 夜雨聆风
夜雨聆风如果你在用 OpenClaw 养龙虾,或者跑 Claude Code 之类的 Agent,大概碰过这种事:让它帮你搜一下 Notion 的定价方案,一次请求烧掉几万 Token。
问题出在哪?
传统的网页抓取方案(curl、web_search、浏览器自动化)都是为“人类阅读”或“通用爬虫”设计的,不是为 AI Agent 优化的。
它们有三个致命问题:
问题 1:返回的是“网页实现”,不是“网页内容”
用 curl 抓一个现代网页,你会拿到:
完整的 HTML 结构(标签、属性、嵌套层级)
CSS 样式和 JS 脚本
前端框架的渲染代码
埋点、分析、广告加载器
真正有价值的内容可能只占 1-5%。
问题 2:高风控页面直接失败
很多网站对自动化访问非常敏感:
Reddit、知乎:直接 403 或人机验证
OpenAI、Cloudflare 保护的站点:返回挑战页
动态渲染页面:curl 拿到的是空壳
Agent 拿到的不是数据,而是错误页面。
问题 3:浏览器方案能用,但“抓得太整页”
浏览器自动化能绕过反爬,但它返回的是:
正文 + 导航栏 + 页脚 + 侧边栏 + 评论 + 推荐阅读
Agent 还得再花 Token 让模型当一遍“网页解析器”。
实测:传统方案到底浪费了多少 Token?
我测试了三个真实场景,对比了不同抓取方案的 Token 消耗。
注:Token 按 字符数 / 4 粗估,仅用于横向比较。
场景一:新闻/版本更新追踪
任务: 让 Agent 追踪 OpenClaw 的版本更新,提炼 3 个核心更新点。
测试页面: 腾讯云开发者文章 + 知乎专栏
腾讯云文章
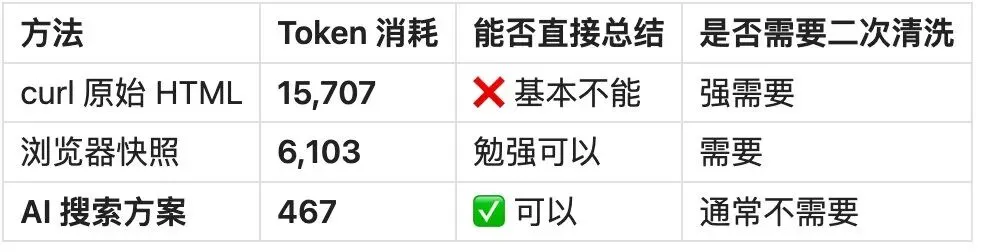
节省比例:97%
知乎文章
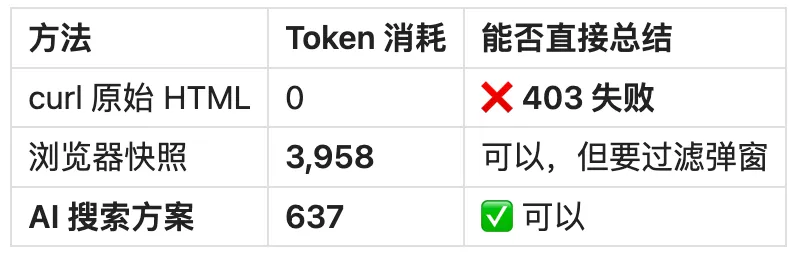
关键发现:curl 直接被拦截,传统方案在高风控页面上会失效。
为什么差这么多?
传统方案返回的是这样的:
<script>埋点代码...</script><style>大段CSS...</style><div class="nav">导航栏...</div><div class="sidebar">推荐阅读...</div><div class="content"><!-- 你真正想要的正文只占 5% --></div>AI 搜索方案返回的是这样的:{ "title": "OpenClaw 2026.3.8 版本更新功能说明", "date": "2026-03-08", "updates": [ "新增 XXX 功能", "优化 YYY 性能", "修复 ZZZ 问题" ]}对于“提炼 3 个更新点”这种任务,Agent 根本不需要吃整页网页。
场景二:竞品定价页
任务: 对比几家 SaaS 的定价方案,生成对比表格。
测试页面: OpenAI Pricing + Notion Pricing
OpenAI Pricing

Notion Pricing(最夸张的案例)
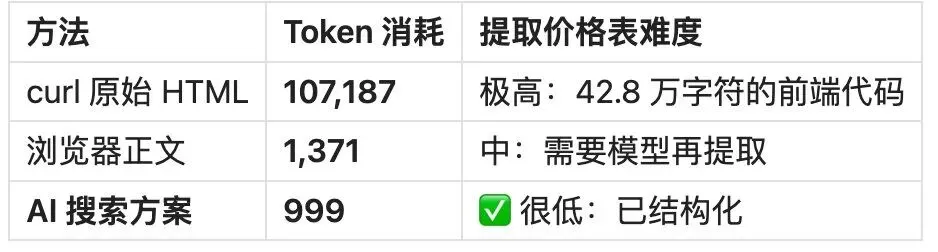
节省比例:99.1%
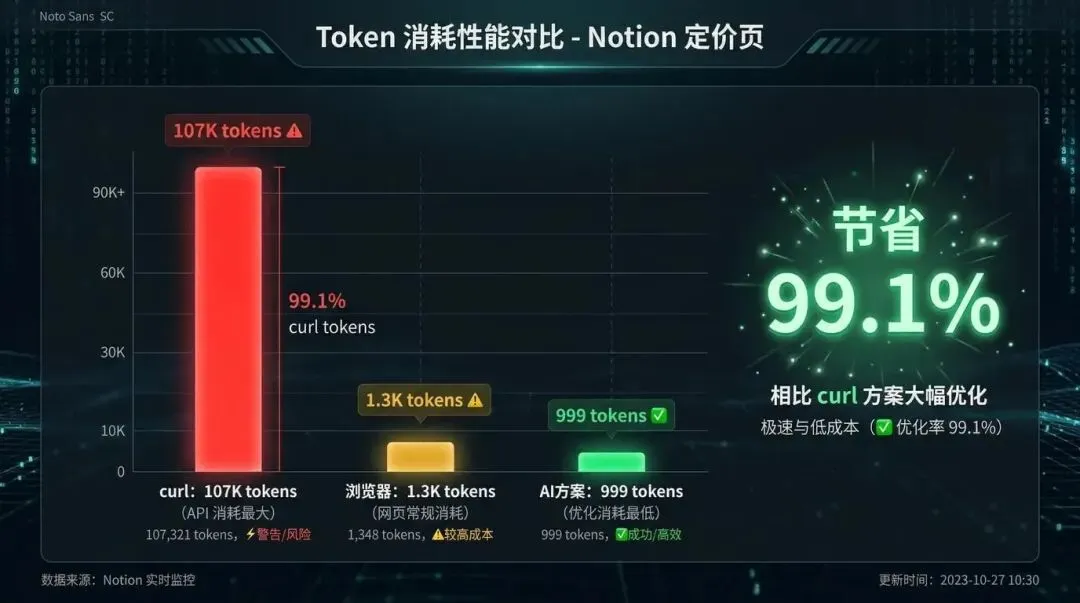
为什么 Notion 页面这么夸张?
现代前端页面充斥着:
React/Vue 组件标记
SSR 渲染代码
内联的 JSON-LD 数据
各种埋点和分析脚本
42.8 万字符的 HTML,真正的价格信息只占 1%。
而 AI 搜索方案直接输出:
{ "plans": [ {"name": "Free", "price": "$0 per member / month"}, {"name": "Plus", "price": "$10 per member / month"}, {"name": "Business", "price": "$20 per member / month"} ]}这不是“把网页抓下来”,这是“直接把网页变成可消费的数据对象”。
场景三:社区讨论/舆情分析
任务: 看看社区对某个产品的真实评价,识别主流观点。
测试页面: Reddit 讨论 + Hacker News 讨论
Reddit 讨论(最能说明成功率问题)
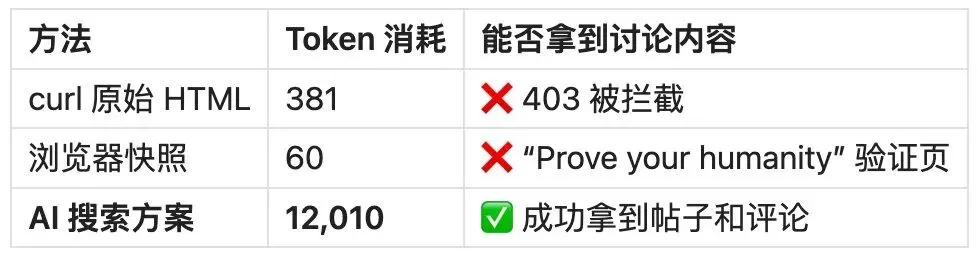
关键发现:传统方案全部失败,AI 搜索方案是唯一能拿到内容的。
Hacker News 讨论
等等,HN 这组浏览器不是更省吗?
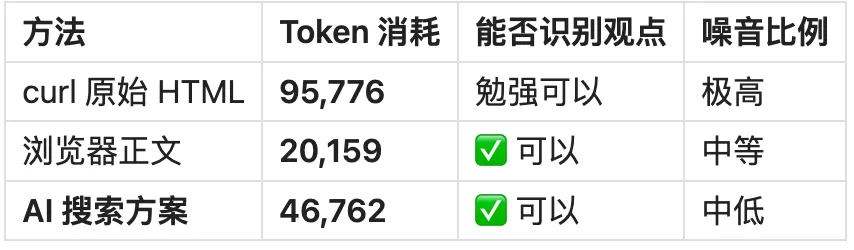
是的,在低风控、结构规整的页面上,浏览器正文确实可能更短。
但注意两点:
1. AI 搜索方案提供结构化输出
浏览器正文给你一大段文本,你还需要再让模型:
识别主贴和评论
提取主流观点
做情绪分类
AI 搜索方案的 JSON 输出可以直接给出结构化的评论摘要,省掉二次 prompt 成本。
2. 浏览器方式在高风控页面上会失效
Reddit 就是典型例子:浏览器只能看到验证页,根本拿不到内容。
AI 搜索方案的核心:为 Agent 优化的三个层次
层次 1:反爬机制
传统方案需要你自己解决:
住宅 IP 轮换
浏览器指纹伪装
JS 渲染 + 重试策略
人机验证绕过
AI 搜索方案内置了这些能力,成功率稳定在 90% 以上。
层次 2:内容提取
传统方案返回:整页 HTML 或整页文本
AI 搜索方案返回:
Markdown:保留语义结构,去除导航/广告/页脚
JSON:结构化数据,可直接做比较、监控、分析
Links:提取所有链接
Screenshot:视觉验证
这些格式都是 LLM 友好的,不需要二次转换。
层次 3:结构化提取
对于定价页、更新页、讨论页这种高频场景,AI 搜索方案可以:
自动识别价格表、套餐卡片
提取版本号、更新点、发布日期
归纳评论、情绪、主流观点
把“网页理解”这一步前移,Agent 直接拿到可消费的数据。
AI 搜索方案省的不只是 Token
第一层:省 Token(直接成本)
过滤掉 90%-99% 的 HTML 噪声
典型节省:新闻页 97%、定价页 99%
第二层:省清洗(工程成本)
Markdown/JSON 直接可用
不需要二次 prompt 做结构化
减少多轮对话的累积成本
第三层:省重试(失败成本)
内置反爬机制,成功率 90%+
避免“抓取失败 → 重试 → 再失败”的恶性循环
知乎 403、Reddit 验证页、Cloudflare 拦截 → 都能稳定处理
第四层:省推理(隐性成本)
模型不需要先当“网页解析器”
直接拿到结构化数据,推理效率更高
减少幻觉和错误提取的概率
算一笔账:能省多少钱?
场景:抓取 100 次 Notion 定价页
再算上省掉的失败重试、二次清洗、多轮对话成本,实际节省远不止这些。
如何在 OpenClaw 中接入 AI 搜索方案?
目前比较成熟的实现是 XCrawl,它专门为 AI Agent 场景设计。
接入步骤
1. 安装 XCrawl Skills
把下面的内容发给 OpenClaw(龙虾):
https://github.com/xcrawl-api/xcrawl-skills/blob/main/README.zh-CN.md
安装一下这个skills
2. 申请
xcrawl官网
API Key
前往 注册
注册即送 1000 次免费调用额度
3. 配置 API Key
创建本地配置文件:~/.xcrawl/config.json
{ "XCRAWL_API_KEY": "<your_api_key>" } </your_api_key>
你也可以直接让 AI 帮你做
就这么简单。
核心特点
内置住宅代理池 + 指纹伪装
支持 Markdown/JSON/Screenshot 等 LLM 友好格式
可自定义结构化提取 schema
按需付费,用多少算多少
总结:AI Agent 需要的不是“网页”,而是“数据”
传统的网页抓取方案是为人类设计的,它们假设你:
能看懂 HTML 结构
能忽略广告和导航
能手动提取关键信息
但 AI Agent 不是人类,它需要的是:
干净的、结构化的数据
可直接消费的格式
高成功率的抓取能力
这就是为什么你需要专门为 AI Agent 设计的搜索方案。
省 Token 的最好方式,不是换更便宜的模型,而是别让模型吃垃圾。
注:本文所有 Token 估算按 字符数 / 4 粗估,仅用于横向比较。测试时间:2026-03-23。
