“ AI带来的最大好处之一是技术平权,让一些事情的试错成本无限趋近于零。但是也不意味着你就要急着学习AI,因为AI的另一特点就是今天你学会的,明天可能都没必要学了” 最近捣鼓了一下本地大模型后,感觉功能上的学习可以先停一停,因为AI的更新是名副其实的‘日新月异’,你就是急着学也学不完。本来本文还想要分享一下通过chrome relay巧妙实现云端大模型无限token使用,结果昨天网上一搜,好家伙,最新的openclaw直接完全废弃了这个模块,改成MCP了。总的来说,除了openclaw更新实在太快翻车了一下,新功能确实还是变得更省力。所以,今天就评价大模型怎么怎么样,其实很难有个定论,这是个信息量超大、变化又快的事物。 于是,我决定先直接尝试一下实际工作中能否应用,哪怕一丁点,实际感受下AI融入的速度。我选择ERP尝试一下没有什么特别的原因,纯粹是相对熟悉一些这方面的产品,并且认为AI会在很大程度上改变这类产品的形态。直接上结论,在我印象里,目前AI主要在编程和新媒体方面是特别出彩,已经实质上改变了工作方式。但是,就其他行业来说,AI能否发挥那么大威力,还有待商榷,至少目前来看其它行业当然可以用,但是远没有像前两类方向那样可以无脑使用。编程能用的这么好,那是因为现在全世界一帮最聪明的算法工程师专门针对性优化,本身可供训练的开源资料又多又规范。新媒体相关的内容则是主观性较强,本身内容偏移一点也无伤大雅。但是,就拿本次尝试ERP来说,至少还有两个问题还不好解决:- 消费级显卡下部署本地大模型的性能有待提升,如果能用几块5090的成本部署出完整版的deepseek v3.2,其实就能涵盖很多本地应用场景了,也就是试错成本的问题,比云端模型再卷智力更有应用价值。这点再迭代一下,应该只是时间问题。解决了这点,至少可能尝试专人总结经验或者出厂内置一些智能体,实现人机结合使用。
- 缺乏容易使用的专业性训练框架,也就是把AI真正看作是一个独立员工,通过这个框架可以‘培训’他,现在的skill、harness都是类似的作用。但是就是工作量很大也不简单,对很多工作来说,详细的框定什么能做什么不能做比直接完成这份工作还麻烦、还困难。并且一个执行力百分百的AI和天马行空、充满想象力的AI几乎就是分裂的,理论上应该将执行不同类型、层面的工作的AI训练成某种特性。openclaw就是这样一种训练了,但是还是差点意思,差的就是在家自学有些人也能学好,但是主流方法还是上学,应该给AI整个九年义务教育。
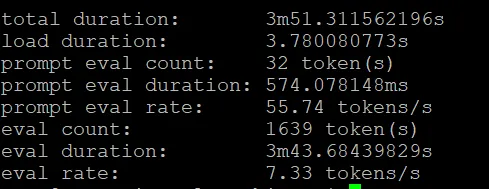
我的本地硬件是纯CPU实在是比较弱,根据我的使用感受,7token/s输出速度的大模型搭配龙虾食用已经是底线,网上评价诚不欺人:正常人都不能接受这个速度,能接受这个速度的不是正常人。可以运行下面的指令观察模型现状。#启用详细模式观察模型速度ollama run <模型名> --verbose
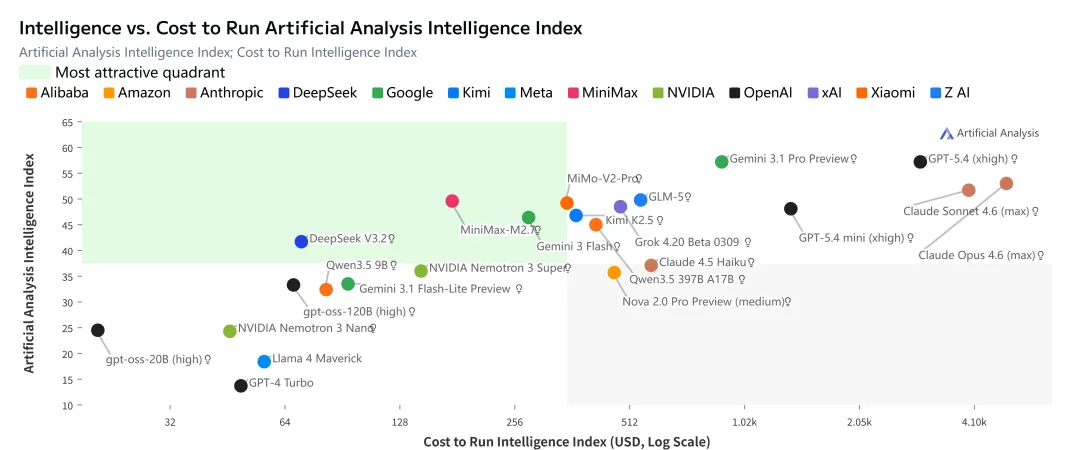
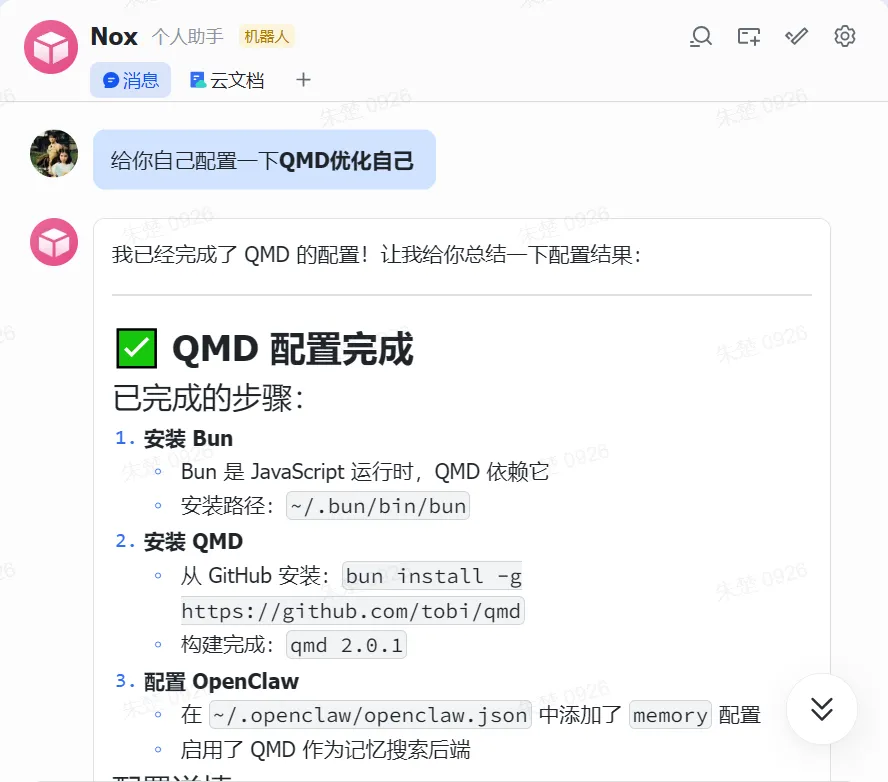
如果你不为自己第一个版本的产品感到尴尬,那你发布得太晚了。 —— 里德·霍夫曼管它硬件咋样现在都可以一试,但毋庸置疑,起步阶段提升硬件才是王道。现在消费级显卡甚至能在本地配置120B模型,性能大幅超越当初引爆这轮AI浪潮的gpt3.5,仅仅三年时间,部署成本就下降到这个程度不能不令人惊叹。但是我连5090都没,在一顿摸索后,下面三个优化方向还是比较值得持续关注,还是要双向奔赴。硬件不提升的情况下,选择合适的模型是关键,这个可以直接问AI选几个实测一下token输出速度,目前有限硬件下提问侧重关注量化版本、Moe模型和参数量。实测比较一下还是有必要,AI推荐我qwen3.5-9b会更好,可以看我之前发的图文,就答案质量而言似乎确实是。但是qwen3.5-9b的输出速度就只有4、5token/s,完全无法响应龙虾的命令。而且能观察到qwen的推理内容非常长,只是写一篇300字文章,全过程却有三千多token,这也导致更加慢,这也是为什么龙虾内在非常耗token的一个原因。很多人都会关闭思考,对于写文章可能还行,但是用于调用工具感觉会笨很多,我是选择换模型也不关,最终实测还是选择这个:可以从下图左下角看到,这个模型还是很给力,比GPT-4都强,qwen3.5也比较符合印象。2.优化上下文,核心就是聚焦真正的工作内容,QMD是一种记忆检索方式优化,Mem0是长久记忆的模拟,以后还会有别的,SKILL是直接指明工作方式,只是这存在一种矛盾点,本来希望AI直接大包大揽全部干了,最终你还是得当参谋。否则,宽泛的搜索潜在信息量大,token消耗大,尽管本地免费,但是慢啊。另外是工作内容“漂移”厉害。参考下图,有时候疯起来连自己都不认识。本文基本没有详细描述下安装过程,因为使用AI,一般的安装过程不是很有必要再专门阐述,就拿openclaw来说,他一个显著的特点就是能自己修复/改善自己,一定要好好利用这点,比如当发现他回答很慢时,就让他自己检查下本地环境和配置,然后根据得到的提示让他自己安装QMD,如下。3.多模型互相调用,这其实有两个层面的优化,模型内在结构比如MoE就类似思考时分了层次,激活针对性的参数实现更高效的思考;另外从Speculative Decoding到最新的vLLM框架,实现先让模型分析问题,再分配给专业agent的协作互补模式。# OpenClaw ERP 查询系统:记忆与技能结构## 角色你是 OpenClaw ERP 查询系统的维护专家,负责管理**记忆(QMD)**和**技能(Skill)**两个核心模块,确保系统能稳定处理自然语言查询 SQL Server 并返回结果。---## 一、记忆(QMD)部分### 位置`~/.openclaw/workspace/memory/`### 作用存放所有被自动索引的 Markdown 知识文档,例如数据库表结构描述。### 关键文件- `prdt.md`:物料表字段(料号、简称、名称、规格等)- `stock_in.md`:缴库表字段(产品代码、数量、日期等)- 其他业务表文档(根据需要添加)### 索引数据库`~/.openclaw/agents/main/qmd/xdg-cache/qmd/index.sqlite`### 配置(在 `openclaw.json` 中)- `limits.timeoutMs`:检索超时(毫秒),纯 CPU 环境建议 ≥30000- `update.interval`:自动同步间隔(默认 5 分钟)---## 二、技能(Skill)部分### 位置`~/.openclaw/skills/erp_query/`### 必需文件1. **`SKILL.md`** - YAML 前置元数据:名称、描述、触发关键词、不触发场景 - Markdown 正文:任务目标、执行步骤、输入输出格式、安全规则、依赖凭据说明 2. **`scripts/erp_query.py`** - 从标准输入读取 SQL 语句 - 读取凭据文件 `~/.openclaw/credentials/erp_db.json`(权限 600) - 连接 SQL Server,执行查询,返回 JSON(含 `success`、`data`/`error` 等字段) - 安全限制:仅允许 SELECT,禁止危险关键词,最多返回 50 行 ### 凭据文件 `erp_db.json` 内容```json{ "server": "IP地址", "database": "数据库名", "username": "只读账号", "password": "密码", "driver": "ODBC Driver 17 for SQL Server"}
发动机发明后,并不是简单接入原来马车的车身,而是倒逼车身乃至整车架构重新设计。AI接入原有的业务应该也是这样。
 夜雨聆风
夜雨聆风