 夜雨聆风
夜雨聆风2026年春节到现在openClaw 龙虾实在是太火爆了,如果见面不聊“养龙虾”都感觉不是一个时代的人了,龙虾虽好但消耗的 “token” 以及带来的安全问题不容忽视,生产环境要慎之又慎,网上有句话说的挺好,现在的 “token” 堪比黄金(虽然目前金价在暴跌),今天打算聊聊大数据平台CDH5.16.2+Hive的备份
a
借用强哥的图
首先感谢哆哆老师、田老师,谢谢了,谢谢兄弟们
首先感谢哆哆老师、田老师,谢谢了,谢谢兄弟们
客户环境:大数据平台是CDH 5.16.2,Hive 1.1
环境信息:数据量极大的Hive分布式集群,预期容量PB级或接近PB,需要多节点并发备份
技术分析:通过脚本方式备份,从方案角度:备份一体机能够提供一个大存储量和高重删能力的NAS存储,主要考虑的是备份脚本将数据写入到NAS中。写入后,备份一体机可以根据时间点对这个NAS文件系统功能打快照,作为备份副本记录。类似于NBU的UShare方案
诉求:有Hive的备份脚本技术能力,能够通过脚本的形式挂载NAS,全量和增量备份数据到NAS上。由于数据量极大,所以脚本支持多节点同时备份数据也是需要的。
备份策略
▌ 全量备份(首次)
备份对象 | HDFS Hive 仓库目录(/user/hive/warehouse)+ Hive Metastore 数据库 |
执行方式 | 按系统分批执行,每批完成后验证,再执行下一批 |
并发策略 | 每个节点组同时启动 distcp,默认 20 线程/节点,可根据网络负载调整 |
预计时长 | 2PB ÷ 多节点并发(有效速率约 500MB/s)≈ 46 天(分批执行,不连续) |
执行窗口 | 建议每月 16 日起(避开 1-15 日导数时间),夜间低峰时段执行 |
▌增量备份(每月)
增量识别 | 基于 Hive 分区时间戳 + HDFS 文件 mtime,仅备份上次备份后新增/修改的分区 |
数据量 | 约 20TB/月,LTO-9 单驱动器约 14 小时完成,建议多驱动器并行 |
执行频率 | 每月一次,建议每月 16-20 日之间执行 |
Metastore | 每次增量备份同步 Hive Metastore 数据库(mysqldump),确保表结构与数据一致 |
▌ 断点续传与容错
• distcp 支持 -update 参数,中断后重新执行自动跳过已完成文件,无需重传
• Avatarstor 记录每次备份任务的文件清单与校验值,中断恢复后自动对比补传
• 每个备份任务完成后自动校验 MD5,确保数据完整性
数据恢复方案
支持两种恢复模式,根据实际故障场景灵活选择:
恢复模式 | 适用场景 | 预计恢复时间 |
文件级恢复 | 单张表或单个分区数据损坏,精确恢复指定路径 | < 2小时(视数据量) |
系统级恢复 | 整个系统数据损坏或迁移场景,全量恢复到新集群 | 按数据量估算,2PB约需3-5天 |
• 恢复时通过 distcp 从磁带(经 NAS 缓冲)反向写回 HDFS,支持并发多线程加速
• 恢复前自动校验备份数据完整性,确保恢复数据可用
• 支持按时间点选择恢复副本(每月快照),灵活回滚
方案优势
• 低成本长期保存:磁带单位存储成本约为磁盘的 1/3,2PB 数据长期保存经济性显著
• 原生工具集成:基于 Hadoop distcp,客户现有集群无需安装额外 Agent,兼容 CDH 5.16.2
• 透明可审计:备份脚本开放给客户查看,执行日志完整记录,满足合规要求
• 断点续传:中断后自动续传,不浪费已完成的传输,降低备份失败风险
• 不影响业务:备份窗口在月中下旬低峰期执行,并发线程数可动态限速
• Metastore 一体备份:数据文件与表结构同步备份,恢复后 Hive 可直接使用
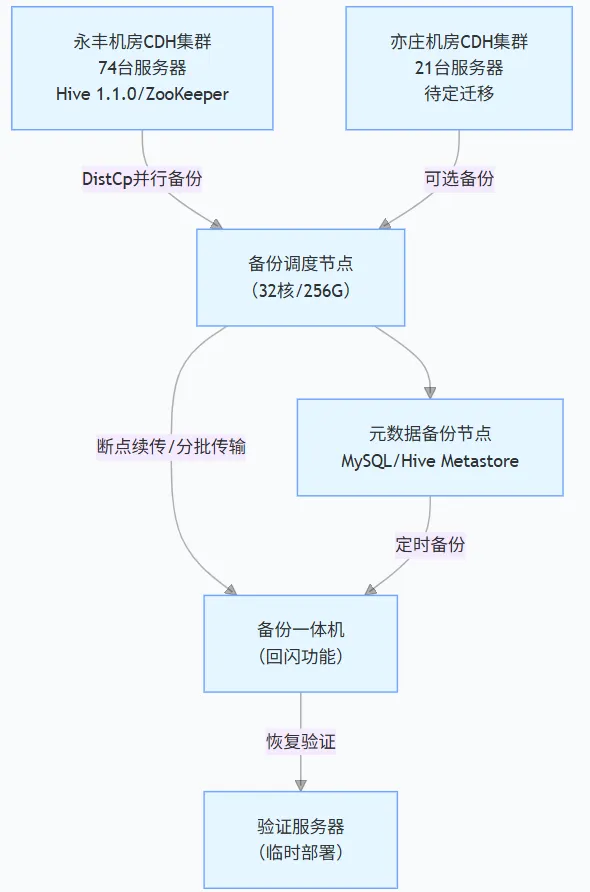
Hadoop生态系统中Hive数据和元数据的备份策略,需要包括调度、传输、存储,最终到验证,形成一个闭环,其中元数据备份节点负责备份Hive的元数据(表结构、分区信息等):
1、并行备份,定制备份;
2.高性能调度:使用高配置的调度节点来管理复杂的备份任务;
3.可靠性保障:通过“断点续传/分批传输”确保大数据量传输的稳定性;
4.快速恢复能力:备份一体机的“回闪功能”支持快速的数据恢复;
5.闭环验证:最后一步的“恢复验证”确保了备份不是“死数据”,而是真正可用的;
6、通常存储在结构化数据库中;
7、大数据备份与恢复系统,适用于CDH集群环境下Hive数据的保护;
8、数据备份与场景有关系,如数通设备,载体等等。

微信:oralcems 电话:15311001085
