 夜雨聆风
夜雨聆风Openclaw 是长时间任务型 Agent,对算力和数据库都提出新要求,就数据库而言,从“被查询” → “参与执行”
一、OpenClaw 改变了 Agent 的形态
• 传统 LLM: request → inference → response → 结束 • OpenClaw(Agent runtime): 输入 → 推理 → 调用工具 → 写入状态 → 等待 → 再推理 → …(循环) 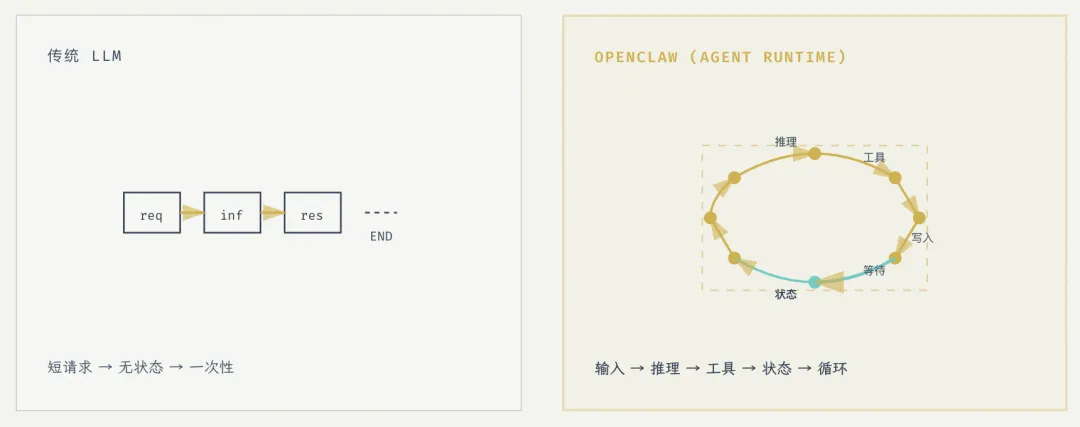
关键差异如下:
| 长生命周期(分钟~小时) | ||
| 持久 session | ||
| 持续读写 memory / DB | ||
| 循环(agent loop) |
OpenClaw 是一个持续运行的 agent runtime,而不是API调用。Agent长时运行,真正被持续消耗的是三类资源:
| 持续占用(session级) | ||
| 长连接(stateful) | ||
| 持续读写(memory loop) |
二、对数据库的要求,发生了哪三类结构性变化
2.1 数据模型:从“记录” → “状态”
传统数据库存的是:行数据、文档、embedding
Agent需要的是:
state = { short-term memory, long-term memory, tool context, intermediate results}关键变化:
| session state | ||
| 动态演化 | ||
| 频繁小步修改 |
数据库要支持“高频状态变更”,而不是“稳定数据存储”
2.2 访问模式:从“查询驱动” → “循环驱动”
• 传统:应用 → query DB → 返回 • Agent:agent loop ↔ DB(持续交互)
具体变化:
| 极高频(每步都读写) | ||
| 不可预测路径 | ||
| 碎片化 + 混合(vector + KV + log) |
数据库无法再依赖 query optimization,而要适配 execution loop
2.3 资源占用模型:从“瞬时使用” → “长期占用”
传统数据库:
• 请求结束 → 资源释放
Agent数据库变成:资源占用 -> session生命周期
• session存在 → 连接持续 • state存在 → cache持续 • loop存在 → I/O持续
三、挖掘数据的真正新要求
如果不拘泥“数据库”这个词,可以把需求抽象成:
3.1 Stateful Data Plane(有状态数据平面)
需要具备:
• session-aware(按agent隔离) • 状态版本管理(checkpoint / rollback) • 增量更新(而不是全量写入) 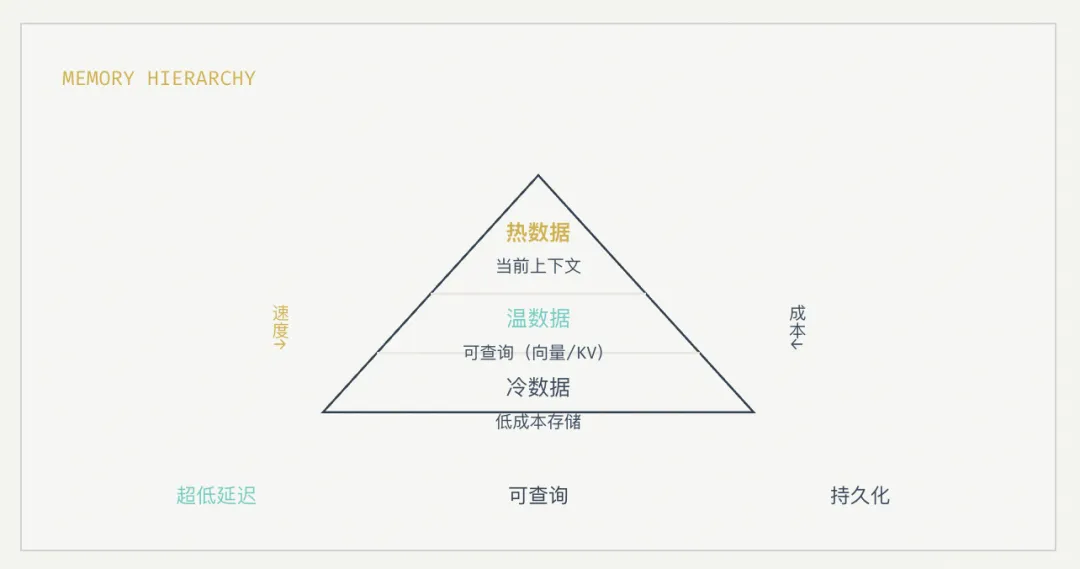
3.2 Memory分层能力
Agent memory天然分层:热数据(当前上下文) → 冷数据(历史) → 长期存储
数据库需要支持:
没有分层,I/O一定爆
3.3 流式写入 + 状态压缩
因为 agent每一步都在写,但大多数是冗余中间状态,所以需要:
• append log(像Kafka) • state compaction(类似LSM tree思想)
3.4 关键变化:与推理强耦合
• 传统:DB ≠ compute • 现在:DB 是 inference loop 的一部分
需要支持:
• 低延迟读写(直接影响token生成) • 与GPU调度协同(否则空转)
四、不再是“数据库问题”,而是“Agent Memory System问题”
• 数据库只是 Agent Memory System 其中一层 • 瓶颈从“查询性能”转移到“状态管理能力” ◦ 生命周期管理 ◦ 状态一致性 ◦ 内存/存储分层 • I/O压力只是结果,真正问题是“持续占用” 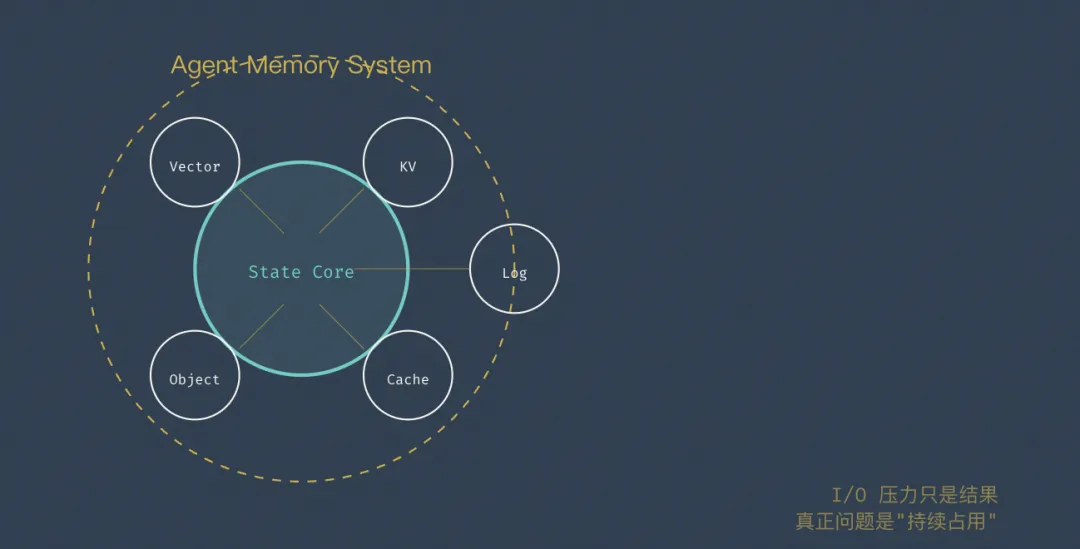
五、这件事的直接产业后果
Runtime 正在下沉到数据层,DB 正在上升为执行环境
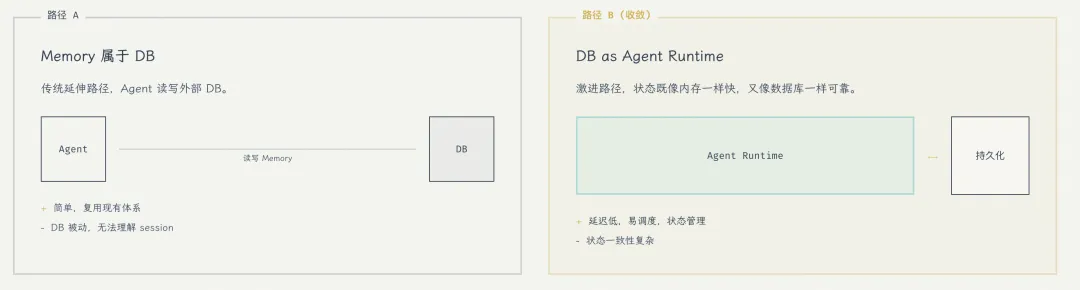
5.1 两种agent与数据的协同路径
路径A:Memory 属于 DB(传统延伸)
Agent → DB(读写memory)→ 推理
优点:
• 简单 • 复用现有数据库体系(Zilliz、Pinecone、Redis)
问题:
• DB是被动的(无法管理生命周期) • 无法理解“agent session” • 无法调度资源
路径B:Memory 属于 Runtime(激进路径)
Agent Runtime(内存/状态) -> 异步持久化(DB)
优点:
• 延迟低 • 更接近“进程模型” • 易做调度
问题:
• 状态一致性复杂 • 持久化困难 • 系统复杂度高
结论:“DB as Agent Runtime”是更合理的收敛,核心原因只有一个:Agent的状态既要“像内存一样快”,又要“像数据库一样可靠”,这两个约束不能拆开。
5.2 数据库核心能力重写,做到“DB as Runtime”
| session state + memory graph | ||
| step / transition / checkpoint | ||
| event / loop | ||
| session级 |
必须具备的能力如下,三点缺一不可,否则只是“更快的数据库”
5.2.1 状态机能力
• agent = state machine • DB = state container + transition engine
5.2.2 事件驱动
• memory update → trigger next step • 不再是“请求驱动”
5.2.3 checkpoint / replay
• agent可恢复 • 支持长任务
5.3 四、为什么不会是“纯Runtime替代DB”
从约束出发看:
• Agent任务越来越长 ◦ 小时级 / 天级 ◦ 必须持久化 • 状态必须可恢复 ◦ crash → resume ◦ 多节点迁移 • 多Agent共享 memory ◦ 协作 ◦ 权限 ◦ 一致性
这些都是数据库问题,不是runtime擅长的
5.4 为什么不会是“传统DB升级”
因为传统DB缺三样东西,必须引入 runtime 语义:
• session awareness,不知道“哪个agent在用数据” • execution context,不知道“这一步属于哪个loop” • 调度能力,无法决定哪个agent优先、暂停、kill
六、产业演进
6.1 DB侧(向上长)
• Zilliz为代表的向量数据库 retrieval → memory → agent context • Redis为代表的KV数据库 cache → session → state • HTAP数据库
• 统一了结构化数据 + 分析,很适合加强vector、state、log能力 • HTAP天然控制CRM等企业数据源,最终一致性必须落在HTAP这类系统上 • 发展阶段: ◦ 第一阶段(已发生):HTAP + Vector ◦ 第二阶段(进行中):HTAP → “HTAP + State” ◦ 第三阶段(高价值定位):HTAP → “HTAP Runtime” + “Trust Data Runtime”
6.2 Runtime侧(向下吃)
• OpenClaw / 类Agent runtime,开始管理 memory • 云厂商(AWS / GCP),把 memory + compute 打包
6.3 用数据库历史演化来说明
Agent正在把数据库从“存储系统”变成“执行系统”
现在 Agent 时代要出现的是:Stateful Stream + Storage + Execution 的统一体
1. Agent = 长生命周期状态机 2. Memory = 执行的一部分,而不是外部依赖 3. DB必须引入 runtime 语义,否则会被旁路
七、模型进步太快是核心挑战
以上分析成立,有几个前提:
• 前提1:memory仍然外部化,没有完全进入模型 • 前提2:agent需要可恢复,不是一次性任务 • 前提3:多agent共享状态,不是单用户孤立
如果未来发生这三件事:
• 超长context(10M+ tokens) • KV cache 持久化 • 单agent闭环
那路线可能会变成:
Model as RuntimeMemory inside model