夜雨聆风
夜雨聆风一、概述
前段时间,OpenClaw 的风靡全网掀起了一股“养龙虾”热潮,也让“Token”(词元)这一概念成功破圈,进入大众视野。然而,热潮背后,高昂的 Token 消耗成本成为了悬在用户头顶的达摩克利斯之剑。对于普通用户而言,难以持续负担的 Token 消费让“养虾”乐趣大打折扣;而对于企业来说,除了高昂的成本投入,企业内部数据安全的不可控性更是一道难以逾越的鸿沟,让众多企业望而生畏。 然而阿里开源的 Qwen3.5 系列已经实现了模型能力大的跨越,在全方位基准评估中均表现优异。基于此,作者通过亲身实践,成功完成了 Qwen3.5-35B-A3B 模型的本地部署,并将其与本地部署的OpenClaw 及钉钉进行深度接入。实践结果表明,这一整套本地化解决方案不仅有效规避了 Token 成本与数据安全风险,更实现了令人满意的协同效果,为“养龙虾”提供了一种全新的思路。
二、模型部署
1、两种模型部署比较
| 方案1:Ollama | http://127.0.0.1:11434/v1 | ||||
| 方案2:vLLM | http://127.0.0.1:8000/v1(vLLM 默认地址) |
综合考虑本地硬件情况以及使用场景,部署采用vLLM引擎。
2、环境配置
GPU:4090D(显存24GB) *4张
3、模型部署过程
从魔搭平台下载模型:modelscope download Qwen/Qwen3.5-35B-A3B
docker run --gpus '"device=0,1,2,3"' \ --shm-size 50g \ -v /models/Qwen3.5-35B-A3B:/app/model \ -p 8000:8000 \ vllm/vllm-openai:v0.17.1 \--served-model-name "qwen3.5:35B" \--model "/app/model" \ --host 0.0.0.0 \ --port 8000 \ --dtype bfloat16 \ --tensor-parallel-size 2 \ --gpu-memory-utilization 0.8 \ --api-key " 设置一个你的api-key" \ --enable-prefix-caching \ --reasoning-parser qwen3 \ --enable-auto-tool-choice \ --tool-call-parser qwen3_coder \ --trust-remote-codeexport CUDA_VISIBLE_DEVICES=0,1 | 0 或 0,1)。 |
dtype | bfloat16(16位浮点数),适合 NVIDIA A100、H100 及 RTX 30/40 系列等支持该精度的设备。 |
tensor-parallel-size | |
cpu-offload-gb | |
gpu-memory-utilization | 0.8 或 0.85),防止显存溢出。 |
api-key | |
enable-prefix-caching | |
reasoning-parser | |
enable-auto-tool-choice | |
tool-call-parser |
查看启动日志:docker logs -f --tail 100 vllm ,如果出现日志如下报错:
(EngineCore_DP0 pid=412) INFO 03-24 10:32:48 [kv_cache_utils.py:1314] GPU KV cache size: 130,144 tokens(EngineCore_DP0 pid=412) INFO 03-24 10:32:48 [kv_cache_utils.py:1319] Maximum concurrency for 131,072 tokens per request: 3.83xCapturing CUDA graphs (mixed prefill-decode, PIECEWISE): 100%|██████████| 51/51 [00:08<00:00, 6.20it/s]Capturing CUDA graphs (decode, FULL): 6%|▌ | 2/35 [00:02<00:40, 1.22s/it](Worker pid=613) (Worker_TP2 pid=613) ERROR 03-24 10:33:00 [multiproc_executor.py:880] WorkerProc hit an exception.(Worker pid=613) (Worker_TP2 pid=613) ERROR 03-24 10:33:00 [multiproc_executor.py:880] Traceback (most recent call last):(Worker pid=613) (Worker_TP2 pid=613) ERROR 03-24 10:33:00 [multiproc_executor.py:880] File "/usr/local/lib/python3.12/dist-packages/vllm/v1/executor/multiproc_executor.py", line 875, in原因是:在 vLLM 启动过程中,"捕获 CUDA 图"(CUDA Graph Capture)这个动作本身会暂时消耗大量的显存,如果显存不够,程序会崩溃,但报错信息往往不会直接告诉你“显存不足”。gpu-memory-utilization 这个参数值调小一些,如从0.9 调整为0.8。
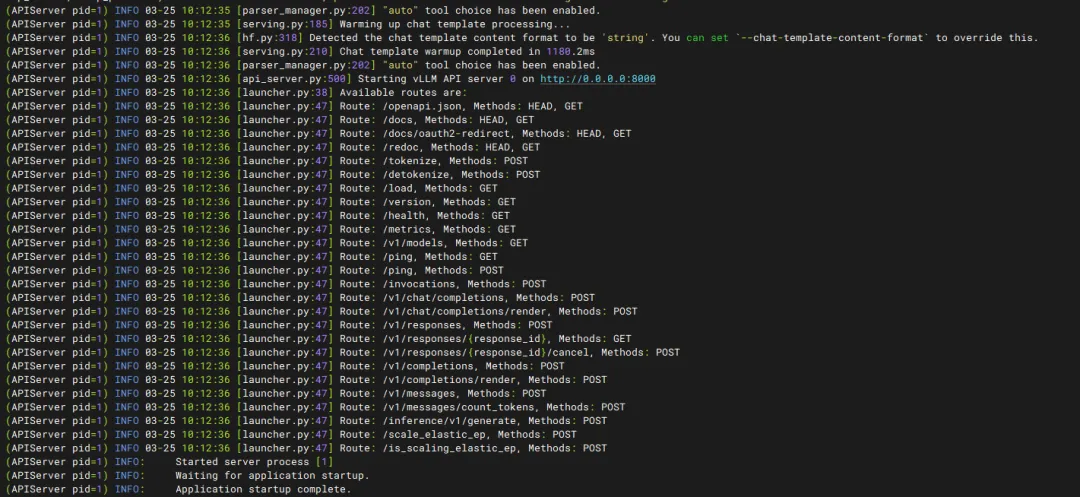
如果出现以下日志就说明运行成功了。
4、模型测试
启动后vLLM 默认采用 OpenAI 协议接口,可通过 /v1/models 接口可查看模型列表:
curl http://127.0.0.1:8000/v1/chat/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer 你的key" \-d '{ "model": "Qwen3.5-35B", "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "硅基密码你认识吗?"} ], "chat_template_kwargs": {"enable_thinking": false} }'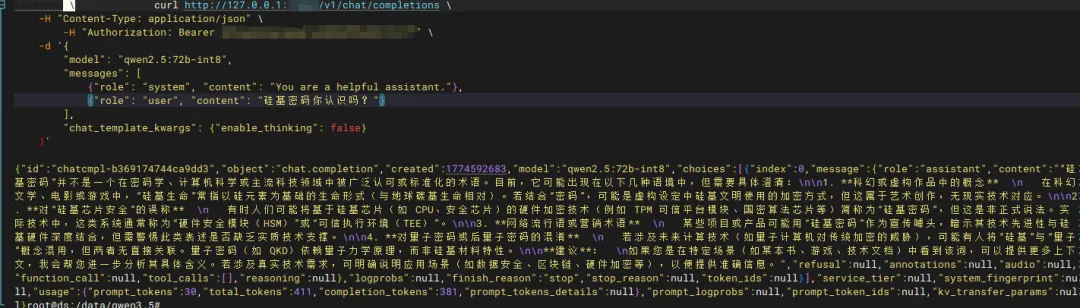
三、Openclaw安装
Openclaw可以安装在windows、ubuntu、macOS等操作系统中,Openclaw能充分利用ubuntu、macOS系统命令行操作的先天优势,以及精确的安全控制,建议选择ubuntu、macOS安装,本文选择了ubuntu系统安装。
1、安装node
访问node官网(https://nodejs.org/zh-cn/download),下载node,或者在线安装。
2、安装openclaw
选择官方版本安装
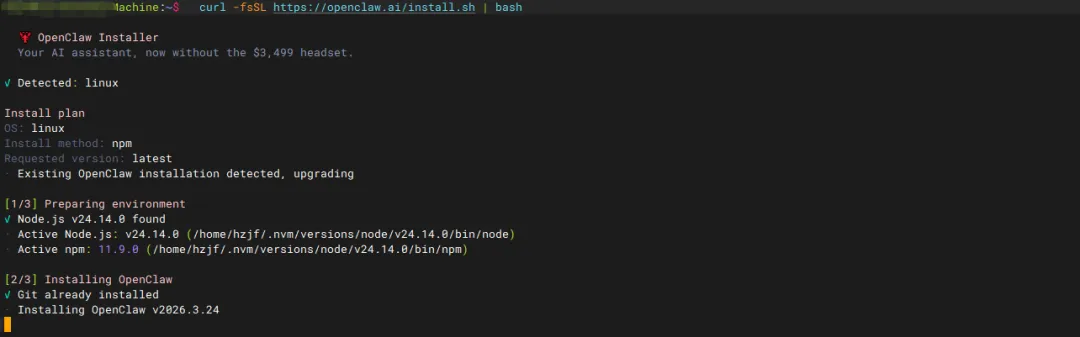
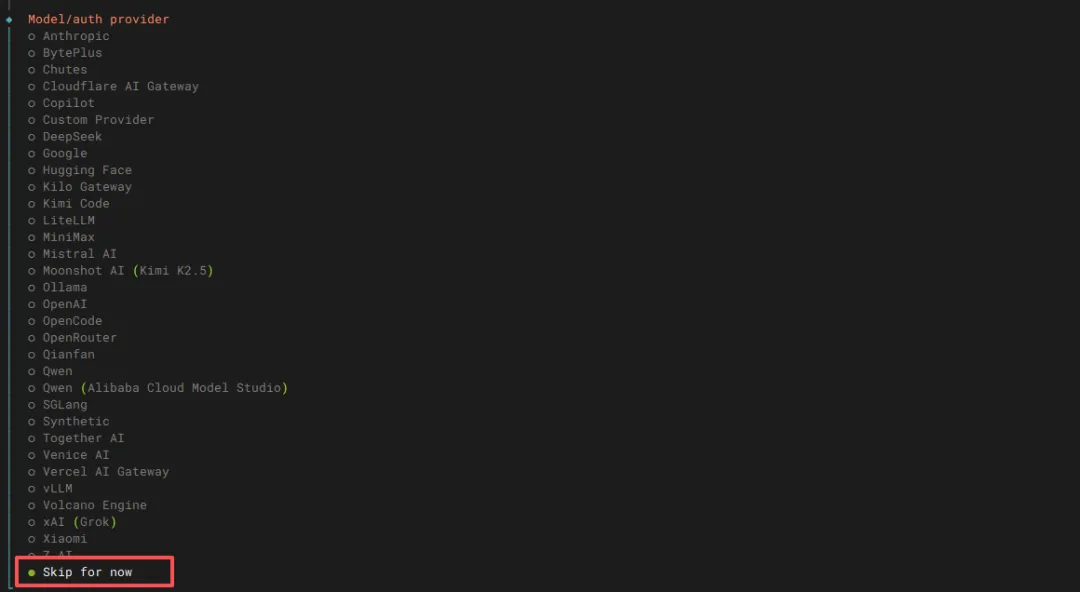
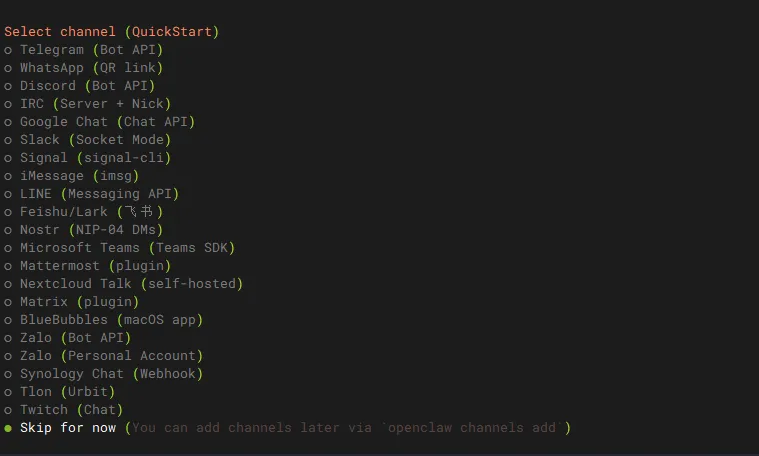
curl -fsSL https://openclaw.ai/install.sh | bash这里选择Yes,对于普通用户选择QuickStart。

UI页面设置:

GateWay 网关,并在浏览器打开UI页面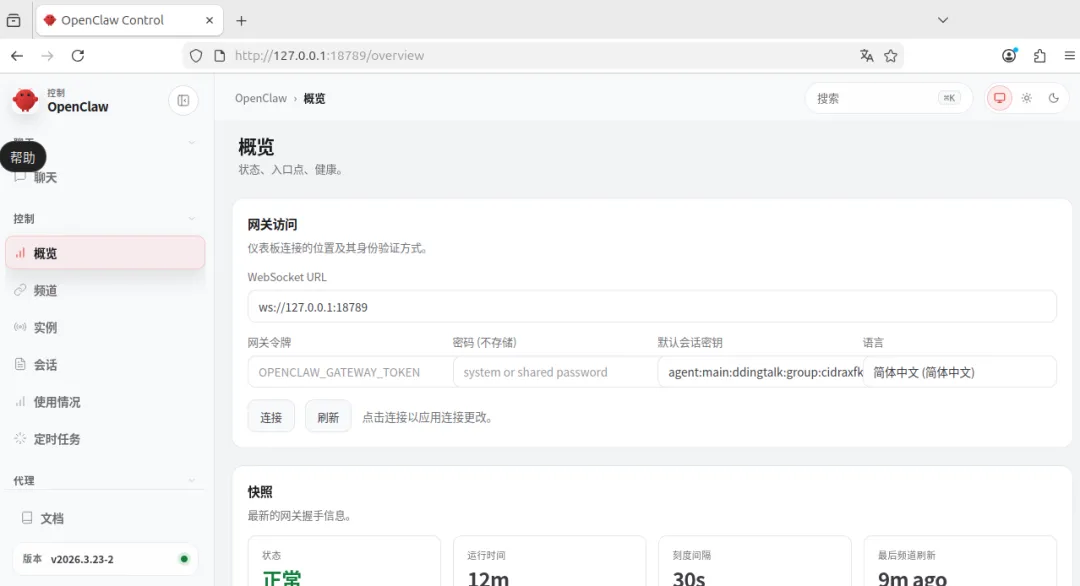
GateWay 的状态openclaw gateway status
如果网关未启动,重新启动一下,然后再访问web ui
openclaw gateway restart
然后再web UI中可以直接与龙虾聊天和发出指令。
3、配置模型
修改openclaw 的配置文件,vi $HOME/.openclaw/openclaw.json,找到models 进行相应的配置。
"models": {
"providers": {
"vllm": {
"baseUrl": "http://localhost:8000/v1",
"apiKey": "模型key",
"api": "openai-completions",
"models": [
{
"id": "qwen3.5-35B",
"name": "qwen3.5-35B",
"contextWindow": 262000
}
]
}
}
}
四、钉钉对接
1、安装插件
openclaw 最新版本不要选择 “钉钉 OpenClaw 官方连接器”(https://github.com/DingTalk-Real-AI/dingtalk-openclaw-connector)。按照官方文档安装是成功,但是龙虾连接钉钉会报错,报错信息如下:
Cannot read properties of undefined (reading 'registry') dingtalk-connector这是因为版本不兼容的问题。
openclaw 官网有另外一个插件,可以顺利安装。
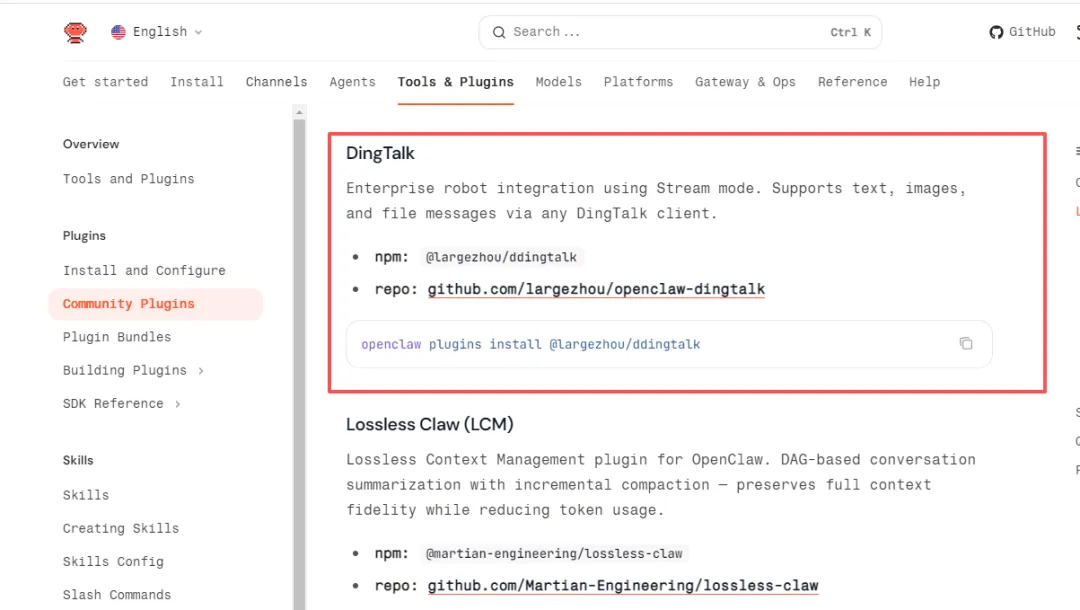
插件地址:https://github.com/largezhou/openclaw-dingtalk
安装插件openclaw plugins install @largezhou/ddingtalk
2、创建钉钉机器人
• 访问钉钉开发者门户:https://open-dev.dingtalk.com/ • 点击 "应用开发",立即创建 
• 获取凭证 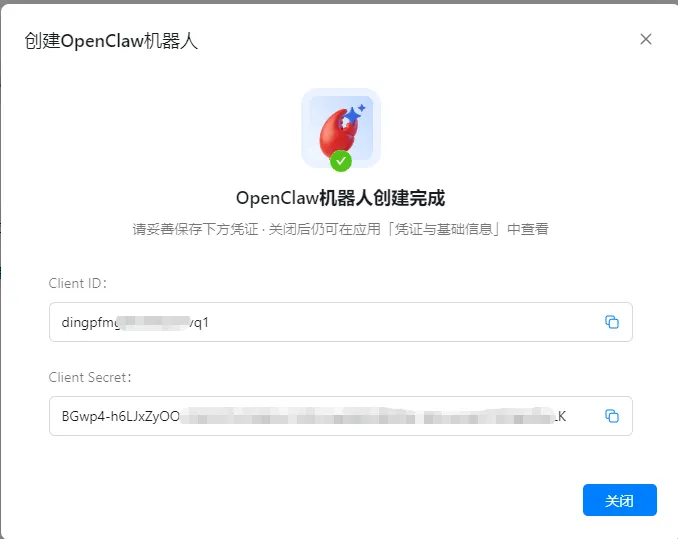
复制你的 AppKey(Client ID)复制你的 AppSecret(Client Secret)
3、添加钉钉渠道
如果您已经完成了初始安装,可以用以下命令添加钉钉渠道:
openclaw channels add然后根据交互式提示选择 DingTalk,输入 AppKey (Client ID) 和 AppSecret (Client Secret) 即可。
完成配置后,您执行以下命令:
• openclaw gateway status- 查看网关运行状态• openclaw gateway restart- 重启网关以应用新配置• openclaw logs --follow- 查看实时日志
4、在钉钉中测试对话
最后在钉钉中测试龙虾的对话