 夜雨聆风
夜雨聆风🤔 你是否遇到过这样的尴尬?
第一天让AI助手记住你的项目架构,第三天再问,它一脸茫然;
上周刚配置的个性化设置,这周重启后全部归零;
翻遍对话记录,找不到当时讨论的那个关键结论...
不是AI不智能,是它真的记不住。
一、为什么AI助手总是"金鱼记忆"?
要理解这个问题,我们得先明白一个技术事实:大多数AI应用,包括那些看似强大的Agent系统,本质上都是"无状态"的。它们每次对话都是从零开始——就像一条金鱼,永远只有7秒钟的记忆。

图1:AI与人类记忆的类比 — 长期记忆才是真正的智能
这不是bug,而是大语言模型的核心特性:上下文窗口有限,每次交互只能看到当前对话的内容。历史信息随着对话结束就消失了。
二、OpenClaw的破局之道:双层记忆架构
OpenClaw没有选择简单地给AI加个"记事本",而是设计了一套精妙的双层记忆系统。这套系统的核心理念是:存储与检索分离。
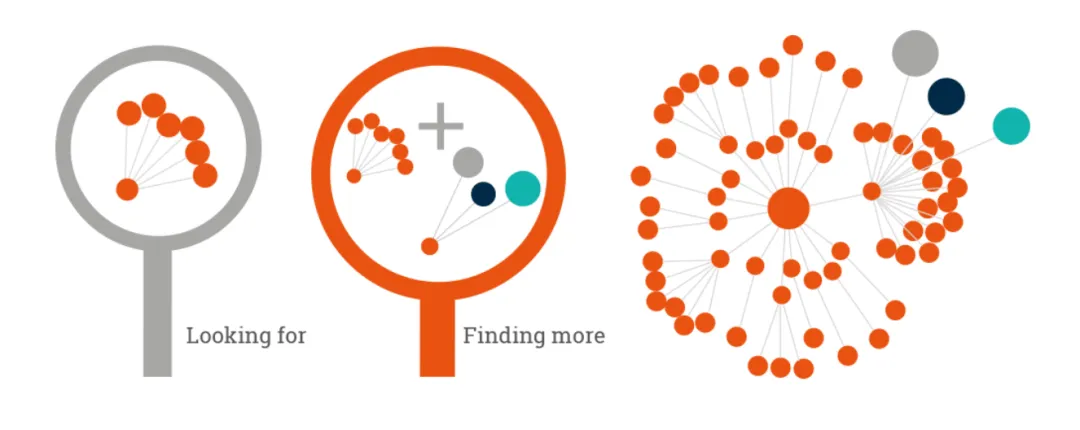
图2:存储与检索分离的架构设计

📋 第一层:Markdown 源数据层
这是最朴实、也是最可靠的一层。OpenClaw使用纯文本Markdown文件来存储记忆:
~/.openclaw/workspace/MEMORY.md | |
~/.openclaw/workspace/memory/YYYY-MM-DD.md |

🔎 第二层:SQLite 索引层
仅有存储还不够,关键是要能"找得到"。OpenClaw使用SQLite配合向量检索:
图3:Markdown的简洁与强大 — 既是存储格式,也是知识沉淀
这一层会做三件事:
- 1内容切分 — 把Markdown内容切成小块(chunk)
- 2向量化 — 调用embedding模型生成向量表示
- 3存储索引 — 保存向量与原始内容的对应关系
三、关键词搜索 vs 语义搜索
有了索引层之后,检索能力就有了质的飞跃。OpenClaw的Hybrid搜索模式结合了两种检索方式:

图4:语义搜索让AI真正理解你的意图
四、5分钟配置你的记忆系统

核心配置示例:
{"agents": {"defaults": {"model": {"primary": "openai-codex/gpt-5.4"},"memorySearch": {"provider": "openai", // 使用OpenAI协议"model": "nomic-embed-text", // 推荐模型"remote": {"baseUrl": "http://localhost:11434/v1","apiKey": "ollama"},"sync": {"watch": true}}}}}

五、新手必看:配置中的"坑"与解决方案

六、让记忆系统成为你的"第二大脑"

图5:好的记忆系统就是你的数字"第二大脑"
养成这些好习惯

渐进式使用策略
| 第一阶段 | ||
| 第二阶段 | ||
| 第三阶段 | ||
| 第四阶段 |

