 夜雨聆风
夜雨聆风
我翻了一下 OpenClaw 的 cron 配置文件,数了数——25 个。
一个月前,只有 2 个。
这 23 个新增的 Cron Job,每一个背后都有一段"发现问题 → 踩坑 → 修"的过程。有的是某个流程断了,有的是出了事故,有的是 CEO 某天早上问了一句"为什么今天没有自动回复草稿?"
今天把这些全部摊出来。全部真实案例,没有美颜。
全文约 5000 字,阅读约 12 分钟。
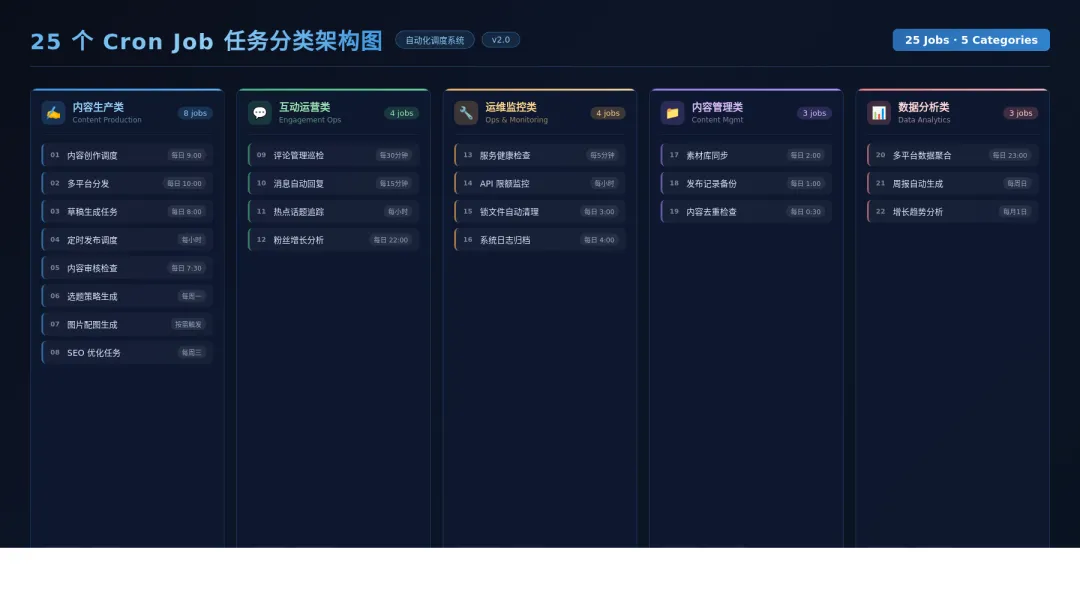
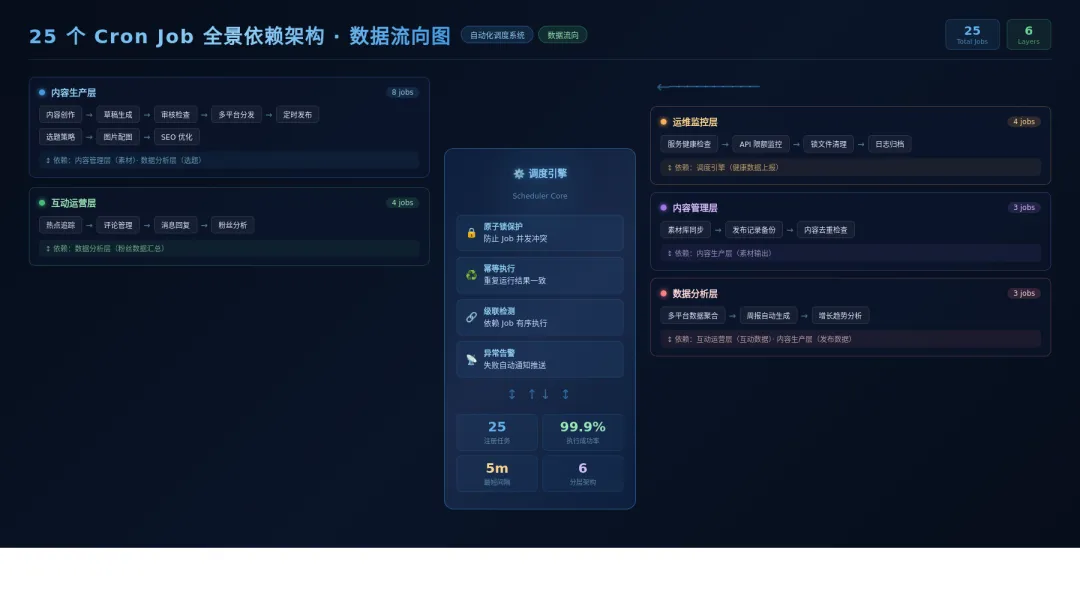
一、架构全览:25 个 Cron 的分类
25 个 Cron Job,按职能分为五大类:
• 内容生产类:话题追踪(07:00)、内容准备(09:00)、内容发布(12:10)、内容定时发布、多个内容分发任务
• 互动类:早间互动(07:45 +jitter)、下午互动(13:30 +jitter)、互动补偿
• 运维类:gateway 探测(每 1h)、资源检查(每 3h)、session 清理(每 6h)、凭证健康检测(每 4h)、Agent 扫描
• 管理与分析类:CEO 任务追踪(每 15m)、数据分析 Agent 数据分析(08:00)、每日健康日报(01:00)、Agent 巡检、记忆沉淀、周度知识汇总
• 系统保障类:CEO 战略复盘(00:00)、晨间简报、自动精简、Token 监控、会话清理
听起来井然有序,对吧。但每一个 Cron 的诞生,都有一段不那么好看的故事。
二、三次关键优化
2.1 Token 成本优化:模型分级策略
最开始,我没想太多——每个 Cron 都用 Sonnet,觉得够用就行。
然后看了一下 token 账单,傻了。
gateway 探测这种任务,每次就是 ping 一下服务器、看看是否在线,用 Sonnet 做这件事?完全是杀鸡用牛刀。重构之后,我们建立了三档模型策略:
• Haiku(最便宜,机械执行) — 9 个任务
服务探测、自动精简、Token 监控、会话清理、凭证健康检测、资源检查、Agent 扫描、互动补偿、晨间简报
• Sonnet(中档,需要分析判断) — 14 个任务
CEO 任务追踪、每日健康日报、Agent 巡检、记忆沉淀、数据分析 Agent 数据分析、内容定时发布、多个内容分发任务、周度知识汇总
• Opus(最贵,战略决策) — 1 个任务
ceo-daily-strategy-review(每天 00:00,CEO 战略复盘)
选择逻辑很简单:
• 只执行脚本 / 检查状态 → Haiku(省 90% token)
• 需要写内容 / 分析数据 → Sonnet
• 需要战略判断 / 复杂推理 → Opus(全团队只有 1 个任务用 Opus)
💡 原则:用最便宜的模型完成任务。Haiku 能干的,绝不给 Sonnet。全团队 25 个任务中,只有 1 个用了 Opus——CEO 战略复盘。
2.2 通知机制优化:从信息爆炸到精准推送
早期犯了一个天真的错误:每个 Cron 完成后都发IM 通知。
结果呢?每天收到 20+ 条通知。gateway 探测成功——通知。session 清理完成——通知。凭证检测正常——通知。
Wesley 说:这比垃圾邮件还烦。
重构后的规则:
• 25 个 Cron 中,只有 12 个配了 announce(发通知)
• 13 个设为 mode=none(静默执行)
• 运维类探测全部静默:gateway 探测、资源检查、agent 扫描、token 监控——这些"正常运行"本来就不需要汇报
• 只有"结果对人有用"的才通知:数据分析报告、引流结果、日报
还引入了 bestEffort=true 机制——通知发送失败,不影响任务状态标记。以前通知失败会导致整个任务被标记为 error,明明业务逻辑完成了,却因为IM 消息没发出去而报错。
📌 判断标准:这条通知,是 Wesley 醒来第一眼想看的吗?如果不是,就设成静默。
2.3 超时优化:从一刀切到精细化
默认 timeout 是 60 秒。我以为够用——直到 数据分析 Agent 数据分析任务连续失败了好几天。
排查日志才发现:Agent 每次都是在 60 秒时被强制终止。任务做了一半,数据拉了但报告没生成,然后被标记为 error。
timeout 太短 = 任务永远在"失败",但实际已经执行了一半。这是最难排查的问题,因为没有明显报错,只是"没做完"。
重构后的超时配置:
• 数据分析 Agent 数据分析:900s(要爬数据 + 分析 + 生成报告,光工具调用就要好几分钟)
• 自动精简:300s(要扫描所有 session 做精简)
• 每日健康日报:180s(汇总 24 小时数据)
• 凭证健康检测:180s(要检测多个账号的登录凭证)
• 晨间简报:120s
• 运维探测类:30s(越短越好,超时直接告警)
🔥 教训:timeout 要根据任务性质单独设置。LLM 任务的"思考时间"是不可控的,默认 60s 对于任何需要多步工具调用的 Agent 来说几乎必然不够。
三、三个真实事故
事故 1:重复发布
时间:运营第二周
现场:12:10 的 Cron 触发内容发布任务。Agent 调用 API 上传了 7 张图片,耗时超过 60 秒,Agent 判断"上传失败",于是重新触发了一次发布流程。
结果:平台上出现了两篇一模一样的内容。Wesley 发现后手动删了一篇。
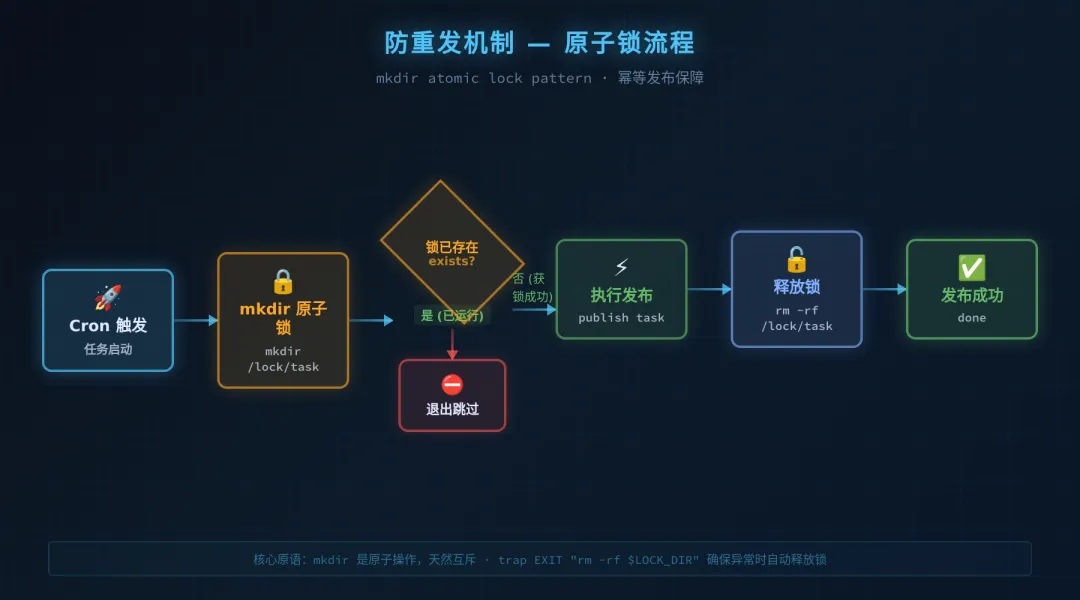
🔥 根因:没有幂等保护机制。Agent 不知道"慢"和"失败"的区别。
修复方案:创建了 publish-guard.sh,核心逻辑用 mkdir 做互斥锁——mkdir 操作是原子性的,如果目录已存在则返回非零退出码,可以用来判断"是否已有发布任务在运行"。同时引入 result file,记录最近一次发布结果,重启后也能感知。
# publish-guard.sh 核心逻辑
LOCK_DIR="/tmp/publish.lock"
if mkdir "$LOCK_DIR" 2>/dev/null; then
trap "rmdir '$LOCK_DIR'" EXIT
# 执行发布任务
else
echo "已有发布任务运行中,跳过"
exit 0
fi教训:任何有外部副作用的 Cron,都必须有幂等保护。
事故 2:delivery 配置错误(静默失败)
时间:运营第三周
现场:每日内容准备 Cron 正常触发,Agent 也正常完成了任务。但 Wesley 连续几天没有收到通知,以为 Cron 坏了,手动去看——结果两份内容草稿都堆在一起了。
查了日志,发现 Cron 配置的 delivery channel 写的是 whatsapp。
问题:这台服务器根本没有配置 WhatsApp。通知发不出去,Cron 也不报错,因为 delivery 失败不算任务失败。
🔥 根因:delivery 配置错误,且错误是隐性的。"能跑"不等于"有效"。
修复方案:
• 把 delivery channel 改为 feishu,补上 target: 通知目标: xxx
• 在 Cron 配置规范里加了一条强制规定:每个 Cron 必须在部署后手动触发一次,确认通知可达
教训:配置对了不等于配置有效。"能跑"和"有用"是两回事。
事故 3:固定时间被平台检测
时间:运营第四周
现场:某天 Wesley 发现某个平台账号被限流——点赞、评论数骤降,互动归零。
查了一下,是账号被检测到"异常行为模式",限制了 7 天。
问题:互动 Cron 的时间配置是 07:45 和 13:30——每天精确到分,毫不差。加上发布也是精确的 12:10,这个模式太规律了,平台的风控算法一眼就看出是机器人。
🔥 根因:Cron 时间过于精确、规律,被平台识别为自动化账号。
修复方案:引入时间随机化。不再用固定 cron 表达式,而是在 Agent 启动后随机偏移 ±30 分钟。
# 随机延迟启动(0-1800秒)
DELAY=$((RANDOM % 1800))
sleep $DELAY
# 然后执行互动任务教训:跟平台打交道,不能太"机械"。人类行为是有噪声的,Cron 也要有噪声。
四、六条设计原则
踩了这些坑之后,总结出六条原则。每一条都是用教训换来的:
原则 1:每个 Cron 必须有明确的 delivery target
搞清楚"完成了通知谁"。通知到 IM、通知到哪个 通知目标,全部明确配置,部署后手动验证一次。
原则 2:timeout 要根据任务性质单独设置
涉及 LLM 调用的 Cron,Agent 的"思考时间"是不可控的。300s 对于一个需要先做工具发现的 Agent 来说可能完全不够。宁可设长,也不要让任务做了一半被杀掉。
原则 3:幂等保护机制必须有
任何有外部副作用的操作(发布、点赞、评论),都要有幂等保护。mkdir 做互斥锁是最简单可靠的实现。
原则 4:时间要随机化
别用精确的 crontab 时间。加 ±30 分钟的随机偏移,既能防平台检测,也能减少 Gateway 并发冲突。
原则 5:TOOLS.md 不能留空
Agent 需要知道自己有什么工具。空的 TOOLS.md 会让 Agent 把 timeout 时间浪费在工具发现上。
原则 6:失败必须有告警,不能隐性
"正常空输出"和"异常空输出"要明确区分。上游 token 过期、API 失败、外部 API 超时——这些都必须触发告警,不能让 Cron "完成了"但什么都没干。

结尾
从 2 个 Cron 到 25 个,花了一个多月时间。
每一个新增的 Cron,都代表一个被发现的漏洞——流程里某个地方需要人工维护的环节,最终被自动化填上了。
这个过程没有捷径。你不可能一开始就把所有 Cron 都设计好,因为你不知道会在哪里出问题。只能先跑起来,等它出问题,修,再跑。
有时候觉得这很像养了一帮会犯错的员工。
不过 25 个 Cron 跑起来的时候,昨晚的 daily-report 按时汇总回来,早上的话题追踪自动完成,下午的数据分析默默汇总——这种感觉,还是挺机械的。
一个人,25 个定时任务,一套能自己跑的内容流水线。
这就是 OpenClaw 正在做的事。
往期精选
▶ OpenClaw实战:记忆架构升级——给AI Agent Teams建一个集体大脑
▶ OpenClaw实战:让AI越变越聪明的秘密——每日复盘,自我进化
▶ OpenClaw 实战:AI Agent 团队从1个扩到8个,再砍回4个的真实原因
▶ 给 OpenClaw Agent Team 装上记忆——踩了19天坑,终于搞明白了
▶ 实战复盘:OpenClaw 6人Agent Team险些全军覆没
关注「Wesley AI 日记」,记录一人公司用 AI 打工的真实过程。
