 夜雨聆风
夜雨聆风OpenClaw 的记忆困境
如果你用过 OpenClaw(一个本地部署的 AI Agent 平台),你会发现一个问题:
你今天跟它聊了项目 A 的进展,明天问它“昨天我们聊了什么”,它一脸茫然。你在飞书群里让它帮你写文档,过两天再问,它完全不记得你的写作风格和项目背景。
你的 AI 助手每天都是新的一天——它什么都不记得。

问它上周你聊过什么,它不知道。让它总结上个月的项目进展,它得重新来过。你发的每一条消息,对它来说都是第一次见面。
这不是 OpenClaw 的问题,也不是某个 AI 工具的 bug——这是整个 AI 行业的设计缺陷。
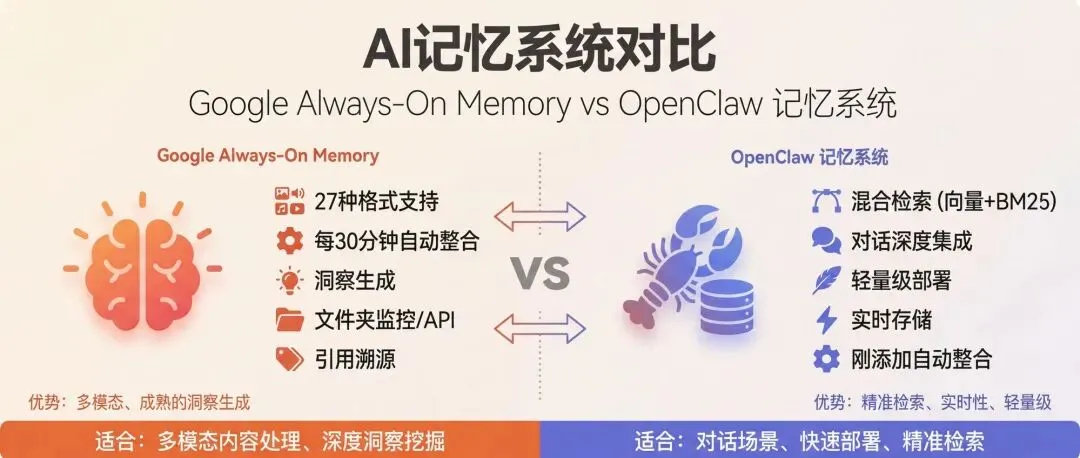
OpenClaw 虽然支持多 Agent 协作、飞书文档操作、工作流自动化,但它缺少一个关键能力:持久化的、会思考的记忆系统。
好消息是,Google 开源了一个解决方案。
为什么现有的记忆方案都不行?
给 AI 加记忆,这事很多人都在做。但目前的方案,都有点问题。

第一种方案:向量数据库 + RAG
RAG(检索增强生成):一种让 AI 先查资料再回答的技术。可以想象成考试时允许翻书,答案自然更准确。
这个方案的问题是:太被动了。你把信息塞进去,它就躺在那里。系统不会主动思考这些信息之间有什么关系,也不会发现什么新洞见。
就像把所有书堆在图书馆里,但从来没有人去整理分类。
第二种方案:对话总结
每次聊完天,让 AI 总结一下重点。这个方案的问题是:细节丢了。总结越压缩,信息越少。而且不同的对话之间没有任何关联。
就像你只记日记的摘要,十年后回头看,只知道“今天很开心”,但完全忘了为什么开心。
第三种方案:知识图谱
把信息画成一张大网,实体之间用关系连接。这个方案的问题是:太贵了。搭建和维护都需要大量资源,而且很容易变得复杂到无法管理。
真正的问题是什么?
这些方案都只做了“存储”,没有做“整合”。
人类的大脑不是这样的。我们睡觉的时候,大脑会回放白天的经历,把新知识和旧知识连起来,把重要的留下来,把重复的压缩掉。
真正的记忆不是存储,而是理解、连接和整合。
一个像人脑一样工作的 AI 记忆系统
Google 开源了一个项目,叫 Always-On Memory
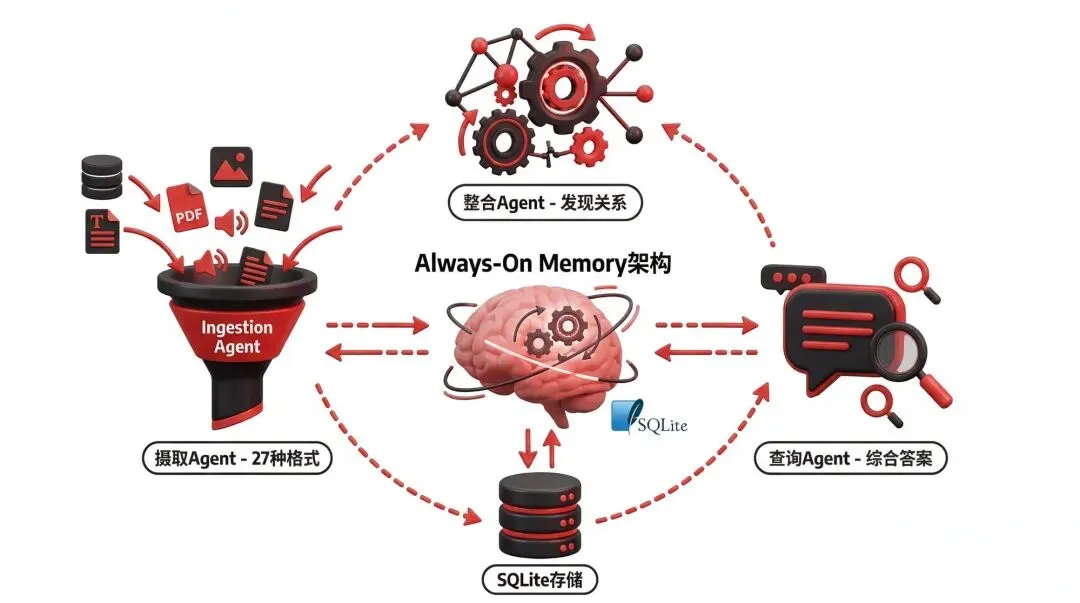
Agent。它的核心思路是:让 AI 像人脑一样,在后台持续地处理、整合、连接信息。
不需要向量数据库,不需要复杂的 embedding,就是用一个轻量级的 LLM,不停地读、想、写。
它是怎么做到的?
图 1:系统整体架构,三个核心 Agent 分工协作
三步走:摄取、整合、查询
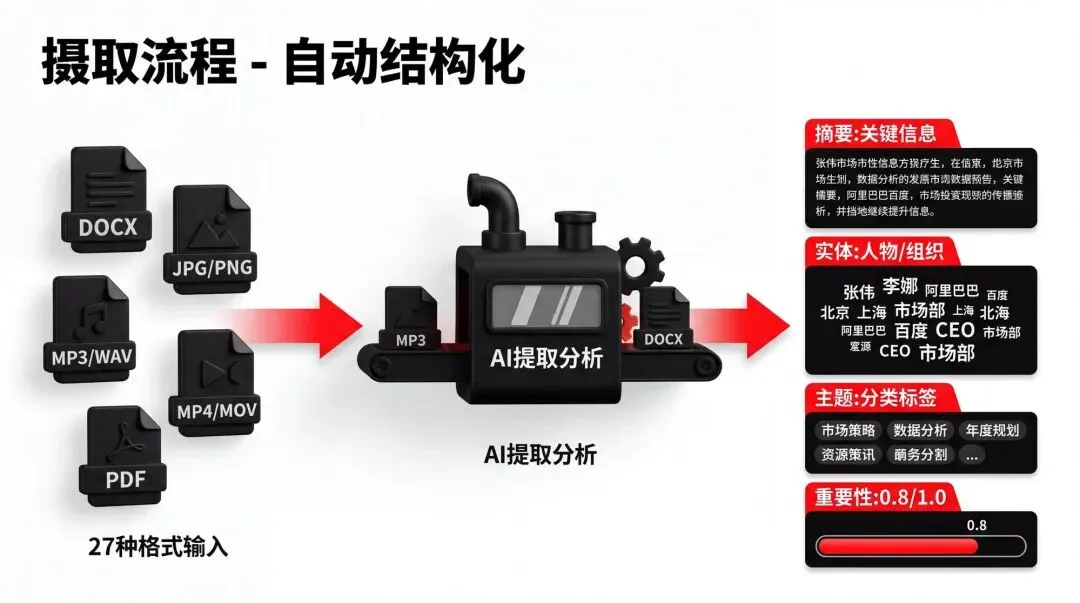
第一步:摄取(Ingest)
你把任何东西丢给它都行。文本、图片、音频、视频、PDF,一共支持 27 种格式。
多模态(Multimodal):AI 能同时理解文字、图片、音频等多种形式的信息。就像人能同时看图、听声音、读文字一样。
系统会自动提取结构化信息:这段内容的摘要是什么?提到了哪些实体?属于什么主题?重要程度有多高?
举个例子,你发给它一段新闻:
“Anthropic 报告显示,62% 的 Claude 使用与代码相关。AI 代理是增长最快的类别。”
系统会输出: - 摘要:Anthropic 报告 62% 的 Claude 使用与代码相关…… - 实体:Anthropic、Claude、AI 代理 - 主题:AI、代码生成、代理 - 重要性:0.8(满分 1.0)
有三种方式投喂信息: - 文件监控:把文件丢进 ./inbox 文件夹,5-10 秒内自动处理 - 网页上传:通过 Streamlit 界面上传 - HTTP API:用代码 POST 过去
第二步:整合(Consolidate)
这是整个系统最像人脑的地方。
默认每 30 分钟,系统会运行一次“整合”任务。它会把这段时间收集的记忆拿出来,找找它们之间的关系,发现一些你可能没注意到的洞察。
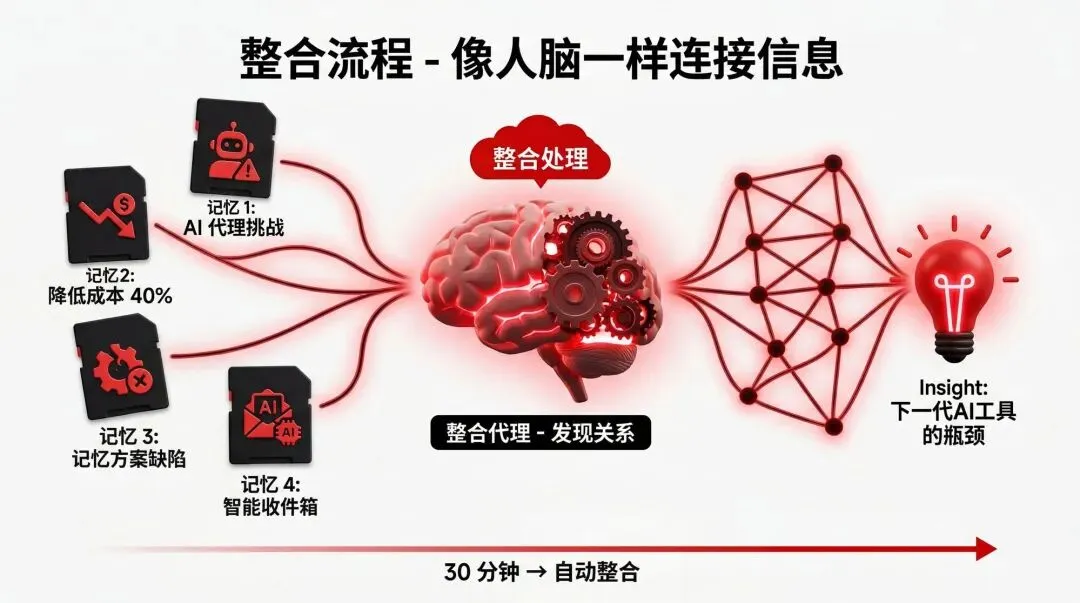
比如你有这四条记忆:
“AI 代理增长很快,但可靠性是个挑战”
“Q1 优先级:降低推理成本 40%”
“现有的 LLM 记忆方案都有缺陷”
“智能收件箱的想法:给邮件加持久 AI 记忆”
系统会发现: - 记忆 1 和记忆 3 有关:代理的可靠性问题,本质是记忆架构不行 - 记忆 2 和记忆 1 有关:降低成本才能规模化部署代理 - 记忆 3 和记忆 4 有关:智能收件箱就是重建式记忆的一个应用
然后它会给你一个洞察:
“下一代 AI 工具的瓶颈,是从静态 RAG 到动态记忆系统的转变。”
这种“连接”的能力,是向量数据库做不到的。因为向量数据库只做相似度匹配,不做语义理解和推理。
第三步:查询(Query)
你想问什么就问什么。
系统会读取所有的记忆和整合洞察,然后综合出一个答案。关键是,每个观点都会标注来源。
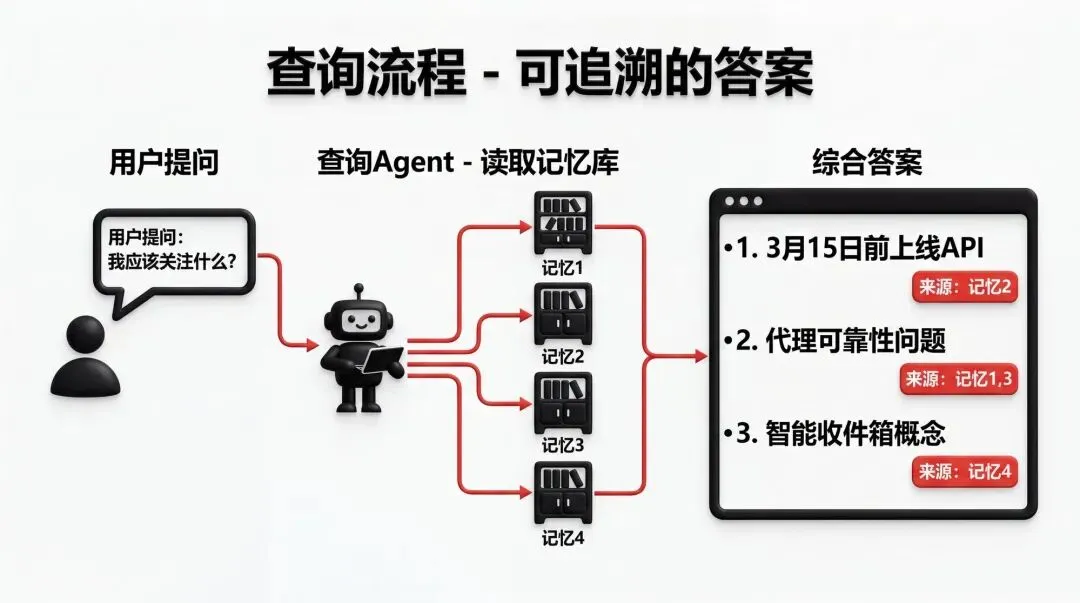
比如你问“我应该关注什么?”
系统会回答:
根据你的记忆,建议优先: 1. 3 月 15 日前上线 API 【来源:记忆 2】 2. 代理可靠性问题【来源:记忆 1】,可以用重建式记忆方案【来源:记忆 3】来解决 3. 智能收件箱概念【来源:记忆 4】验证了市场对持久 AI 记忆的需求
这种带来源引用的回答,让你知道 AI 不是在瞎编,每句话都有据可查。
为什么用 Gemini Flash-Lite?
这个系统是 24 小时运行的。成本和速度比智商更重要。
快:延迟低,适合持续后台运行 便宜:每次调用成本极低,24/7 运行也花不了多少钱 够用:提取结构、找关系、综合答案,这些事它都能干
LLM(大语言模型):像 GPT、Claude、Gemini 这样的 AI 模型。它们通过海量文本训练,能理解和生成人类语言。
五分钟跑起来
安装很简单:
git clone https://github.com/Shubhamsaboo/always-on-memory-agent.git
cd always-on-memory-agent
pip install -r requirements.txt
设置 API 密钥:
export GOOGLE_API_KEY="your-gemini-api-key"
然后启动:
python agent.py
就这样。系统会: - 监控 ./inbox/ 文件夹,自动处理新文件 - 每 30 分钟整合一次记忆 - 在 http://localhost:8888 提供查询服务
想要图形界面?还有个 Streamlit 面板:
streamlit run dashboard.py
这事为什么重要?
大多数 AI 工具都是“一次性”的。 你问它,它答你,然后它就忘了。

但真正有价值的信息,往往藏在碎片化的对话和文档里。如果 AI 能记住这些碎片,并且主动发现它们之间的关系,那它的价值就不只是“回答问题”了——它能帮你“发现洞见”。
这个项目做了一件事:把静态的知识库,变成了一个会思考的记忆系统。
就像你的大脑不是硬盘,而是一个不断整理信息的处理器。
真正的智能,不是记住所有东西,而是知道什么重要,以及为什么重要。
项目地址:https://github.com/GoogleCloudPlatform/generative-ai/tree/main/gemini/agents/always-on-memory-agent
技术栈:Google ADK + Gemini 3.1 Flash-Lite + SQLite + Streamlit
许可证:MIT
