 夜雨聆风
夜雨聆风极客朋友们,大家好,我是你们的老朋友。
最近后台收到很多创客和开发者的私信:
"老大,我的 OpenClaw 机械手/机器人刚开机时聪明得像钢铁侠,但只要连续跑上几个小时的任务,它就像得了'阿尔茨海默症'一样。昨天刚教它的抓取力度,今天全忘了,直接把鸡蛋捏稀碎!"
别再被骗了,OpenClaw 的底层逻辑不仅仅是机械结构和电机驱动,驱动它高阶决策的,本质上是一个大模型 Agent(智能体)。
当你的机器手在工作时,视觉流、坐标点、系统日志会不断塞满大模型的"上下文窗口"(你可以理解为人类的短期记忆/内存)。一旦内存满了,OpenClaw 默认的机制非常粗暴:直接把旧记忆"切掉"或者暴力压缩。
你的机器人不是电机坏了,它是"失忆"了。
今天,带大家彻底根治这个问题!针对不同阶段的玩家,我整理了两套目前市面上最主流的记忆升级方案。哪怕你是纯小白,看完也能让你的机器人拥有"灵魂"。
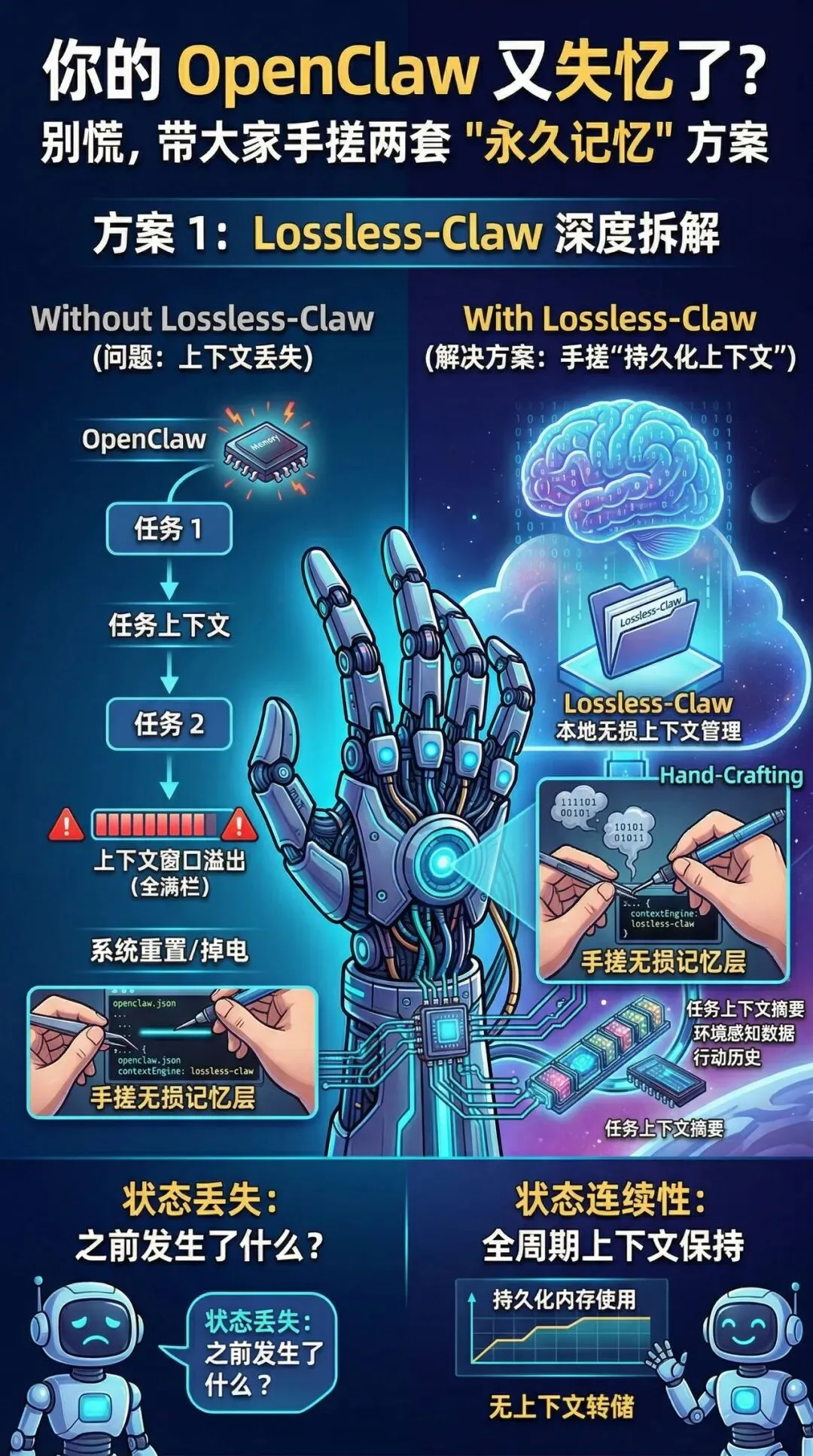
方案一:给大脑换个"无损压缩包" —— Lossless-Claw 插件
如果你只是在自己的电脑或树莓派上跑一个 OpenClaw,不想折腾复杂的云端数据库,那么 Lossless-Claw(LCM)插件 是你的首选。
它解决了什么痛点?
默认的 OpenClaw 在对话太长时,会像"狗熊掰棒子"一样,塞进新指令,丢掉老指令。特别是当你让 Agent 彻夜运行自动化任务时,一觉醒来,它可能连自己是谁都忘了。
怎么用?
极其简单,这就是个纯本地插件。
# 终端一键安装
npm install lossless-claw
然后在你的 openclaw.json 里把 contextEngine 指向它。这可能是目前成本最低、见效最快的防失忆外挂。
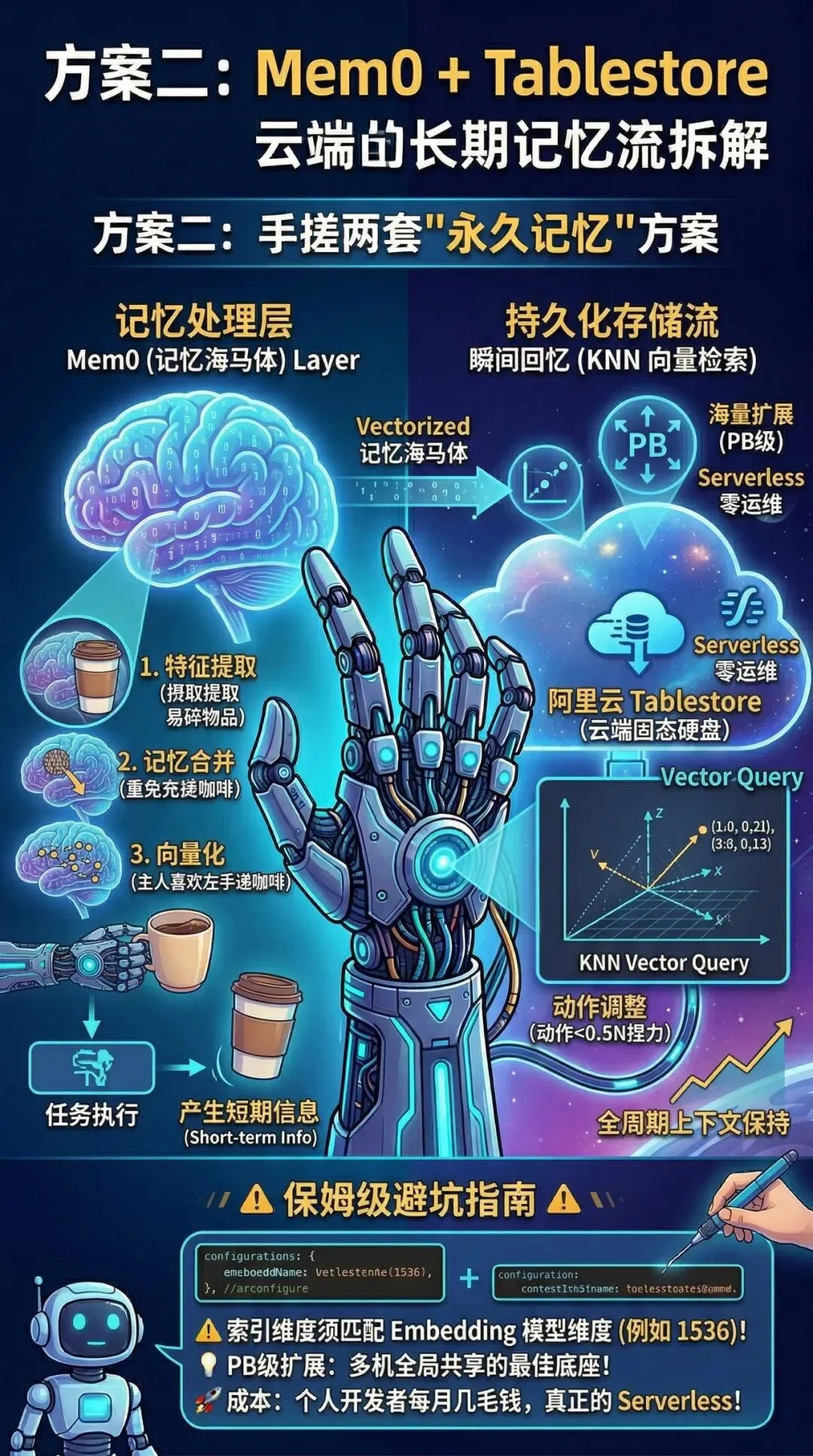
方案二:外接"无限容量的云端大脑" —— Mem0 + 阿里云 Tablestore
如果你有更高的追求——比如你有多台 OpenClaw 设备想共享经验,或者你希望机器人哪怕关机断电休眠一个月,开机后依然记得你的个人偏好,那么你需要的是"硬件级扩容"。
为什么不用本地文本?
很多小白喜欢往 MEMORY.md 文本里死记硬背,但文件一长,每次对话都要把整个文件发给大模型,不仅 API Token 费用原地爆炸,模型还会"看走眼"。
这套方案的降维打击点在于:
1. 多机共享
1 号机器人踩过的坑,2 号机器人瞬间就能学会。
2. 省钱神器
每次只调取最相关的几十个词,API 账单直接砍掉一大半!
3. 免运维(Serverless)
阿里云帮你管着数据库,你连服务器都不用买,按量付费,对个人开发者极其友好。
💡 总结:你应该怎么选?
选 Lossless-Claw,如果:
你是个人极客 设备只有一台 任务多为单次长线任务(比如让它挂机一整晚写代码/整理文件) 追求轻量化、零配置
选 Mem0 + Tablestore,如果:
你是硬核玩家或企业用户 想要打造跨设备的"多智能体协作(Multi-Agent)" 需要长达几个月甚至几年的永久记忆
当机器拥有了躯体(OpenClaw)和长久的记忆,我们才算真正跨入了具身智能的下半场。
别让你的 AI 成为一个"用完即弃"的工具,让它成为与你共同成长的数字伙伴。
