 夜雨聆风
夜雨聆风深度体验 OpenClaw(小龙虾)一段时间后,我已经基于它搭建了自媒体自动发布、数据分析、设备故障诊断等多个 Skill,实战下来一个非常明确的感受:在程序员这个方向上,它真的能替代掉 80% 的日常工作。
但想真正用好小龙虾,绝不是停留在 “会用” 的层面,而是要吃透它的底层架构与设计思想。只有理解核心机制,才能把它用成真正的生产力工具,而不是简单的玩具。
今天,我先从它最关键、最核心的记忆系统入手,做一次完整拆解与分析。
源码:https://github.com/openclaw/openclaw
核心定位与架构
核心原则:Markdown 文件为唯一事实来源,拒绝黑盒,所有记忆落地为本地可编辑的纯文本文件。 默认插件:由 memory-core提供记忆搜索工具,可通过plugins.slots.memory = "none"禁用。源码:https://github.com/openclaw/openclaw/tree/main/extensions/memory-core 存储路径:默认位于工作空间 ~/.openclaw/workspace,可通过agents.defaults.workspace配置。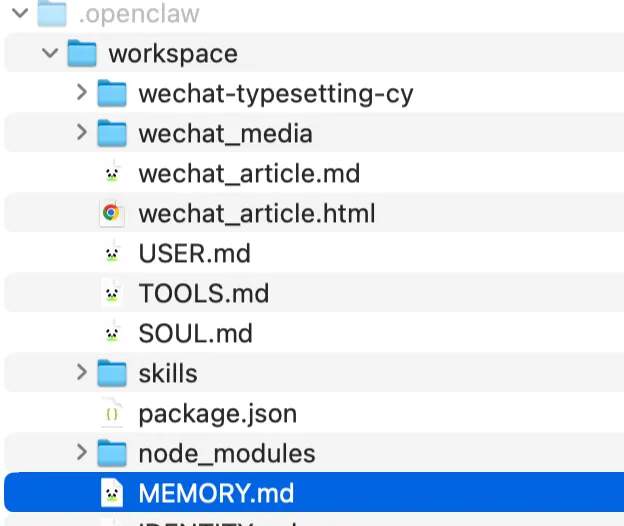
双层记忆体系
| 短期记忆 | memory/YYYY-MM-DD.md | ||
| 长期记忆 | MEMORY.md |
何时写入记忆
什么时候写入长期记忆
满足以下任意一种 → 必须写入 MEMORY.md
个人偏好、习惯、风格设定 重要决策、规则、约定 需要永久记住的事实、知识 用户明确说:记住这个 需要跨会话、跨天保留的内容
总结:要永久记住、反复使用、不会过期的 → 长期记忆
举例:当我在对话框输入保存文件到哪个地方,自动会写入MEMORY.md;

什么时候写入短期记忆
满足以下任意一种 → 写入 当日短期记忆文件
当天的对话、上下文 当天的任务、待办、临时信息 当天的运行日志、中间结果 不需要长期保存、只在近期有用的内容 不需要跨天长期记住的临时信息
总结:当天用、近期用、会过期、临时的 → 短期记忆
memory/YYYY-MM-DD.md 此文件夹默认没有,触发会生成。
举例:存天气
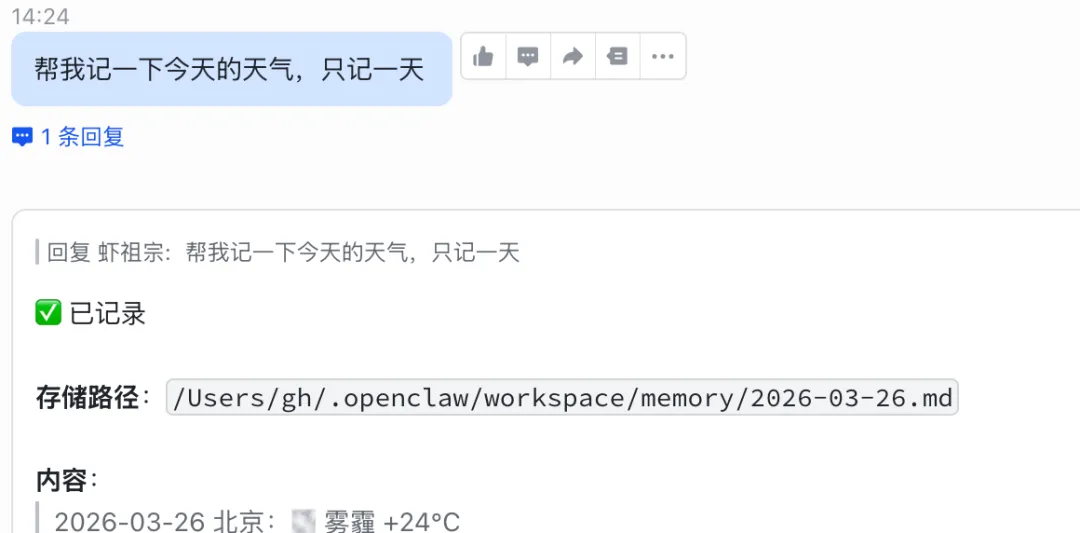
自动记忆刷新
触发时机:会话 Token 接近压缩阈值时(由 softThresholdTokens控制,默认软阈值为上下文窗口 - 预留 Token - 4000)。行为:静默触发智能体回合,提醒将关键信息写入持久化文件,用户无感知(默认响应 NO_REPLY)。配置:通过 agents.defaults.compaction.memoryFlush启用 / 禁用,需保证工作空间可写。
{agents:{defaults:{compaction:{reserveTokensFloor:20000,memoryFlush:{enabled: true,softThresholdTokens:4000,systemPrompt:"Session nearing compaction. Store durable memories now.",prompt:"Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store.",},},},},}
记忆管理工具
Agent 可通过显式工具操作记忆,核心工具如下:
memory_search | ||
memory_get | ||
memory_store | ||
memory_forget |
记忆工具的工作原理
memory_search = 语义搜索记忆片段 → 不读全文 memory_get = 精准读取某个文件 → 可读部分行 都必须开启 memorySearch.enabled 才能用 文件访问有权限控制,不能乱读
1. memory_search到底做什么?
搜哪里?
搜两个地方:
根目录 MEMORY.mdmemory/ 文件夹下所有 .md文件(所有日记、短期记忆)可能还有历史会话片段 (后文会说明历史会话片段搜索机制) 怎么搜?
语义搜索,不是搜关键词,是搜意思。
比如你问 “我喜欢什么颜色”,它能找到 “用户偏爱蓝色”。
怎么切分内容?
把文件切成一块一块:
就像把书切成一页一页,但页边重叠一点,保证句子不被砍断。
每块大约 400 token 块和块之间重叠 80 token(防止切断语义) 返回什么?
片段内容(一小段,最多 700 字符) 哪个文件 第几行到第几行 匹配分数 用了什么模型 绝对不返回什么?
不返回完整文件!
不会把整个 MEMORY.md 扔给模型,只会扔最相关的一小段。
2. memory_get到底做什么?
干什么?
直接读文件内容,不是搜,是读取。
怎么读?
你告诉它:
读哪个文件(相对路径) 从第几行开始 读多少行 能读哪些文件?
默认只能读:
想读其他文件?
必须配置在 memorySearch.extraPaths 才能读 ,否则不让读,安全限制。
MEMORY.mdmemory/下的文件
支持通过
memorySearch.extraPaths配置索引非工作空间的 Markdown 文件(绝对 / 相对路径均可),实现跨目录记忆整合。 (记忆不一定要保存到.openclaw中,可以灵活寻找保存路径)
额外记忆路径配置
agents: {defaults: {memorySearch: {extraPaths: ["../team-docs", "/srv/shared-notes/overview.md"]}}}
3. 共同限制:必须开启才能用
配置里必须打开:
memorySearch.enabled = true //决定两个工具如果是 false,memory_search 和 memory_get 都不能用,Agent 完全无法访问记忆。
模型搜索记忆机制
OpenClaw 的记忆搜索 :混合搜索,向量搜索(懂意思,不懂精确字符) + BM25 关键词搜索(懂精确字符,不懂意思)
模型索引记忆内容及时机
1. 索引什么内容?(文件类型)
2. 索引存在哪?(索引存储)
索引不是存在文本里,是存在 SQLite 数据库 每个智能体(Agent)独立一个库,互不干扰 路径长这样:
~/.openclaw/memory/xxx-xxx-xxx.sqlite可以配置路径,支持 {agentId}占位符
3. 索引新鲜度(最重要、最核心)
a、监视器一直在盯着你的记忆文件
你改了 MEMORY.md 或日记,系统立刻知道。
b、但不会马上更新索引,而是等 1.5 秒(去抖动)
文件修改后,OpenClaw 不会立刻更新索引,而是等 1.5 秒没再改动,才真正执行一次索引同步。
c、真正更新索引的时机
只会在这 3 种时候异步更新:
你新开会话时 你执行记忆搜索时 定时自动更新
好处:不卡、不占资源、不影响速度。
4. 重新索引触发器(模型 / 配置一变就全量重建)
这是安全机制,保证搜索永远准确:
只要你改了以下任意一项:
向量模型(本地 / OpenAI/Gemini) 模型名称变了 API 地址变了 分块大小变了 重叠 token 变了
系统就知道:
旧索引作废 → 自动全部删掉 → 重新全量建索引
你完全不用管,它自己处理。
本地电脑查看样子:

会话记忆搜索
会话记忆让 Agent 拥有了 “完整历史视角”,但它依然遵循文件优先、本地优先、安全隔离的设计原则。
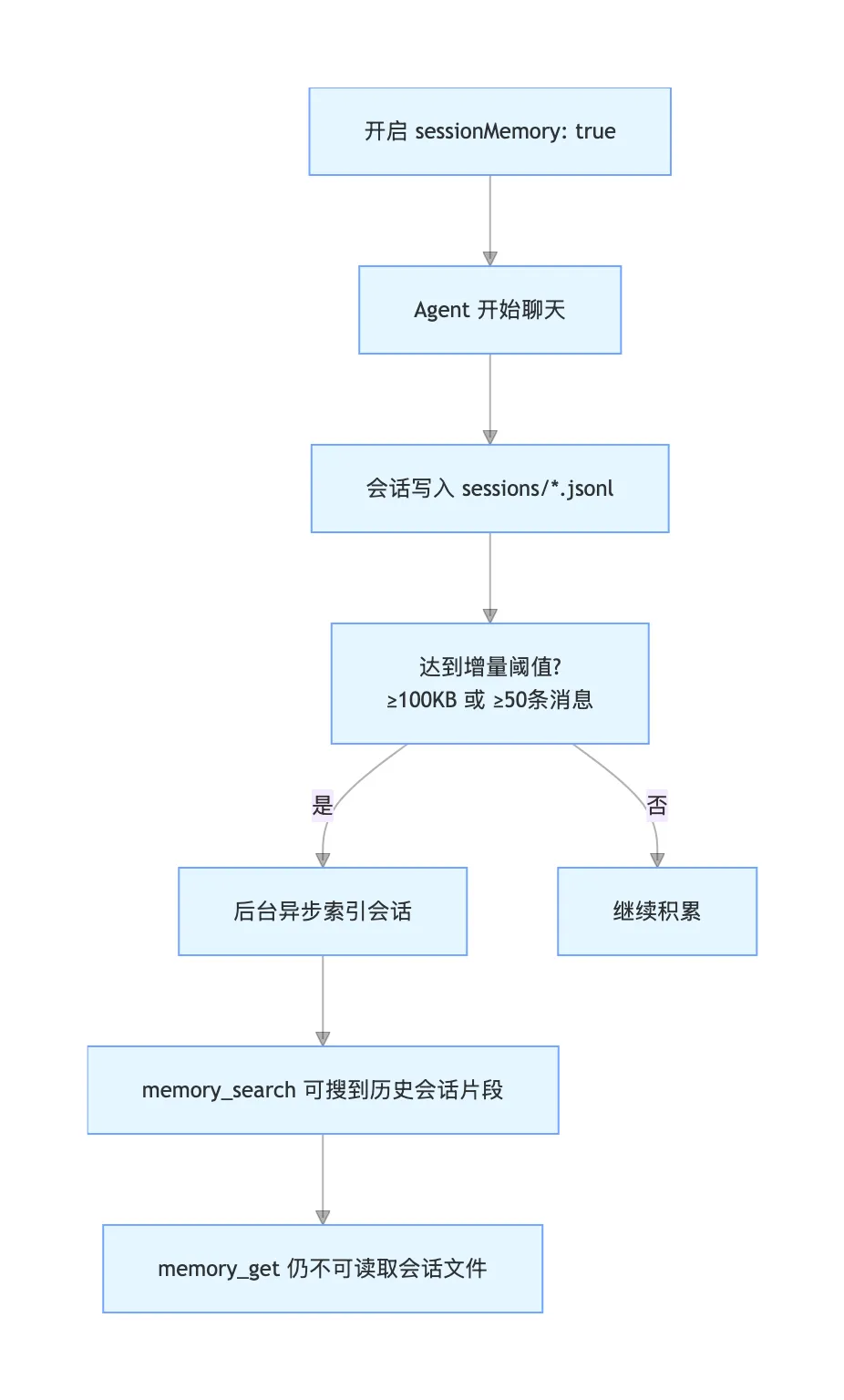
会话索引是选择加入的(默认关闭)。
会话记忆 = 让 Agent 搜历史聊天 默认关闭,手动开启 后台索引,不卡界面 达到 100KB / 50 条 才索引 (可根据参数改) 只能搜片段,不能读全文 每个 Agent 独立隔离 存在本地磁盘,注意权限
你可以选择性地索引会话记录并通过 memory_search 呈现它们。
agents: {defaults: {memorySearch: {experimental: {sessionMemory: true},sources: ["memory", "sessions"]}}}
配置参数
agents:{defaults:{memorySearch:{sync:{sessions:{deltaBytes:100000, // ~100 KBdeltaMessages:50// JSONL 行数}}}}}
其他
嵌入缓存
支持 SQLite 缓存块嵌入,这样重新索引和频繁更新(特别是会话记录)不会重新嵌入未更改的文本。,默认最大缓存条目 50000。
defaults: {memorySearch: {cache: {enabled:true,maxEntries:50000}}}}
安全与边界
隔离性:多 Agent 记忆完全隔离,按 Agent ID 独立存储索引与向量。 隐私保护: MEMORY.md仅在私人会话加载,群组会话不加载,避免敏感信息泄露。信任边界:会话日志存储于本地磁盘,需注意磁盘访问权限管控。
