 夜雨聆风
夜雨聆风一.核心概念
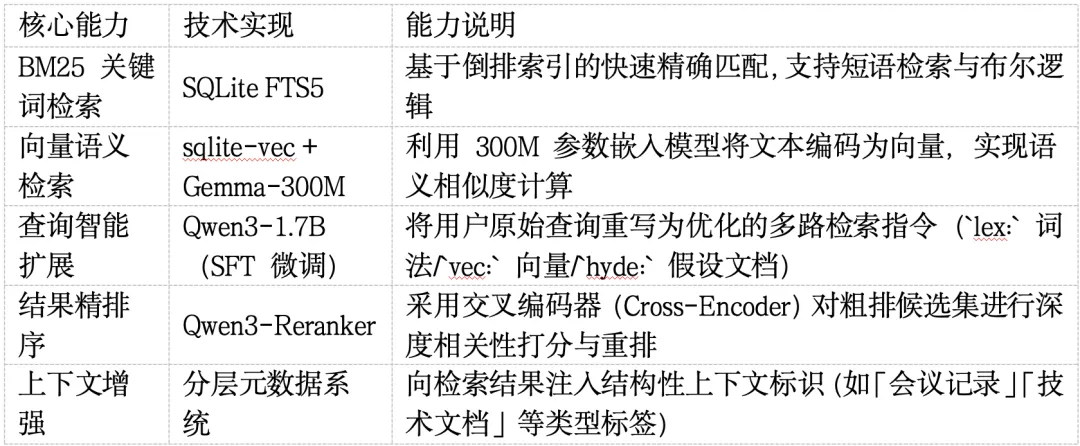
QMD(Query Markup Documents,查询标记文档)是一款端侧混合搜索引擎,专门针对 Markdown 文档、会议记录和个人知识库 进行优化。它将传统关键词搜索、现代语义向量搜索以及基于大语言模型(LLM)的重排序相结合,为智能体工作流(Agentic Workflows)和人类用户提供高精度检索能力。
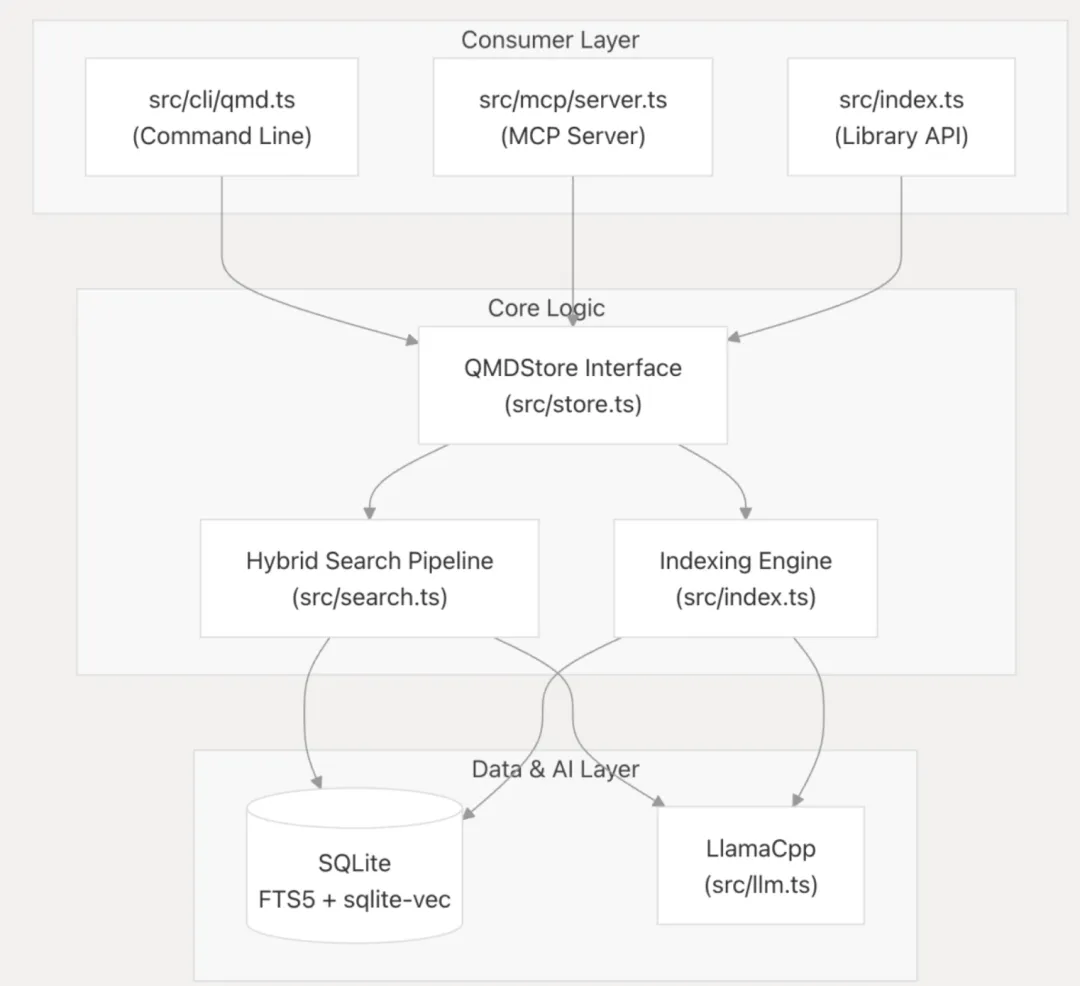
QMD 采用本地优先(Local-First)架构,利用 node-llama-cpp 直接在用户硬件上运行 GGUF 格式模型,完成文本嵌入(Embeddings)、查询扩展和重排序等任务,无需依赖云端服务。
QMD 设计灵活,支持三种主要接口:
CLI:一款功能全面的命令行工具,用于文档索引、搜索和集合管理。
SDK:提供稳定的库 API(QMDStore),可集成到 Node.js 或 Bun 应用程序中。
MCP 服务器:基于模型上下文协议(Model Context Protocol)的实现,允许 AI 智能体(如 Claude Desktop 或 Claude Code)将 QMD 作为工具调用。(Openclaw就是按照这样的方式调用的)
二.系统架构
核心特性
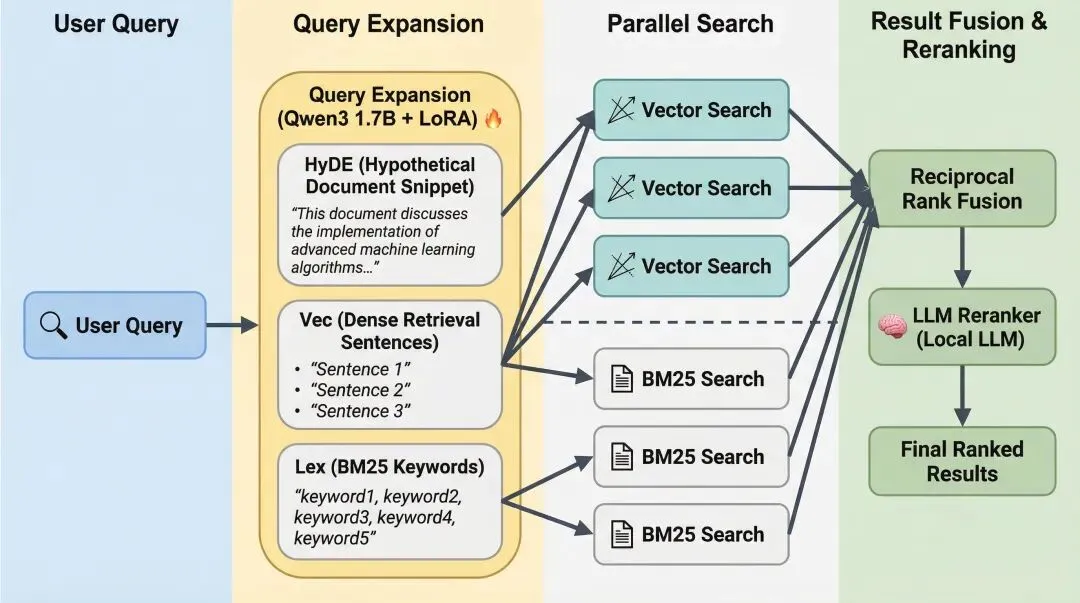
1. 混合搜索管道(RRF + 重排序)QMD 不依赖单一搜索策略。它同时执行多路子查询(词法检索、向量检索和 HyDE 检索),并使用倒数排序融合(RRF)算法对结果进行融合。随后,高排名结果会被送入重排序模型,该模型执行计算成本较高但精度极高的查询与文档正文深度比对。
2. 智能分块为处理长 Markdown 文件,QMD 采用基于标题感知的分块算法。该算法以每块约 900 个词元为目标,保留 15% 的重叠区域,同时智能地在 Markdown 标题、代码块或段落边界处切分,确保语义单元的完整性。
3. 分层上下文用户可为路径附加上下文(例如:qmd context add qmd://meetings "2024 年会议记录")。该上下文会被所有子文档继承,并在搜索时提供给大语言模型,显著提升智能体理解文档"出处"和"背景"的能力。
4. 意图消歧通过意图参数,调用方可提供额外的领域上下文(例如:针对查询"性能"提供"API 限流"作为意图)。该意图会引导整个处理管道——从查询扩展到重排序,乃至片段提取——而意图本身并不作为搜索词参与检索。
三.数据流
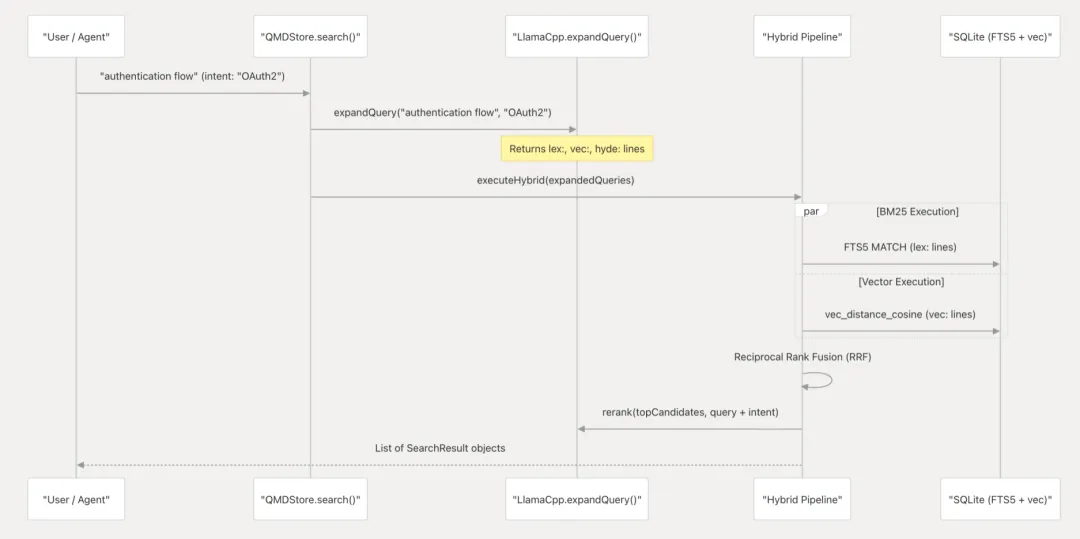
1)查询输入:用户(或Agent)提交自然语言查询 "authentication flow"(认证流程),并附带 意图参数 "OAuth2" 用于消除歧义(表明要找的是 OAuth2 协议的认证,而非其他认证方式)。
2)查询扩展(Query Expansion):QMDStore.search() 首先调用 LlamaCpp.expandQuery(),将原始查询和意图传入本地 LLM。返回三种优化的检索语句:
lex: —— 词法检索关键词(用于 BM25)、vec: —— 向量检索语义表达(用于嵌入相似度)、hyde: —— 假设性文档(HyDE,用于生成理想答案的向量表示)
3)混合并行检索(Hybrid Search):executeHybrid(expandedQueries) 触发 并行 双路检索:[BM25 执行]→ 使用 SQLite FTS5 执行 FTS5 MATCH,基于 lex: 行进行精确关键词匹配
[向量执行]→ 使用 sqlite-vec 扩展计算 vec_distance_cosine,基于 vec: 行进行语义相似度匹配
4)结果融合(RRF):两路检索的结果通过 RRF(Reciprocal Rank Fusion,倒数排序融合) 算法合并:BM25 返回的 Top-K 给予排名分数,向量检索返回的 Top-K 给予排名分数,按融合公式计算最终综合得分,避免单一检索方式的偏见。
5)精排(Reranking):融合后的顶部候选集(topCandidates)连同原始 query + intent 一起送入重排序模型(Qwen3-Reranker/Cross-Encoder):进行深度语义比对(计算成本高但精度高),意图参数在此再次发挥作用,确保重排序时理解领域上下文(OAuth2)。
结果返回:最终返回SearchResult 对象列表 给用户/Agent,包含文档片段、相关性分数、来源元数据等。
四.与OpenClaw的结合
OpenClaw 默认使用 Builtin(SQLite + FTS5 + 向量搜索),但它有几个明显的不足:1)语义理解弱,FTS5 只认识关键词,不知道"配置"≈"settings" 2)同义词处理差,搜索"电脑"找不到"PC"、"计算机" 3)无法理解上下文,搜索"它"不知道指的是什么4)向量搜索依赖外部 API,要么用 OpenAI API(花钱),要么用 Ollama(需额外安装)
QMD 是一个运行在本地的搜索服务,OpenClaw 在需要搜索 memory 时会 fork 一个 QMD 子进程来执行搜索命令,然后解析返回的 JSON 结果。 整个过程对用户透明,用户只需要在配置文件中指定使用 QMD 后端,其余工作都由 OpenClaw 自动完成。当 OpenClaw 启动时,如果检测到配置文件中的 memory.backend = "qmd",会触发以下自动行为:
首先,OpenClaw 会检查系统 PATH 中是否存在 qmd 命令。如果命令不存在,OpenClaw 会提示用户安装 QMD。如果命令存在,则继续执行后续步骤。
接下来,OpenClaw 会在用户数据目录下创建 QMD 的工作目录,路径为 ~/.openclaw/agents/<agent-id>/qmd/。这个目录用于存放 QMD 的配置文件、缓存数据和 SQLite 数据库。
然后,OpenClaw 会根据配置初始化 QMD 集合。它会自动添加默认的 memory 文件路径(如 MEMORY.md 和 memory 目录下的文件),以及用户配置的自定义索引路径。
最后,OpenClaw 会启动多个后台任务:开机时执行同步任务(运行 qmd update 和 qmd embed 更新索引和向量);按配置的间隔时间(默认 5 分钟)执行定时更新;以及监听文件变化,在 memory 文件发生变更时自动更新索引。
注意:OpenClaw内置的Builtin和QMD是二选一的关系,根据memory.backend配置来选择,如果配置QMD,且返回失败,则降级到Builtin,两者互斥,选一个作为主搜索后端,和大模型选择类似
如何配置:
https://docs.openclaw.ai/reference/memory-config
