 夜雨聆风
夜雨聆风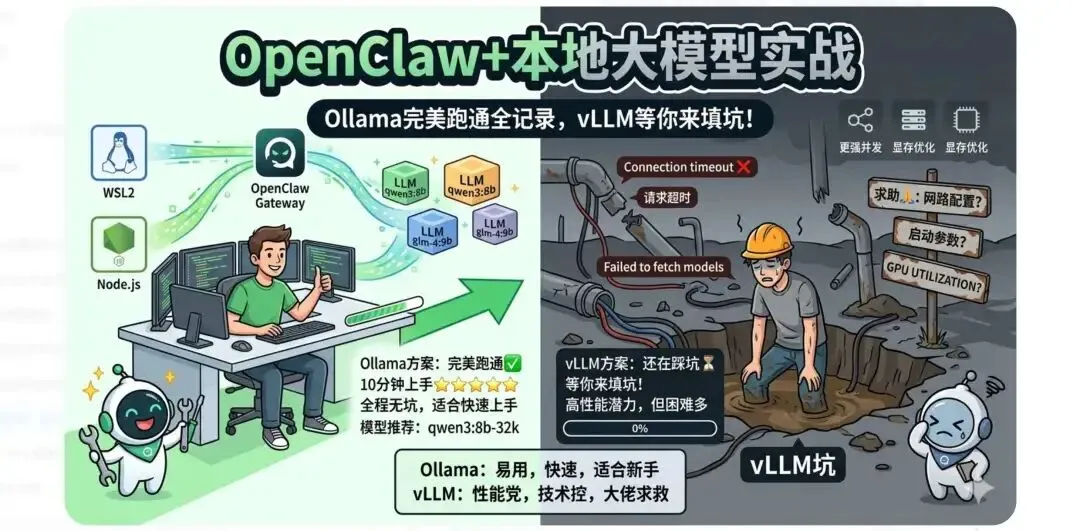
本地部署,从Ollama开始
最近折腾OpenClaw对接本地大模型,亲测Ollama方案已完美跑通!从安装到配置,全程无坑,适合想快速上手的同学。
至于vLLM... 目前还在踩坑中(后文详说)。如果你成功跑通了vLLM,请务必在评论区分享经验,咱们一起完善这份指南!
为什么选本地部署?
适合人群:
处理敏感数据的打工人 想白嫖无限调用的开发者 网络环境受限的企业内网用户
环境准备(Windows/WSL2版)
必装清单
# 1. WSL2(Windows必需)wsl --install -d Ubuntu-22.04# 2. Node.js 22+ # 官网下载:https://nodejs.org 或curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash -sudo apt-get install -y nodejs# 3. 验证版本node -v # v22.x.xnpm -v # 10.x.x硬件参考
测试环境:
CPU: AMD Ryzen 7 5800X 内存: 32GB DDR4 显卡: RTX 3060 12GB(关键:大显存比高算力更重要) 系统: Windows 11 + WSL2 Ubuntu 22.04
经验谈:12GB显存跑qwen3:8b很顺畅,但想跑14B模型建议16GB+。
Ollama部署全流程(已验证✅)
安装Ollama
# WSL2/Ubuntu一键安装curl -fsSL https://ollama.com/install.sh | sh# 验证ollama --version # 0.6.5+Windows用户注意:Ollama会同时安装Windows版和WSL版,建议统一在WSL2里操作,避免路径混乱。
拉取模型(避坑重点!)
关键认知:OpenClaw需要支持Function Calling(工具调用)的模型!
| qwen3:8b | |||
| qwen2.5:7b | |||
| glm-4:9b | |||
| deepseek-r1:8b | |||
| llama3.1:8b |
我的选择:
# 拉取Qwen3 8B(默认8K上下文)ollama pull qwen3:8b# 创建32K上下文版本(OpenClaw建议≥16K)cat > Modelfile << 'EOF'FROM qwen3:8bPARAMETER num_ctx 32768EOFollama create qwen3:8b-32k -f Modelfile验证模型:
ollama list# NAME ID SIZE MODIFIED# qwen3:8b xxx 4.9 GB 2 hours ago# qwen3:8b-32k xxx 4.9 GB 1 hour ago ← 用这个安装OpenClaw
# 全局安装npm install -g openclaw# 验证openclaw --version # 1.x.x配置对接(核心步骤)
启动配置向导:
openclaw onboard逐步操作截图级指引:
Custom Provider | |||
http://127.0.0.1:11434/v1 | 必须带/v1后缀 | ||
ollama | 随意填,不能留空 | ||
OpenAI-compatible | |||
qwen3:8b-32k | |||
32768 | |||
8192 | |||
00 | |||
Skip for now | |||
Skip for now |
看到 Verification successful 就成功了!
启动与验证
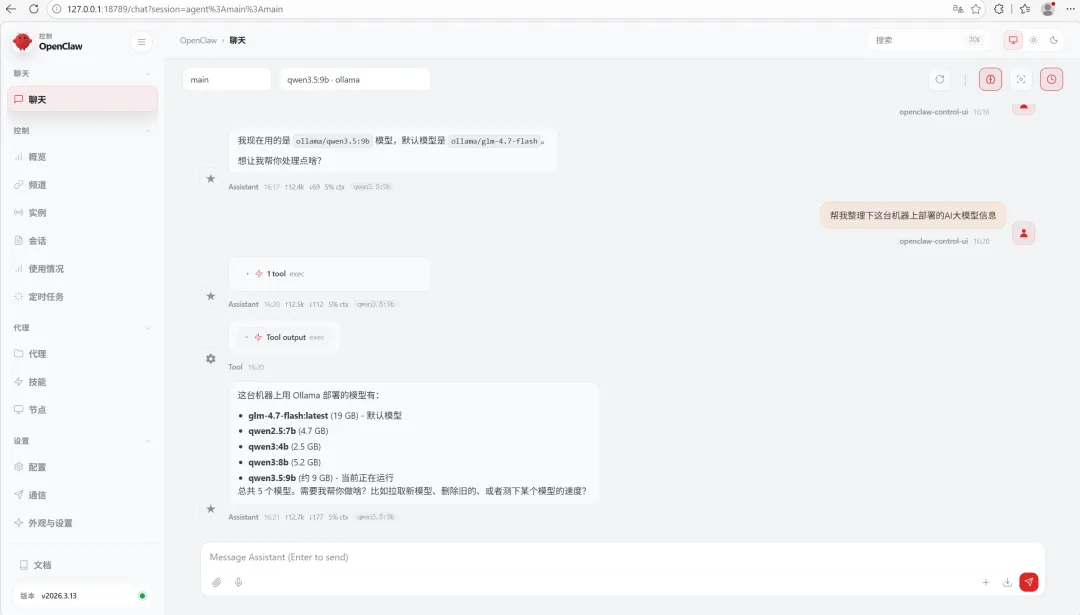
# 启动网关openclaw gateway# 输出示例:# [Gateway] Starting gateway on http://127.0.0.1:18789# [Ollama] Connected to http://127.0.0.1:11434/v1# [Model] qwen3:8b-32k ready访问Web界面:浏览器打开 http://127.0.0.1:18789
测试工具调用:
输入:"帮我查一下北京的天气" 观察:Agent应该能识别意图并调用天气工具(如果配置了MCP) 查看日志: openclaw logs能看到完整的请求/响应
Ollama进阶技巧
多模型管理
# 列出所有模型ollama list# 快速切换模型(无需重启OpenClaw)ollama run qwen2.5:7b# 删除不用的模型释放空间ollama rm deepseek-r1:8b性能优化
# 查看当前运行的模型ollama ps# 限制显存占用(多模型并存时有用)export OLLAMA_GPU_OVERHEAD=1GB# 强制CPU运行(没显卡时应急)export OLLAMA_NO_GPU=1自动启动配置
# WSL2设置开机自启sudo systemctl enable ollama# 或者创建Windows任务计划程序,开机执行:# wsl -d Ubuntu-22.04 -e ollama servevLLM部署现状:我卡在哪了?(求助🙏)
为什么想试vLLM?
Ollama虽然好用,但vLLM有几个诱人特性:
更高并发:适合多Agent同时运行 显存优化:相同显卡能跑更大模型 吞吐量:API响应速度更快
我的尝试过程
安装阶段(顺利):
pip install vllm# 安装成功,无报错启动服务(疑似成功):
python -m vllm.entrypoints.openai.api_server \ --model Qwen/Qwen2.5-7B-Instruct \ --port 8000 \ --host 0.0.0.0# 显示:INFO: Started server process [xxx]配置OpenClaw(按文档操作):
{"vllm-local": {"baseUrl": "http://127.0.0.1:8000/v1","apiKey": "sk-anything","models": [{"id": "Qwen2.5-7B-Instruct", "contextWindow": 32768}] }}报错现象:
OpenClaw配置向导显示 Connection timeout直接curl http://127.0.0.1:8000/v1/models有时能通,有时不通日志显示 Failed to fetch models from provider
我的排查思路(未解决)
网络层:确认端口8000已放行防火墙 服务层:vLLM日志显示运行正常,无错误 配置层:尝试了 localhost/127.0.0.1/0.0.0.0多种组合权限层:WSL2和Windows防火墙都检查过
怀疑方向:
vLLM的OpenAI兼容层与OpenClaw的握手协议不匹配? 需要额外的启动参数?
📢 vllm部署求助,等你来填坑!
如果你成功跑通了vLLM + OpenClaw,请帮忙验证以下信息:
环境信息(请留言格式)
操作系统: [Windows/Mac/Linux]部署方式: [Docker/conda/源码]vLLM版本: [x.x.x]模型名称: [xxx]关键启动参数: [xxx]OpenClaw版本: [x.x.x]特别想请教的问题
WSL2部署vLLM是否需要特殊网络配置?
是否需要 --network host?Windows访问WSL2的vLLM服务,地址是 localhost还是172.x.x.x?工具调用参数怎么配?
是否需要 --enable-auto-tool-choice?--tool-call-parser选hermes还是qwen?性能调优经验
--gpu-memory-utilization设多少合适?--max-num-seqs对OpenClaw的影响?与Ollama的对比
实际使用中vLLM比Ollama快多少? 显存占用真的更低吗?
总结
当前结论:
✅ Ollama方案:已验证,10 分钟上手,适合绝大多数个人用户 ⏳ vLLM方案:潜力大,但需要大家帮忙共同攻克难题
我的建议:
新手/急用 → 直接抄Ollama部分的作业,今天就能跑起来 性能党/技术控 → 先收藏本文,等评论区vLLM方案成熟后再迁移 大佬 → 请直接评论区开讲,拯救一下卡在vLLM的小伙伴😭
参考资源
| vLLM经验征集区 |
