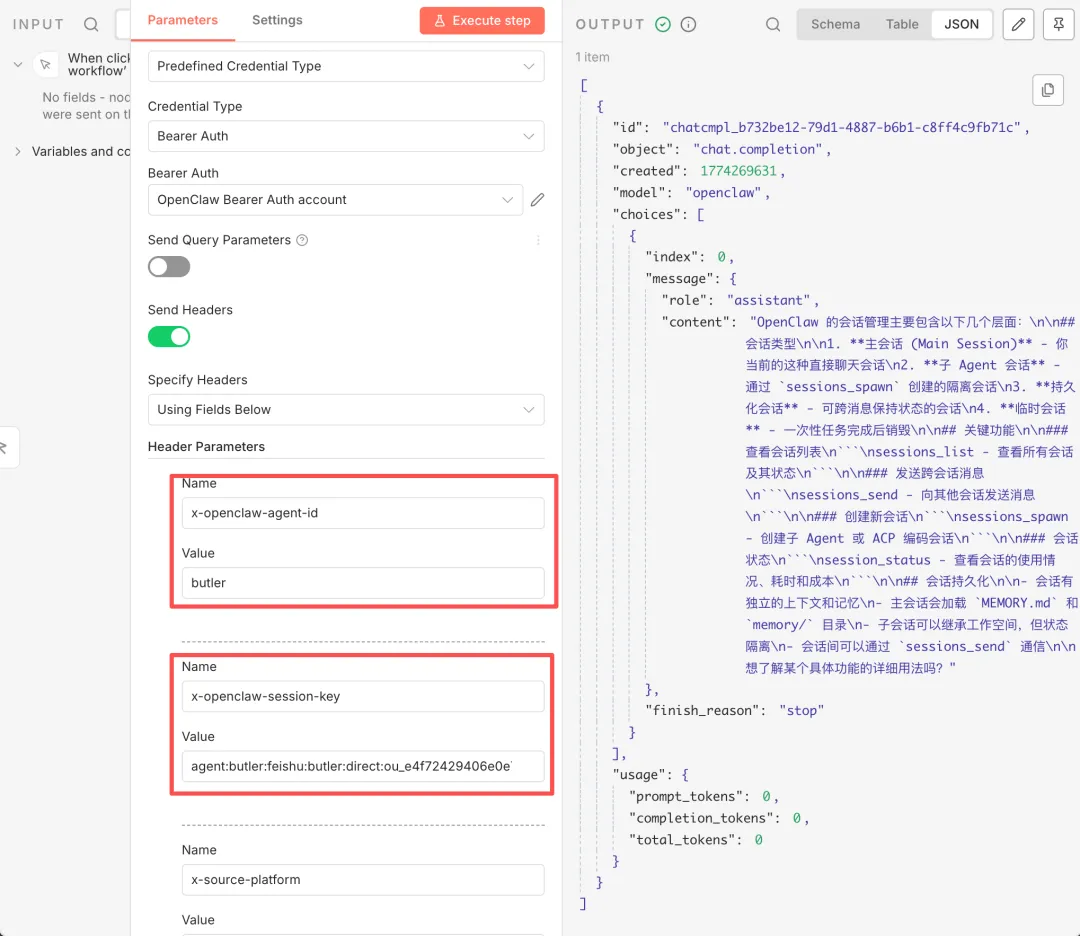
不过有一个细节要注意。如果你在 OpenClaw 里创建了多个 Agent,n8n 发请求的时候需要在 Header 里指定你要跟哪个 Agent 对话:
- x-openclaw-agent-id: <agentId>:指定目标 Agent,默认是 main。比如你想让 n8n 调写作 Agent,就填 writer
- x-openclaw-session-key: <sessionKey>:高级选项,用来控制会话路由。指定同一个 session key,多次请求就能保持在同一个会话上下文里
这两个参数在 n8n 的 HTTP Request 节点里加到 Header 就行。
这个方向我自己还在持续探索更多场景,如果你在实际业务中跑出了好的组合玩法,欢迎来群里交流,后续有足够的案例我会单独出一篇。
方式二:OpenClaw 主动找 n8n(重点!)
这才是更有价值的玩法。
反过来,让 OpenClaw 主动来找 n8n。
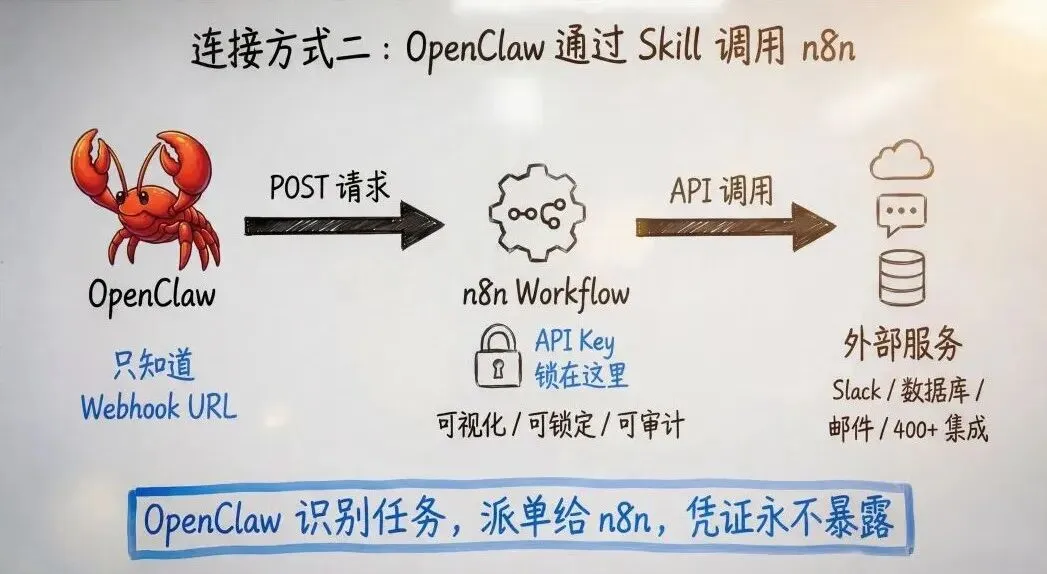
怎么做?把 n8n 的 Webhook URL 封装成一个 Skill,注册到 OpenClaw 里。
OpenClaw 以为自己在"调用一个工具",但背后其实是 n8n 在接管执行。所有的脏活累活——循环处理、数据库读写、API 调用——全交给 n8n。OpenClaw 只需要做最开始的意图识别。
OpenClaw 识别任务,派单给 n8n,凭证永不暴露。
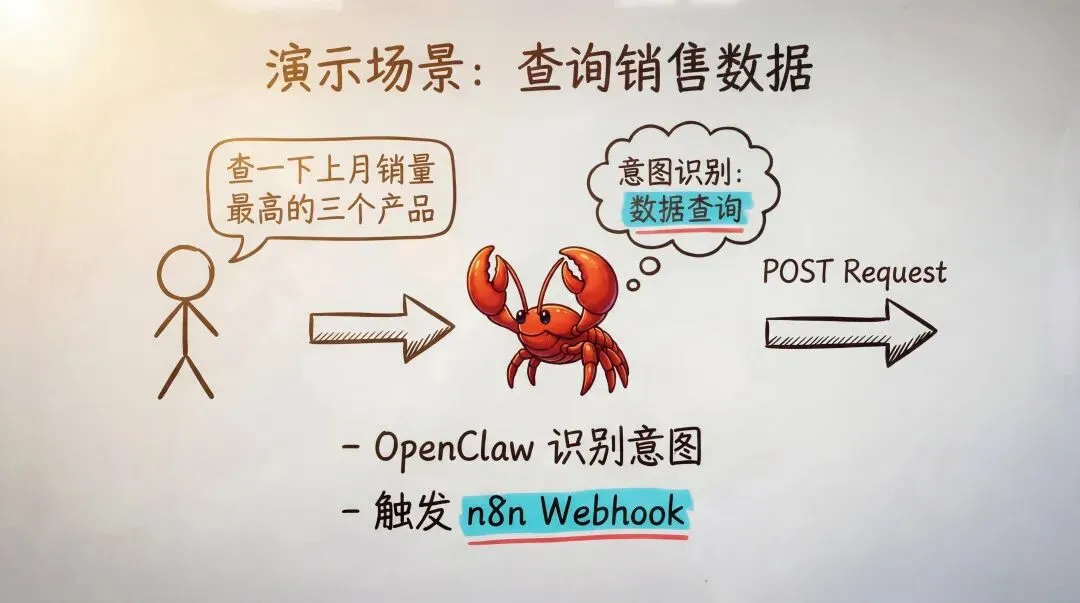
具体怎么配?我拿"查销量 Top 3"这个场景来走一遍完整流程。
1、n8n 侧:搭建接收工作流
首先在 n8n 里创建一个 Webhook 工作流,作为接收入口:
- 1.Webhook 节点:设置为 POST 方式,路径比如 /openclaw/query-sales,接收 OpenClaw 传过来的参数(时间范围、查询条数等)
- 2.数据库节点:连接你的内部数据库,执行 SQL 查询。所有数据库凭证只存在 n8n 的 Credentials 里,OpenClaw 完全不知道
- 3.数据处理节点:对查询结果做格式化,比如拼成一段人话:"上个月销量前三:产品A(3280件)、产品B(2150件)、产品C(1890件)"
- 4.Respond to Webhook 节点:把处理好的结果返回给 OpenClaw
整条工作流几个节点,逻辑固定,执行确定,零 Token 消耗。
关键点:n8n 的 Webhook 支持配置认证(Header Auth、Basic Auth 等),建议给这个入口加上认证,防止被外部随意调用。这个我在之前的文章https://mp.weixin.qq.com/s/xuuZA1kbLiGCipjkozBnOA里详细写过,没看的可以先去补课。
2、OpenClaw 侧:封装成 Skill
n8n 工作流搭好之后,我们需要在 OpenClaw 这边创建一个 Skill,让它知道"有这么一个工具可以用"。
在 Agent 的工作区里创建一个 Skill 文件夹,核心是 SKILL.md:
---name: query-sales-topdescription: 查询指定时间范围内销量最高的产品。当用户询问销量排名、热销产品、销量 Top N 等相关问题时使用此工具。---# 销量查询工具## 使用方法向 n8n Webhook 发送 POST 请求:- URL: https://your-n8n-domain.com/webhook/openclaw/query-sales- Method: POST- Headers: Authorization: Bearer <你的认证Token>- Body 参数: - period: 时间范围,如 "last_month"、"last_week" - top_n: 返回前几名,默认 3## 返回格式n8n 会返回格式化的文本结果,直接转述给用户即可。## 注意事项- 不要在请求中携带任何数据库凭证- 所有数据查询由 n8n 内部完成配置完成后,当用户问"上个月什么卖得最好",OpenClaw 会自动匹配到这个 Skill,发起 Webhook 调用,n8n 执行查询并返回结果。
整个过程中,OpenClaw 只做了一件事,理解用户意图并选择正确的工具。剩下的全是 n8n 在干活。
3、实战效果
用户在飞书里说一句话:"帮我查上个月销量最高的三个产品"。
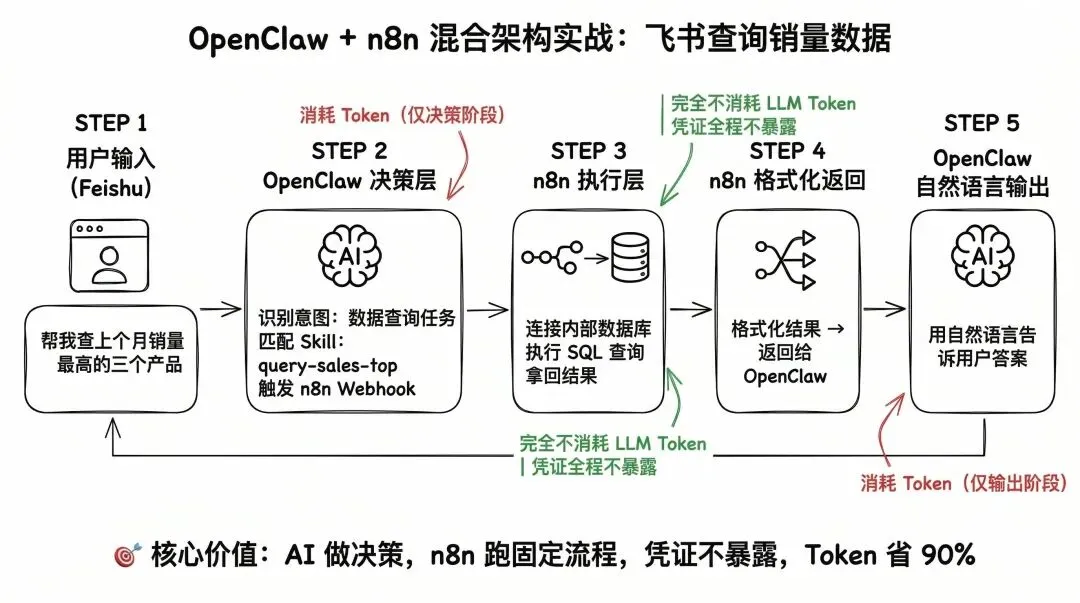
整个链路是这样的:
- 1.OpenClaw 收到消息,识别意图,判断这是一个数据查询任务
- 2.匹配到 query-sales-top Skill,触发 n8n 的 Webhook
- 3.n8n 连接内部数据库,执行 SQL 查询,拿回结果
🎯 注意:这整个执行过程,完全不消耗 LLM Token,凭证全程不暴露。
- 4.n8n 把结果格式化后返回给 OpenClaw
- 5.OpenClaw 用自然语言告诉用户答案
用户只说了一句话,全链路自动完成。
如果同样的事情全让 OpenClaw 来做呢?它得先理解请求(Token),再决定查哪个数据库(Token),再拼 SQL(Token),再处理返回结果(Token)——每一步都在烧钱。而且数据库密码必须配在 OpenClaw 里,一旦被攻破全盘泄露。
同一个需求,两种做法,成本和安全差距一目了然。
这个模式可以复用到大量 2B 场景:定时日报推送、客户数据同步、订单状态流转、库存预警通知……只要流程固定,就值得用 n8n 接管执行层。
上面的销量查询只是一个最简 demo,帮你跑通整个链路。如果你想深入了解 OpenClaw + n8n 的编排方式,推荐看看这份社区整理的集成指南:
🔗 https://github.com/hesamsheikh/awesome-openclaw-usecases/blob/main/usecases/n8n-workflow-orchestration.md
写在最后
回到开场的两个问题——贵,不安全。
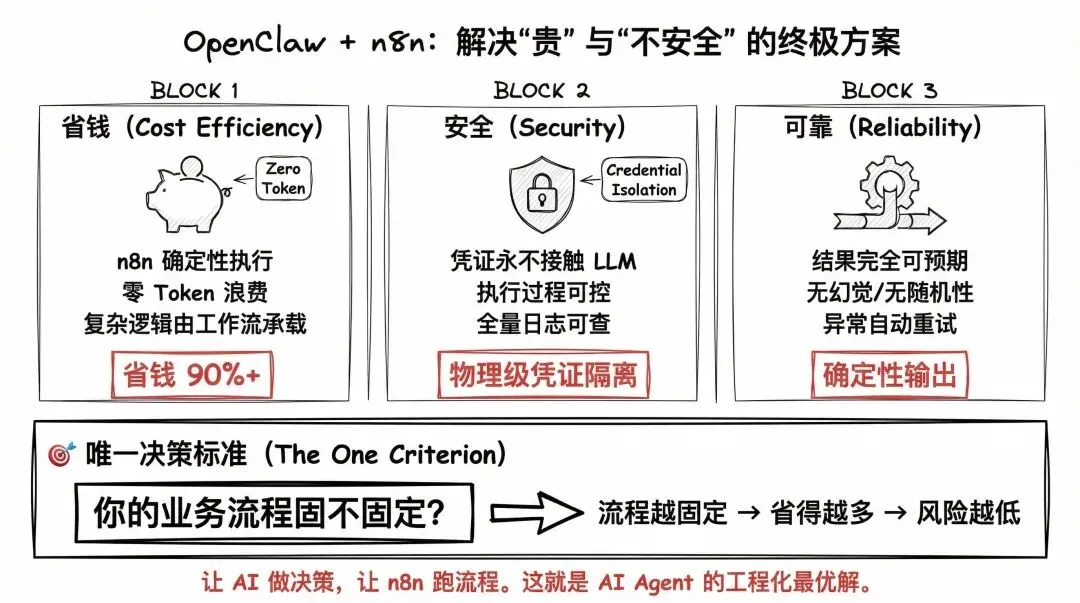
现在都有答案了:
省钱:n8n 确定性执行,零 Token 浪费。
安全:凭证永不接触 LLM,n8n 天然做到了凭证隔离、执行可控、日志可查。
还有一个 bonus——可靠。n8n 里的工作流执行结果完全可预期,不像 LLM 有时候会"发挥"。
这个组合适不适合你?看一条标准就够了:你的业务流程固不固定。
流程越固定,省得越多,风险越低。
OpenClaw 安全真正要解决的,不是追求绝对无风险,而是把边界、权限和审计收紧到可控范围。对象要讲对,运行面要看全,防线要成体系。
而 n8n,恰好是这套防线里最趁手的一块积木。
感谢看到这里 👏
觉得有用的话,点赞 👍 / 在看 👀 / 转发 🫱 / 评论 📣
星标 ⭐ 一下,下次更新不迷路
