 夜雨聆风
夜雨聆风组建基于OpenClaw的多智能体团队时,开发者总会陷入一个“幸福的烦恼”:GPT-4o、Claude 3.5、DeepSeek、GLM……主流模型多如牛毛,各有优劣,到底该选哪一个?
WEEX Labs经过多轮实战测试后发现:组建AI团队,“全员名牌”不等于最高效率。在Multi-Agent架构中,根据不同角色的职能属性,搭配适配的模型“混搭组队”,才是平衡性能与成本的最优解。
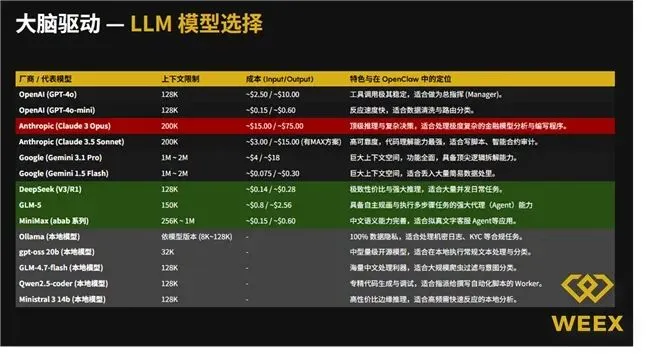
今天,我们公开WEEX实验室独家模型选型笔记,从角色适配、模型对比到避坑指南,手把手教你为每一位“AI员工”选对“数字大脑”,高效搭建高性价比多智能体团队。
按岗选型:3大核心角色,对应最优模型
Multi-Agent团队的高效运转,核心在于“人岗匹配”——不同职能的AI角色,对模型的能力要求截然不同。我们结合实战经验,为3大核心角色筛选出最优适配模型,附详细实战反馈与避坑提醒。
1. Leader Bot(统筹者):需顶级逻辑与全局洞察,定方向、拆任务
Leader角色的核心使命,是拆解复杂目标、制定执行计划、分配任务优先级,这就要求模型具备极强的推理能力、全局观和指令拆解能力,不能出现逻辑断层。
✅ 首选推荐:GPT-4o / Claude 3.5 Sonnet
💡 实战反馈:在处理多步骤复杂任务(如策划一场跨平台营销活动、搭建一套多智能体协作流程)时,这两个模型的“理解力”表现突出,能精准识别任务核心需求,合理拆分步骤、划分优先级,极少出现指令偏差或逻辑断裂,堪称“AI团队指挥官”。
⚠️ 避坑提醒:Leader角色坚决不建议使用参数量较小的轻量级模型。这类模型容易出现“理解偏差”,导致指令分发南辕北辙,反而拖慢整个团队效率,甚至引发任务失控。
2. Coder & Researcher(执行者):逻辑严密是底线,保落地、提效率
这类角色主要负责编写代码、调用API、深度数据检索等落地性工作,核心要求是结构化输出能力强、逻辑严密、准确率高,同时兼顾调用成本。
✅ 黑马选手:DeepSeek-V3 / Claude 3.5
💡 实战反馈:Claude 3.5在代码生成、API调用的准确率上,依然是行业标杆,尤其擅长复杂代码的调试与优化;而国产模型DeepSeek-V3则带来惊喜,在中文语境下的逻辑理解力、代码适配性表现出色,且API调用成本极具竞争力,非常适合作为高频调用的执行层“AI员工”,兼顾效率与成本。
3. Writer & Critic(创意与审计):文采与审慎并存,出精品、避风险
这类角色分为两大细分方向,对模型的能力要求截然不同,需针对性选型,实现“创意输出+风险把控”的双重保障。
✅ Writer(撰稿员):首选Claude系列
💡 实战反馈:如果需要输出具有人文关怀、创意灵感的文案(如活动推文、品牌文案),Claude系列比GPT更具“人味”,语言更细腻、情感更饱满,能有效减少千篇一律的AI腔调,让内容更有感染力。
✅ Critic(批判者):首选GPT-4o
💡 实战反馈:这个角色的核心是“吹毛求疵”,负责审核内容逻辑、排查错误、规避风险。实战中我们发现,GPT-4o在识别逻辑矛盾、审视内容漏洞、修正错误方面表现最稳健,能有效解决单一模型容易出现的“记忆混淆”“逻辑自洽性不足”等问题,为任务质量保驾护航。

关键取舍:全球模型 vs 国内模型,该怎么选?
除了按角色选型,全球模型与国内模型的取舍,也是开发者常面临的难题。WEEX Labs针对主流模型,在Multi-Agent系统中进行了多维度压力测试,总结出2个核心取舍标准,精准匹配不同场景需求。
⚠️ 关于“失忆”与“串词”:部分本地化模型或参数量较小的模型,在多轮对话、长效运行后,容易出现“记忆力减退”(忘记前文指令),甚至在中文任务中突然冒出英文回复,影响任务连贯性。如果你的任务需要长效运行(如长期舆情监控、多步骤协作),建议优先选择上下文窗口大、稳定性高的国际一线模型(如GPT-4o、Claude 3.5)。
⚡ 关于响应速度:在舆情监控、实时数据检索等高实时性任务中,国内模型(如DeepSeek-V3)凭借地理位置优势和算力优化,往往具有更低的延迟,能快速响应指令,提升任务落地效率,适合对响应速度有高要求的场景。
WEEX选型法则:安全性与稳定性,比“智商”更重要
在模型选型中,WEEX Labs始终坚持“Security-First”原则——除了关注模型的“智商”(推理、执行能力),更重视安全性与稳定性,避免因模型漏洞导致资产信息外泄。
✅ 加密防护:所有模型调用均通过加密网关进行,保障数据传输安全,防止指令与数据泄露;
✅ 本地部署测试:在本地环境(如虚拟机)部署模型时,优先测试模型在隔离环境下的表现,排查插件漏洞,确保不会因模型问题导致企业核心资产信息外泄。
写在最后:没有最好的模型,只有最适配的“AI员工”
组建OpenClaw多智能体团队,核心从来不是“选最顶级的模型”,而是“为每个角色选最适配的模型”。
在WEEX Labs的实战中,我们通过“GPT-4o控场(Leader)、Claude创作(Writer & Critic)、DeepSeek执行(Coder & Researcher)”的搭配,构建起一套高性价比、高效率的AI协作网络,既控制了调用成本,又保障了任务质量。
希望这份实战选型指南,能帮你避开选型误区,快速为自己的AI团队选对“数字大脑”,让多智能体真正发挥价值,提升协作效率、降低运营成本。
