 夜雨聆风
夜雨聆风经常会被人问“现在什么模型最好用?”、“我的龙虾该用什么模型?”。
这些问题的本质是——模型选型。
这是所有用AI/Agent的人最容易问也是最关心的问题。
本期文章的内容,就是基于我烧了这么多tokens之后的答案。

聊 AI 模型怎么选,除了当前最强的Claude Opus 4.6之外,一般就是见仁见智、丰俭由人的话题。
有人看榜单,谁跑分高用谁。有人看体感,谁聊着顺用谁。有人看价格,便宜量大就是生产力。还有人直接上最贵的,图个省心。
这些都有道理,但都只对了一部分。
因为"模型怎么选"不是一个单点问题。它不是在问"谁最聪明"或"谁最便宜",而是在问:把模型放进真实工作流里,长期稳定地干活,我该看什么?
我自己跑 OpenClaw 这套多 Agent 系统,实打实烧了大量 tokens 之后,最大的体会是:模型选型最怕的,不是没答案,而是用一个过于片面的标准过早下了结论。
benchmark 分数高,说明基础能力不错——就像考试成绩好,说明这人聪明。但你把人招进团队,还得看他靠不靠谱、能不能持续输出、会不会配合上下游、放在具体岗位上能不能把活干完。模型也一样。
所以先说清楚:这篇文章不是模型测评文。
它不是要告诉你"谁第一、谁最强",而是把模型选型该看哪些维度、怎么结合场景判断讲清楚。至于我用过的这些模型各自表现如何、坑在哪儿,后面会专门再写一篇展开。
这篇先解决一个底层问题:选模型,你得先看懂那些分数在测什么,再看你的系统到底需要什么。
01
常见的 LLM 测评指标在测什么?

1)MMLU:综合知识面和理解力
覆盖历史、法律、医学、经济、科学等几十个方向的综合笔试。分数高,说明知识面广、基础理解力不错、处理常规问答不容易太离谱。
但知识面广不等于工程上就好使。
2)GPQA:高难度专业理解
和 MMLU 的区别在于更偏难、更偏深。不是问你知不知道,而是问你理解得够不够硬。更像高阶专业题,而不是普通笔试。
3)HumanEval:编程上机
给几道编程题,看模型写不写得对。能力下限指标——至少能告诉你这个模型基本的代码表达行不行。
但它更像编程考试,不像真实工程。
4)SWE-bench:真实项目修 bug
把模型扔进真实开源项目里,看它能不能定位问题、改对代码、跑通测试。比 HumanEval 更接近实际开发,因为它考的不只是写代码,还有理解项目上下文、处理代码历史包袱的能力。
5)长上下文能力
模型能不能记住大量信息,还能从里面准确提取关键内容。很多人一听"上下文窗口 100 万 token"就兴奋,但窗口大不等于真的会用——塞太多进去反而可能丢重点。
6)工具调用 / Agent 能力
能不能调 API、跑命令、读文件、多步往下推进。只会聊天是顾问,能调工具串任务才是真正干活的 Agent。
7)速度、成本、稳定性
最不性感,但在工程里往往最关键:响应快不快、单价高不高、容不容易限流超时、长任务时稳不稳、大规模调用扛不扛得住。
对生产系统来说,便宜、快、稳很多时候不是附加项,而是主指标。
02
按场景选模型,不同的分工关注不同的指标
知道了这些指标各自测什么,下一步是把它们和你的实际需求对上。
不要试图找"平均分最高"的模型——真实选型是找最匹配当前岗位的模型。
主要做代码生成、改仓库、修 bug
优先看:代码能力、长上下文、工具调用、长任务稳定性。
主要做研究、分析、内容生产
优先看:知识理解、多步推理、长文档处理、结构化表达。
做工具调用型 Agent、自动化流程
优先看:tool use 能力、多步任务一致性、失败恢复、成本和速度。
做多智能体协同系统(比如 OpenClaw)
这时候看的已经不是单模型能力,而是:岗位适配度、指令遵循、成本/速度比、上下文管理、稳定性、能否与其他 Agent 配合。
03
为什么 benchmark 分数和实际工程体感经常对不上?

这是很多人最困惑的地方。明明榜单分数很高,真用起来总觉得差点意思。
原因其实不复杂:
测试环境 vs 真实环境。 Benchmark 的问题描述完整、输入输出明确、工具环境受控。真实世界里需求常常模糊、日志不全、代码历史包袱重、到处是脏数据和未知依赖。
单次表现 vs 连续表现。 考试考一次,工作是连续的。很多模型第一轮回复漂亮,但继续往下压就开始漂。真实工程里的常见体验不是"这模型不聪明",而是"不耐用"。
不测协作成本。 有些模型纸面成绩好,但用起来特别累:prompt 得写很长、上下文得一直补、一不盯就跑偏。这种模型不是没能力,但它需要你花大量精力去管理,实际上没帮你卸载多少工作量。
不反映系统约束。 调用价格、响应速度、限流、超时、上下文成本、API 稳定性——这些工程里绑着你手脚的东西,榜单上一条都不会出现。
模型能力 ≠ 产品体验。 你实际用到的是模型能力 + 产品设计 + 工具链 + 交互方式的综合结果。同一个模型,套在不同产品里,体感可以差很远。
04
落到 OpenClaw:多 Agent 架构的模型怎么配?
这部分是我自己跑下来最有体感的地方。
在 OpenClaw 这种多智能体系统里,最容易犯的错误就是"谁最强就给谁所有岗位"。但实际上不同岗位对模型的需求差异很大:
主脑 / 调度 Agent — 不一定要亲自写代码,但要能听懂需求、理清问题、拆解任务、判断该找谁、收回结果。核心看上下文管理、指令遵循、多轮一致性、汇总表达。
编码执行 Agent — 真的要下场读仓库、改代码、跑命令、修 bug。核心看代码能力、多文件一致性、长任务续航、报错恢复。
搜索 / 情报 Agent — 搜、抓、读、摘、汇总。不一定要最强推理,但要快、稳、便宜,而且别太笨。
视觉 / 多模态 Agent — 看截图、看图、理解布局。这里要的不是通用聊天强,而是多模态理解强。
批处理 / 体力活 Agent — 活多、重复度高、预算敏感。最值钱的不是"最强大脑",而是稳定、便宜、能扛量。
所以最后你会发现,模型选型在多 Agent 系统里更像排兵布阵——每个位置需要的能力不同,合适比最强重要。
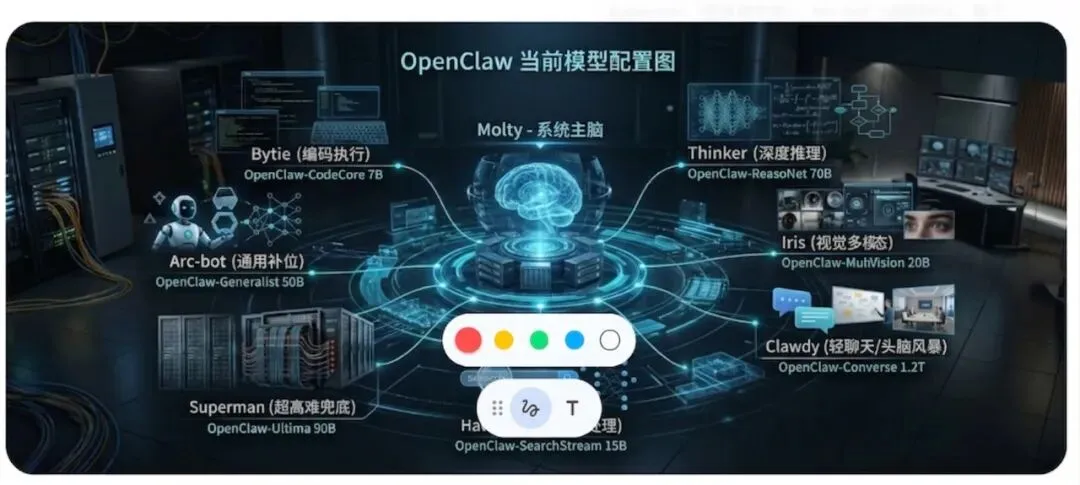
05
我当前的 OpenClaw 模型配置
最后分享一下我龙虾的模型配置。
这不是"全网最强榜单",也不是模型终评。它是我在 OpenClaw 这套多 Agent 工作流里,跑过活、踩过坑之后,现阶段用着比较顺的一套配置。
现役配置
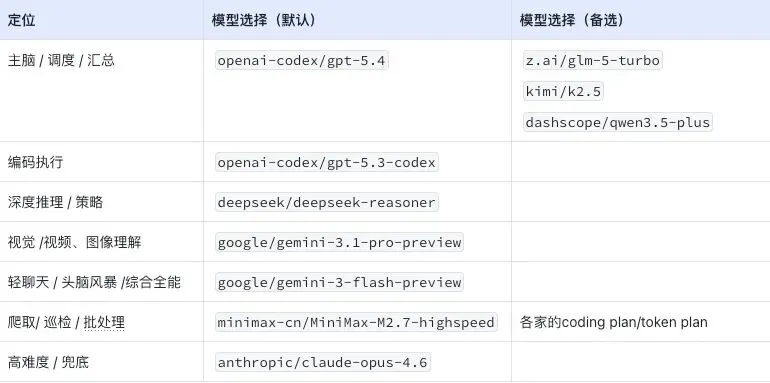
至于我为什么这么配、每个模型实际跑下来的表现和踩过的坑,后面会单独写一篇展开。
06
总结
选模型,不要只看谁跑分高。跑分是基础能力的参考,但真正决定用着顺不顺的,是模型在你的具体场景、具体岗位上的实际表现——稳定性、续航、配合度、成本,这些 benchmark 不测的东西。
落到 OpenClaw 这种多 Agent 系统里,选型逻辑就更清楚了:不是找一个全能冠军塞进所有岗位,而是根据每个岗位的实际需求,配上最合适的模型。
成熟的模型选型,不是冠军崇拜,是排兵布阵。
