 夜雨聆风
夜雨聆风
哈喽,我是cos大壮~
最近有好几位同学在实习面试以及正式社招中,被问到关于openclaw,以及相关大模型方面的问题。
其实在在近两年的面试中,一定避不开的是大模型,避不开对于Transformer相关的讨论~
Transformer可以说是现在所有大语言模型的基础骨架,没有它就没有我们现在用的这些大模型。
像GPT、LLaMA这类主流大语言模型,底层都是在Transformer的结构上做优化和升级来的。它里面的注意力机制特别关键,能让模型看懂上下文、理解长文本,这也是大语言模型能流畅对话的核心。
大语言模型其实就是把Transformer不断堆叠、放大,再用海量数据训练出来的产物。简单来说,Transformer是地基和框架,大语言模型就是在这个基础上建起来的完整应用。
今儿和大家详细的介绍一下Transformer,通过这篇文章,希望大家可以对Transformer有一个基本的认识。
01Transformer到底在干嘛?
如果把一句话里每个词(或一个序列里的每个位置)想象成开会的人,Transformer 就是个快速高效开会的机制:
每个人都能看见其他所有人,心里会给别人一个关注分,决定我现在最该听谁的。这就是自注意力(Self-Attention)。
不只一套关注标准,而是多套不同视角同时进行(有的关注相近词,有的关注远处词,有的关注动词,有的关注名词),这叫多头注意力(Multi-Head Attention)。
每一层开完会(聚合信息),再过一道小的全连接网络(FFN)做非线性变换,然后把结果加回原来的输入(残差连接),以免开会过头把原意忘了。层与层之间加LayerNorm稳住训练。
当年 RNN/ LSTM 是逐字逐词一个个说,不能并行,记长远关系很难;Transformer 一次就能让所有位置互相看见,天然并行,长程依赖抓得住。
所以大模型做的并不是玄学,底层就是把这个开会投票-多视角-非线性-稳住的结构堆很多层、做很大、用更多数据训更久,形成强大的语义理解与生成能力。
02关键模块
下面我们把重点部件讲得更工科一些,但仍尽量直白。
自注意力(Self-Attention)是加权抄作业:每个位置把其他位置的表示看一眼,做一个相似度打分,再用Softmax变为权重,最终把大家的表示按权重加权求和。
具体做法是把输入线性变成三个矩阵:查询、键、值。用去和做相似度,得到权重,再乘得到新的表示。
为什么要缩放?
如果和的维度是,相似度的数值会随变大而变大,导致Softmax太尖锐,不好训练。于是做一个缩放:。
多头注意力(Multi-Head)是多套关注标准并行:
把切成多个头,每个头用不同的投影矩阵,关注不同的模式,最后把这些头的结果拼接再线性融合。就像有的人擅长抓短程,有的人擅长抓长程,有的人看词性,有的人看位置。
前馈网络是每个位置各自做一个小型非线性变换:
注意力是交互,FFN是就地加工。它给每个位置一个更强的表达能力,常见是两层全连接+激活(GELU/ReLU)。
残差(Residual)+ LayerNorm 是稳住训练与梯度的工程做法:
每个子层(注意力或FFN)外面都有残差连接,让网络在加深时不容易退化;LayerNorm把分布稳定下来。
位置编码是告诉网络次序:
因为注意力默认只看内容不看位置,我们要显式把位置注入进去,常用正弦/余弦编码,或可学习的位置嵌入。
遮罩(Mask)能让模型看见或看不见某些位置:
比如语言生成时不让模型看未来(下三角mask),或把padding位置屏蔽掉不参与计算。
并行与复杂度:
全局注意力让每个位置都和其他位置交互,计算是,这就是长序列瓶颈;但好处是能完全并行,和RNN相比训练速度非常友好。
03核心公式
1. Scaled Dot-Product Attention(缩放点积注意力):
2. Multi-Head Attention(多头注意力):
其中:
3. 位置编码(常见的正弦/余弦):
4. 分类任务的交叉熵损失:
04一个完整小例子
我们做个玩具任务:给定一个整数序列(长度固定),要求模型预测这些数相加后对10取模的类别。
这样的任务需要关注所有位置,很适合演示注意力的用法。
数据:随机生成序列,标签=元素之和 mod 10。
模型:小型Transformer编码器(多头自注意力 + FFN),池化后接线性分类。
import mathimport randomimport numpy as npimport torchimport torch.nn as nnfrom torch.utils.data import Dataset, DataLoaderimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.decomposition import PCA# 保证可复现seed = 42random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)# 一些超参数vocab_size = 100# 词表大小(整数token范围)d_model = 64# 模型隐藏维度num_heads = 4# 多头注意力的头数num_layers = 2# Transformer层数ffn_dim = 128# 前馈网络维度seq_len = 16# 序列长度num_classes = 10# 类别数(和取模一致)dropout = 0.1batch_size = 64epochs = 8lr = 1e-3device = torch.device('cpu') # 演示用CPU即可# 1) 构造虚拟数据classSumModDataset(Dataset):def__init__(self, size, seq_len, vocab_size, num_classes): self.size = size self.seq_len = seq_len self.vocab_size = vocab_size self.num_classes = num_classes xs = np.random.randint(0, vocab_size, size=(size, seq_len), dtype=np.int64) ys = xs.sum(axis=1) % num_classes self.x = torch.tensor(xs, dtype=torch.long) self.y = torch.tensor(ys, dtype=torch.long)def__len__(self):return self.sizedef__getitem__(self, idx):return self.x[idx], self.y[idx]train_ds = SumModDataset(4096, seq_len, vocab_size, num_classes)val_ds = SumModDataset(512, seq_len, vocab_size, num_classes)train_loader = DataLoader(train_ds, batch_size=batch_size, shuffle=True)val_loader = DataLoader(val_ds, batch_size=batch_size, shuffle=False)# 2) 位置编码classPositionalEncoding(nn.Module):def__init__(self, d_model, max_len=512): super().__init__() pe = torch.zeros(max_len, d_model) # [max_len, d_model] pos = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) denom = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0)/d_model)) pe[:, 0::2] = torch.sin(pos * denom) pe[:, 1::2] = torch.cos(pos * denom) self.register_buffer('pe', pe.unsqueeze(0)) # [1, max_len, d_model]defforward(self, x):# x: [B, L, d_model] L = x.size(1)return x + self.pe[:, :L, :]# 3) 自定义Transformer编码层(返回注意力权重)classEncoderLayer(nn.Module):def__init__(self, d_model, num_heads, ffn_dim, dropout=0.1): super().__init__() self.mha = nn.MultiheadAttention(d_model, num_heads, dropout=dropout, batch_first=True) self.ffn = nn.Sequential( nn.Linear(d_model, ffn_dim), nn.GELU(), nn.Dropout(dropout), nn.Linear(ffn_dim, d_model), ) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.drop = nn.Dropout(dropout)defforward(self, x, attn_mask=None, need_weights=False):# x: [B, L, d_model]# MultiheadAttention默认输入为 [B, L, d_model] if batch_first=True residual = x attn_out, attn_weights = self.mha( x, x, x, attn_mask=attn_mask, need_weights=need_weights, average_attn_weights=False ) x = self.norm1(residual + self.drop(attn_out)) residual = x x = self.ffn(x) x = self.norm2(residual + self.drop(x))return x, attn_weights # attn_weights: [B, num_heads, L, L] if need_weights# 4) 小型TransformerclassTinyTransformer(nn.Module):def__init__(self, vocab_size, d_model, num_heads, num_layers, ffn_dim, num_classes, dropout=0.1, seq_len=16): super().__init__() self.emb = nn.Embedding(vocab_size, d_model) self.pos = PositionalEncoding(d_model, max_len=512) self.layers = nn.ModuleList([ EncoderLayer(d_model, num_heads, ffn_dim, dropout=dropout)for _ in range(num_layers)]) self.pool = nn.AdaptiveAvgPool1d(1) # 做全局平均池化 self.head = nn.Linear(d_model, num_classes) self.seq_len = seq_lendefforward(self, x, need_attn=False):# x: [B, L] x = self.emb(x) # [B, L, d_model] x = self.pos(x) attn_collect = []for i, layer in enumerate(self.layers): x, attn = layer(x, attn_mask=None, need_weights=need_attn)if need_attn: attn_collect.append(attn) # list of [B, H, L, L]# 池化: [B, L, d] -> [B, d] x = x.transpose(1, 2) # [B, d, L] x = self.pool(x).squeeze(-1) # [B, d] logits = self.head(x) # [B, num_classes]if need_attn:return logits, attn_collectreturn logitsmodel = TinyTransformer(vocab_size, d_model, num_heads, num_layers, ffn_dim, num_classes, dropout=dropout, seq_len=seq_len).to(device)criterion = nn.CrossEntropyLoss()optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-2)# 5) 训练/验证循环,收集可视化所需信息train_losses, val_losses = [], []# 存储注意力热力图(选取某个batch的一个样本)saved_attn = Nonesaved_tokens = None# 收集梯度范数分布(前若干步)grad_records = [] # list of dict: {'layer': str, 'step': int, 'norm': float}max_steps_for_grad = 120global_step = 0# 辅助:将参数映射到层名defparam_to_layer(name):if name.startswith('emb'):return'emb'if name.startswith('layers.0.mha'):return'layer0_attn'if name.startswith('layers.0.ffn'):return'layer0_ffn'if name.startswith('layers.1.mha'):return'layer1_attn'if name.startswith('layers.1.ffn'):return'layer1_ffn'if name.startswith('head'):return'head'return'others'defrecord_grad(step):for n, p in model.named_parameters():if p.grad isNone: continue layer = param_to_layer(n) norm = p.grad.data.norm().item() grad_records.append({'layer': layer, 'step': step, 'norm': norm})for epoch in range(1, epochs+1): model.train() epoch_losses = []for i, (xb, yb) in enumerate(train_loader): xb, yb = xb.to(device), yb.to(device) optimizer.zero_grad() logits = model(xb) loss = criterion(logits, yb) loss.backward()# 记录梯度流(前若干步)if global_step < max_steps_for_grad: record_grad(global_step) optimizer.step() epoch_losses.append(loss.item()) global_step += 1# 偶尔抓一个batch保存注意力与输入样本(只保存一次)if saved_attn isNone: model.eval()with torch.no_grad(): logits2, attn_list = model(xb[:1], need_attn=True) # 取一个样本 saved_attn = [a.cpu().numpy() for a in attn_list] # list of [B,H,L,L] saved_tokens = xb[:1].cpu().numpy() model.train() train_losses.append(np.mean(epoch_losses))# 验证 model.eval()with torch.no_grad(): val_epoch_losses = []for xb, yb in val_loader: xb, yb = xb.to(device), yb.to(device) logits = model(xb) loss = criterion(logits, yb) val_epoch_losses.append(loss.item()) val_losses.append(np.mean(val_epoch_losses)) print(f"Epoch {epoch:02d} | train_loss={train_losses[-1]:.4f}, val_loss={val_losses[-1]:.4f}")# 6) 提取embedding做PCA可视化emb_matrix = model.emb.weight.detach().cpu().numpy() # [vocab_size, d_model]pca = PCA(n_components=2, random_state=42)emb_2d = pca.fit_transform(emb_matrix) # [vocab_size, 2]# 7) 可视化# 图1:训练/验证损失曲线plt.figure(figsize=(8,5))plt.plot(train_losses, color='magenta', lw=2.5, marker='o', label='Train Loss')plt.plot(val_losses, color='cyan', lw=2.5, marker='s', label='Val Loss')plt.title('Loss Curves (Train vs Val)', fontsize=14)plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.grid(True, alpha=0.3)plt.tight_layout()plt.show()# 图2:多头注意力热力图(第一层的4个头)if saved_attn isnotNone: attn_l0 = saved_attn[0][0] # [H, L, L] 取第一层、batch=0# 取4个头分别画子图 cmaps = ['plasma', 'magma', 'viridis', 'inferno'] fig, axes = plt.subplots(1, num_heads, figsize=(4*num_heads, 4)) fig.suptitle('Attention Heatmaps (Layer 0, 4 Heads)', fontsize=16)for h in range(num_heads): ax = axes[h] im = ax.imshow(attn_l0[h], cmap=cmaps[h], vmin=0, vmax=1) ax.set_title(f'Head {h}', fontsize=12) ax.set_xlabel('Key Positions') ax.set_ylabel('Query Positions') plt.colorbar(im, ax=ax, fraction=0.046, pad=0.04) plt.tight_layout() plt.show()# 图3:Embedding PCA散点图plt.figure(figsize=(6,6))colors = plt.cm.hsv(np.linspace(0, 1, vocab_size))plt.scatter(emb_2d[:,0], emb_2d[:,1], c=colors, s=30, alpha=0.9, edgecolors='k', linewidths=0.3)plt.title('Token Embeddings (PCA to 2D) - HSV Colors', fontsize=14)plt.xlabel('PC1')plt.ylabel('PC2')plt.grid(True, alpha=0.2)# 标注少量token id以便理解(避免太乱)for tid in range(0, vocab_size, 10): plt.text(emb_2d[tid,0]+0.02, emb_2d[tid,1]+0.02, str(tid), fontsize=8, color='black')plt.tight_layout()plt.show()# 图4:梯度流分布(小提琴图)import pandas as pddf_grad = pd.DataFrame(grad_records)# 只保留出现频次较高的层,按层绘制小提琴分布layer_order = ['emb', 'layer0_attn', 'layer0_ffn', 'layer1_attn', 'layer1_ffn', 'head']df_grad['layer'] = pd.Categorical(df_grad['layer'], categories=layer_order, ordered=True)plt.figure(figsize=(10,4))sns.violinplot(data=df_grad, x='layer', y='norm', inner='quartile', palette='Set2', cut=0, scale='width')plt.title('Gradient Norm Distribution by Layer (Early Steps)', fontsize=14)plt.xlabel('Layer')plt.ylabel('Grad Norm')plt.tight_layout()plt.show()训练/验证损失曲线:
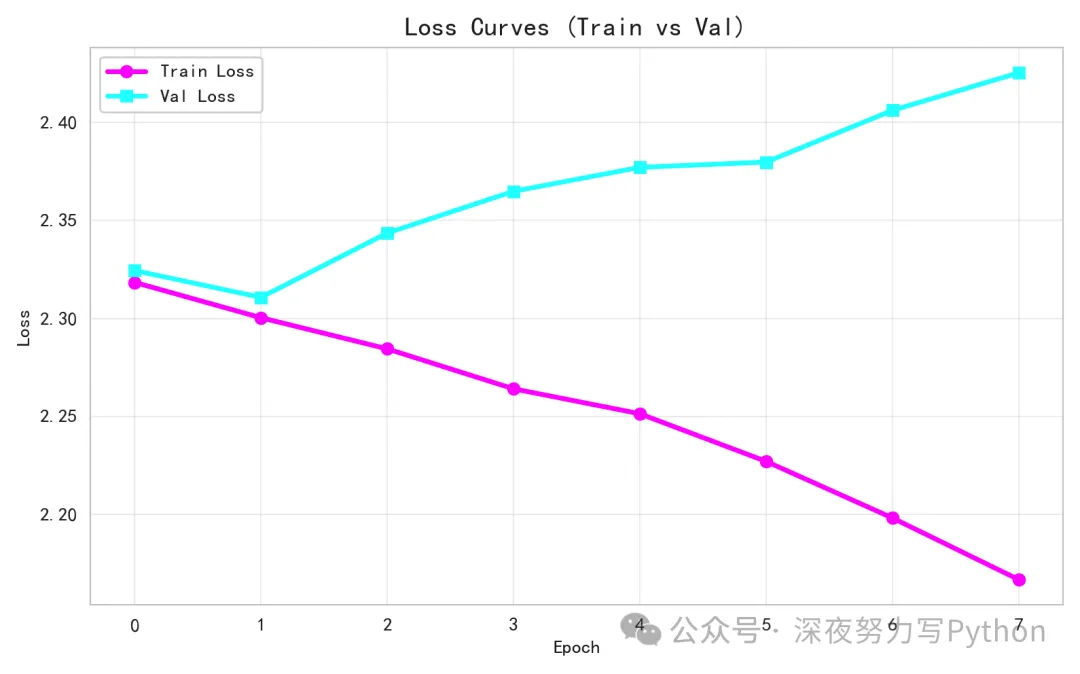
观察收敛趋势,判断是否过拟合或欠拟合。若训练损失下降而验证损失不降或上升,可能过拟合;若两者都降且相近,说明泛化不错。
在我们的玩具任务里,损失应会稳步下降,说明模型学会了把全局信息聚合起来。
注意力热力图:
每个头在一个样本上看到的Query→Key的关注分布。颜色越亮代表关注越强。
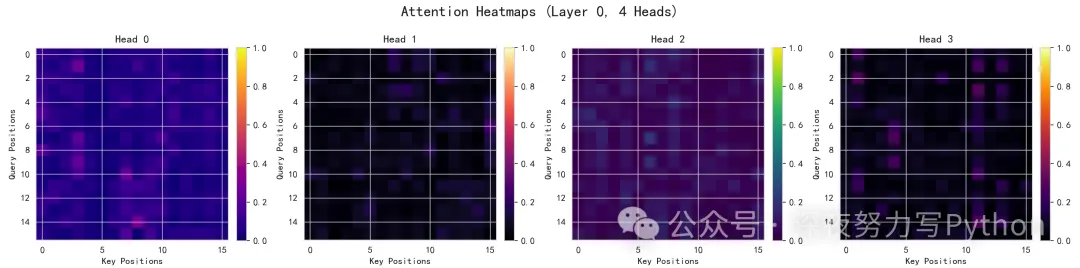
你会看到不同头的模式不完全相同:有些头可能更平均,有些头更偏向某些位置。这体现了多头=多视角。在求和mod的任务中,理论上每个位置都可能重要,因此有时会看到较为均匀的注意力;但训练初期或特定分布也可能让某些头强调局部模式。
Token Embedding的PCA散点图:
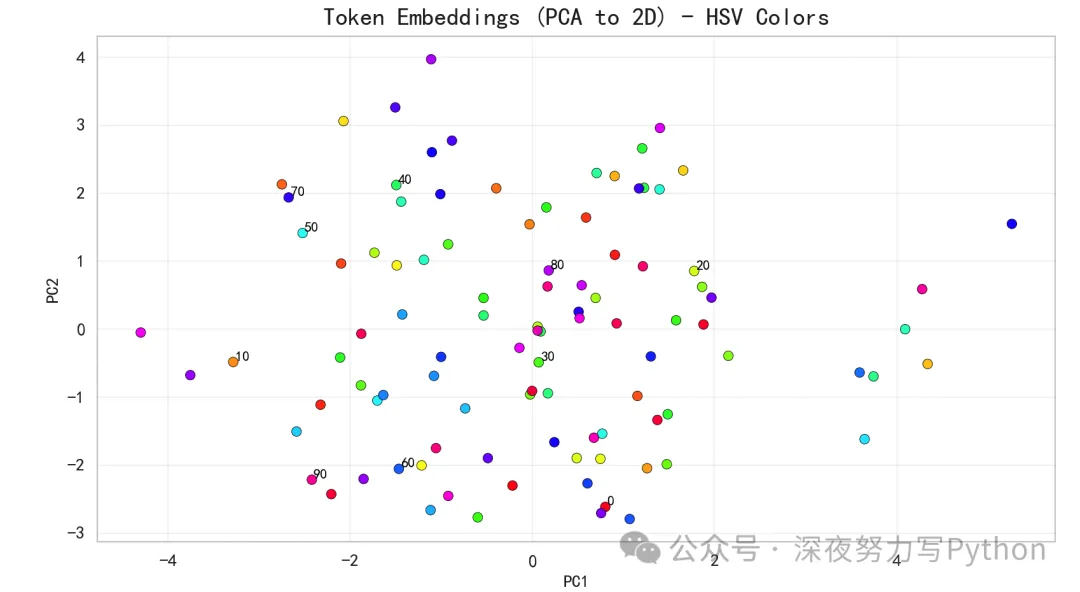
展示词向量空间的大致几何结构。虽然输入token是随机整数,但模型在训练中会把能帮助区分类别的token拉近或推远。
对sum mod 10而言,某些token对最终类别的贡献在模空间上有规律性,PCA也许会呈现出一些分组或环状结构(具体取决于训练程度与超参数)。鲜艳的HSV色盘有助于区分不同token的分布。
梯度范数分布:
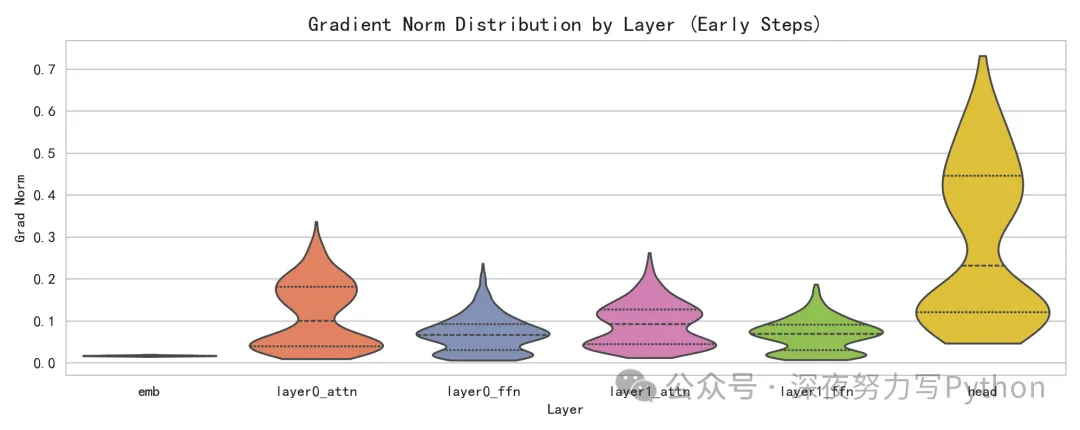
不同层参数在早期训练阶段的梯度强弱分布。梯度太小可能学不动,太大会不稳定。
如果你看到注意力层和FFN层的梯度分布不同,说明它们在学习过程中的活跃度不一样;Embedding层的梯度分布也可反映输入映射在多大程度上被更新。这为调参提供方向(如学习率、梯度裁剪、层别学习率等)。
总结
Transformer的核心直觉很朴素:让序列中每个位置都能看见并加权借鉴其他位置的信息,多头多视角,配以非线性变换与稳定训练的工程手段,再加上海量数据与合适的训练范式,就得到了今天的大模型。
基础的原理,大家慢慢熟悉,这个很重要。
