 夜雨聆风
夜雨聆风
OpenClaw 的评估引擎是个谎言
不是没有,是根本不算。
上一篇说「评估引擎是 OpenClaw 相对薄弱的一块」。这句话比较委婉含蓄。准确的说法是:OpenClaw 现在根本没有独立的评估引擎。有的只是主 Agent 的自我感觉良好。
在多 Agent 系统里,这不是小问题。这是结构性缺陷。
OpenClaw 的真实评估链路是什么样的
子 Agent 跑完任务,把结果写进自己的 sessions。主 Agent 读结果。主 Agent 判断对不对。主 Agent 决定接受还是打回去。
全程一个裁判:主 Agent。
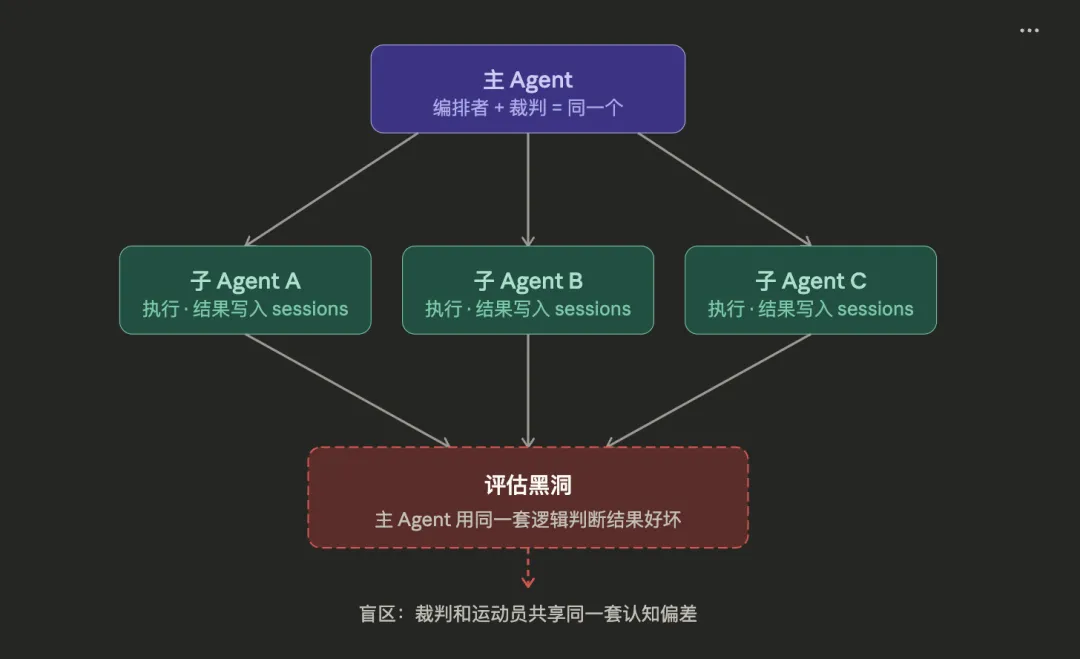
但主 Agent 也是任务的设计者、分解者、调度者。它对这个任务有预设,有偏好,有盲区。让它同时做裁判,就像让论文作者自己改自己的稿——不是不能发现错误,但系统性的认知偏差不会被发现。
更糟的是:sessions 是隔离的。主 Agent 看不到子 Agent 的推理过程,只能看到最终输出。子 Agent 在中间步骤犯了什么错、绕了什么弯路、在哪里猜了个答案继续跑——主 Agent 一概不知。它评估的,是一个被截断的事实。
你以为在验收交付物,其实在看快照。
为什么偏偏是多 Agent 场景最危险
单 Agent 的评估问题可以靠人工 review 兜底。任务链短,上下文完整,出了事可以复盘。
多 Agent 一展开,这条路就堵死了:
任务被拆成几个并行分支,每个分支有独立的 session,错误可能在任何一个节点静默发生,到主 Agent 汇总时,已经是几个有问题的结果被合成了一个「看起来完整」的交付物。
你永远不会知道哪个子 Agent 在不确定的时候赌了一把。
这才是多 Agent 评估的核心难题:错误的传播速度比人的检查速度快得多。
具体烂在哪里——三个真实场景
场景一:静默降级
子 Agent 被要求提取 50 份合同里的付款条款。其中 8 份格式异常,解析失败。子 Agent 没有报错,跳过了,继续处理剩下的 42 份。输出了一份看起来完整的表格。
主 Agent 收到表格,条目整齐,验收通过。
你发现问题的时候,是客户来问为什么少了 8 份合同的付款信息。
场景二:路径合理化
主 Agent 把一个调研任务拆给子 Agent,要求输出结论和信源。子 Agent 搜索失败,找不到有力的信源,但它判断「任务要求我输出结论」——于是输出了一个模糊的结论,配上了一个相关性很低的信源。
主 Agent 看到结论有了、信源有了,评估通过。
场景三:同源错误
主 Agent 和子 Agent 用同一个模型。这个模型对某类日期格式的理解有偏差,会把 2026/03 读成 3 月而不是 2026 年第 3 周。
子 Agent 犯了这个错误,主 Agent 审查时用同样的认知处理结果——没有发现异常,评估通过。
三个场景,三种不同的失败模式,一个共同的原因:没有独立的评估视角。
补法:不是加一个 Prompt,是换一种架构
市面上的建议大多停留在「让主 Agent 输出结构化评估报告」。这有用,但治标不治本。裁判换了格式,不代表换了视角。
真正有效的补法分两层。
第一层:接入外部评估工具
这是最容易被忽视的一步——不要试图让 Claude 自己评估 Claude。用专门的评估框架来做这件事。
DeepEval 是目前最成熟的开源 LLM 评估框架。它的核心设计就是把评估从 Agent 主流程里剥离出来,用独立的 metric 对输出打分。
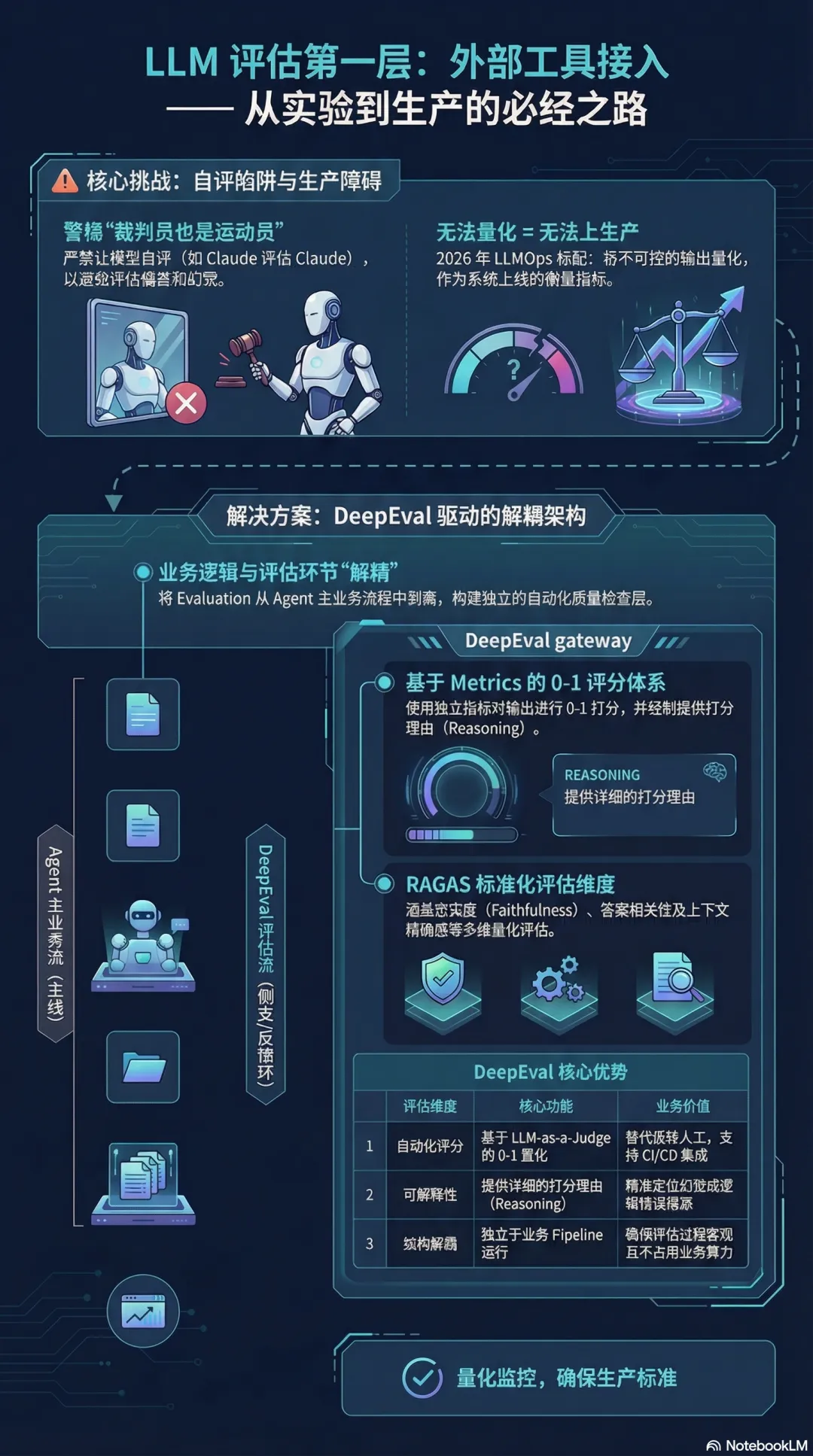
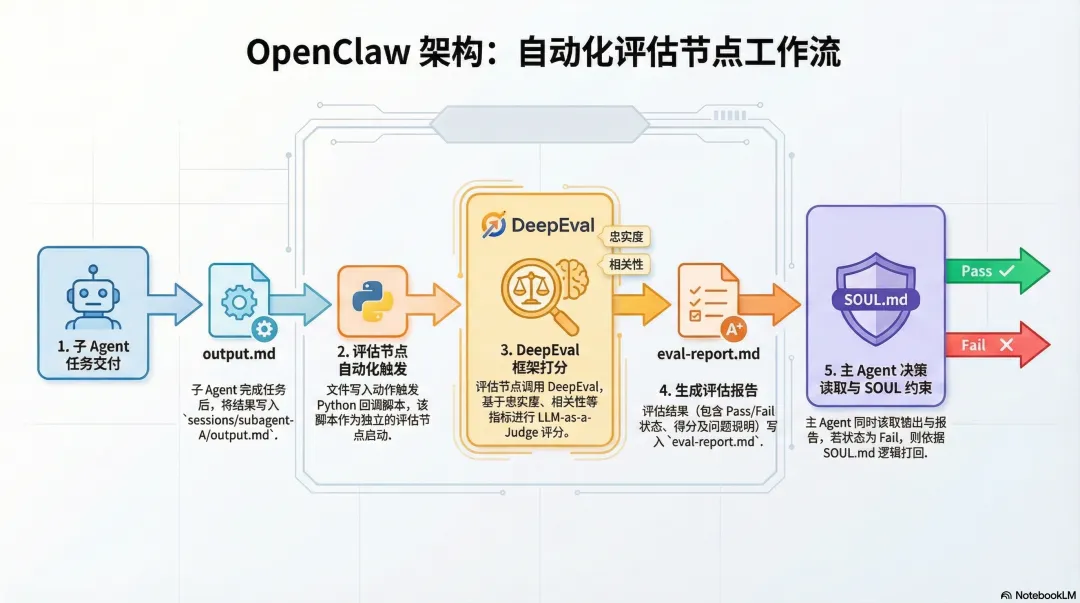
第二层:在 OpenClaw 架构里插入评估节点工具接进来之后,还需要在 OpenClaw 的流程里找到正确的插入点。
正确的位置是:子 Agent 输出之后、主 Agent 读取之前。
主 Agent 的 SOUL.md 里加一条约束:如果 eval-report.md 里有 fail 项,禁止直接接受输出,必须打回或上报。
这样主 Agent 还是做最终决策,但它的判断基础变了——它不再是唯一的信息来源,它在参考一份独立视角的审查报告。
现在还缺什么
接入了外部评估工具,插入了评估节点,Harness 的评估层才算真正存在。
但还有一个问题没解决:评估标准谁来定,怎么随任务演化?
现在的做法是把 schema 硬编码在评估脚本里。任务变了,评估标准没跟上,评估就开始失效。
更成熟的做法是让评估标准本身成为 Agent 配置的一部分——在openclaw.json 里给每个子 Agent 定义对应的评估 schema,让评估节点动态读取。
这不是小改动,需要 OpenClaw 在架构层面支持。目前还做不到。这是框架本身需要迭代的地方,不是靠 Prompt 能绕过去的。
承认这个限制,比假装它不存在重要得多。
你现在能做的:把 DeepEval 或 PromptFoo 接进来,在 sessions 目录里加一个评估节点,让主 Agent 强制读评估报告再做判断。
这不是最优解,但比现在强一个数量级。
DeepEval:https://github.com/confident-ai/deepeval
PromptFoo:https://github.com/promptfoo/promptfoo

下一篇教程
多 Agent 并行跑,评估结果互相矛盾——A 说对,B 说错,主 Agent 怎么办?冲突消解机制,以及什么时候该把决定权还给人。
OpenClaw 的评估引擎是个谎言
不是没有,是根本不算。
上一篇说「评估引擎是 OpenClaw 相对薄弱的一块」。这句话比较委婉含蓄。准确的说法是:OpenClaw 现在根本没有独立的评估引擎。有的只是主 Agent 的自我感觉良好。
在多 Agent 系统里,这不是小问题。这是结构性缺陷。
OpenClaw 的真实评估链路是什么样的
子 Agent 跑完任务,把结果写进自己的 sessions。主 Agent 读结果。主 Agent 判断对不对。主 Agent 决定接受还是打回去。
全程一个裁判:主 Agent。
但主 Agent 也是任务的设计者、分解者、调度者。它对这个任务有预设,有偏好,有盲区。让它同时做裁判,就像让论文作者自己改自己的稿——不是不能发现错误,但系统性的认知偏差不会被发现。
更糟的是:sessions 是隔离的。主 Agent 看不到子 Agent 的推理过程,只能看到最终输出。子 Agent 在中间步骤犯了什么错、绕了什么弯路、在哪里猜了个答案继续跑——主 Agent 一概不知。它评估的,是一个被截断的事实。
你以为在验收交付物,其实在看快照。
为什么偏偏是多 Agent 场景最危险
单 Agent 的评估问题可以靠人工 review 兜底。任务链短,上下文完整,出了事可以复盘。
多 Agent 一展开,这条路就堵死了:
任务被拆成几个并行分支,每个分支有独立的 session,错误可能在任何一个节点静默发生,到主 Agent 汇总时,已经是几个有问题的结果被合成了一个「看起来完整」的交付物。
你永远不会知道哪个子 Agent 在不确定的时候赌了一把。
这才是多 Agent 评估的核心难题:错误的传播速度比人的检查速度快得多。
具体烂在哪里——三个真实场景
场景一:静默降级
子 Agent 被要求提取 50 份合同里的付款条款。其中 8 份格式异常,解析失败。子 Agent 没有报错,跳过了,继续处理剩下的 42 份。输出了一份看起来完整的表格。
主 Agent 收到表格,条目整齐,验收通过。
你发现问题的时候,是客户来问为什么少了 8 份合同的付款信息。
场景二:路径合理化
主 Agent 把一个调研任务拆给子 Agent,要求输出结论和信源。子 Agent 搜索失败,找不到有力的信源,但它判断「任务要求我输出结论」——于是输出了一个模糊的结论,配上了一个相关性很低的信源。
主 Agent 看到结论有了、信源有了,评估通过。
场景三:同源错误
主 Agent 和子 Agent 用同一个模型。这个模型对某类日期格式的理解有偏差,会把 2026/03 读成 3 月而不是 2026 年第 3 周。
子 Agent 犯了这个错误,主 Agent 审查时用同样的认知处理结果——没有发现异常,评估通过。
三个场景,三种不同的失败模式,一个共同的原因:没有独立的评估视角。
补法:不是加一个 Prompt,是换一种架构
市面上的建议大多停留在「让主 Agent 输出结构化评估报告」。这有用,但治标不治本。裁判换了格式,不代表换了视角。
真正有效的补法分两层。
第一层:接入外部评估工具
这是最容易被忽视的一步——不要试图让 Claude 自己评估 Claude。用专门的评估框架来做这件事。
DeepEval 是目前最成熟的开源 LLM 评估框架。它的核心设计就是把评估从 Agent 主流程里剥离出来,用独立的 metric 对输出打分。
第二层:在 OpenClaw 架构里插入评估节点工具接进来之后,还需要在 OpenClaw 的流程里找到正确的插入点。
正确的位置是:子 Agent 输出之后、主 Agent 读取之前。
主 Agent 的 SOUL.md 里加一条约束:如果 eval-report.md 里有 fail 项,禁止直接接受输出,必须打回或上报。
这样主 Agent 还是做最终决策,但它的判断基础变了——它不再是唯一的信息来源,它在参考一份独立视角的审查报告。
现在还缺什么
接入了外部评估工具,插入了评估节点,Harness 的评估层才算真正存在。
但还有一个问题没解决:评估标准谁来定,怎么随任务演化?
现在的做法是把 schema 硬编码在评估脚本里。任务变了,评估标准没跟上,评估就开始失效。
更成熟的做法是让评估标准本身成为 Agent 配置的一部分——在openclaw.json 里给每个子 Agent 定义对应的评估 schema,让评估节点动态读取。
这不是小改动,需要 OpenClaw 在架构层面支持。目前还做不到。这是框架本身需要迭代的地方,不是靠 Prompt 能绕过去的。
承认这个限制,比假装它不存在重要得多。
你现在能做的:把 DeepEval 或 PromptFoo 接进来,在 sessions 目录里加一个评估节点,让主 Agent 强制读评估报告再做判断。
这不是最优解,但比现在强一个数量级。
DeepEval:https://github.com/confident-ai/deepeval
PromptFoo:https://github.com/promptfoo/promptfoo
下一篇教程
多 Agent 并行跑,评估结果互相矛盾——A 说对,B 说错,主 Agent 怎么办?冲突消解机制,以及什么时候该把决定权还给人。
OpenClaw 的评估引擎是个谎言
不是没有,是根本不算。
上一篇说「评估引擎是 OpenClaw 相对薄弱的一块」。这句话比较委婉含蓄。准确的说法是:OpenClaw 现在根本没有独立的评估引擎。有的只是主 Agent 的自我感觉良好。
在多 Agent 系统里,这不是小问题。这是结构性缺陷。
OpenClaw 的真实评估链路是什么样的
子 Agent 跑完任务,把结果写进自己的 sessions。主 Agent 读结果。主 Agent 判断对不对。主 Agent 决定接受还是打回去。
全程一个裁判:主 Agent。
但主 Agent 也是任务的设计者、分解者、调度者。它对这个任务有预设,有偏好,有盲区。让它同时做裁判,就像让论文作者自己改自己的稿——不是不能发现错误,但系统性的认知偏差不会被发现。
更糟的是:sessions 是隔离的。主 Agent 看不到子 Agent 的推理过程,只能看到最终输出。子 Agent 在中间步骤犯了什么错、绕了什么弯路、在哪里猜了个答案继续跑——主 Agent 一概不知。它评估的,是一个被截断的事实。
你以为在验收交付物,其实在看快照。
为什么偏偏是多 Agent 场景最危险
单 Agent 的评估问题可以靠人工 review 兜底。任务链短,上下文完整,出了事可以复盘。
多 Agent 一展开,这条路就堵死了:
任务被拆成几个并行分支,每个分支有独立的 session,错误可能在任何一个节点静默发生,到主 Agent 汇总时,已经是几个有问题的结果被合成了一个「看起来完整」的交付物。
你永远不会知道哪个子 Agent 在不确定的时候赌了一把。
这才是多 Agent 评估的核心难题:错误的传播速度比人的检查速度快得多。
具体烂在哪里——三个真实场景
场景一:静默降级
子 Agent 被要求提取 50 份合同里的付款条款。其中 8 份格式异常,解析失败。子 Agent 没有报错,跳过了,继续处理剩下的 42 份。输出了一份看起来完整的表格。
主 Agent 收到表格,条目整齐,验收通过。
你发现问题的时候,是客户来问为什么少了 8 份合同的付款信息。
场景二:路径合理化
主 Agent 把一个调研任务拆给子 Agent,要求输出结论和信源。子 Agent 搜索失败,找不到有力的信源,但它判断「任务要求我输出结论」——于是输出了一个模糊的结论,配上了一个相关性很低的信源。
主 Agent 看到结论有了、信源有了,评估通过。
场景三:同源错误
主 Agent 和子 Agent 用同一个模型。这个模型对某类日期格式的理解有偏差,会把 2026/03 读成 3 月而不是 2026 年第 3 周。
子 Agent 犯了这个错误,主 Agent 审查时用同样的认知处理结果——没有发现异常,评估通过。
三个场景,三种不同的失败模式,一个共同的原因:没有独立的评估视角。
补法:不是加一个 Prompt,是换一种架构
市面上的建议大多停留在「让主 Agent 输出结构化评估报告」。这有用,但治标不治本。裁判换了格式,不代表换了视角。
真正有效的补法分两层。
第一层:接入外部评估工具
这是最容易被忽视的一步——不要试图让 Claude 自己评估 Claude。用专门的评估框架来做这件事。
DeepEval 是目前最成熟的开源 LLM 评估框架。它的核心设计就是把评估从 Agent 主流程里剥离出来,用独立的 metric 对输出打分。
第二层:在 OpenClaw 架构里插入评估节点工具接进来之后,还需要在 OpenClaw 的流程里找到正确的插入点。
正确的位置是:子 Agent 输出之后、主 Agent 读取之前。
正确的位置是:子 Agent 输出之后、主 Agent 读取之前。
主 Agent 的 SOUL.md 里加一条约束:如果 eval-report.md 里有 fail 项,禁止直接接受输出,必须打回或上报。
这样主 Agent 还是做最终决策,但它的判断基础变了——它不再是唯一的信息来源,它在参考一份独立视角的审查报告。
现在还缺什么
接入了外部评估工具,插入了评估节点,Harness 的评估层才算真正存在。
但还有一个问题没解决:评估标准谁来定,怎么随任务演化?
现在的做法是把 schema 硬编码在评估脚本里。任务变了,评估标准没跟上,评估就开始失效。
更成熟的做法是让评估标准本身成为 Agent 配置的一部分——在openclaw.json 里给每个子 Agent 定义对应的评估 schema,让评估节点动态读取。
这不是小改动,需要 OpenClaw 在架构层面支持。目前还做不到。这是框架本身需要迭代的地方,不是靠 Prompt 能绕过去的。
承认这个限制,比假装它不存在重要得多。
你现在能做的:把 DeepEval 或 PromptFoo 接进来,在 sessions 目录里加一个评估节点,让主 Agent 强制读评估报告再做判断。
这不是最优解,但比现在强一个数量级。
DeepEval:https://github.com/confident-ai/deepeval
DeepEval:https://github.com/confident-ai/deepeval
PromptFoo:https://github.com/promptfoo/promptfoo
PromptFoo:https://github.com/promptfoo/promptfoo
PromptFoo:https://github.com/promptfoo/promptfoo
下一篇教程
多 Agent 并行跑,评估结果互相矛盾——A 说对,B 说错,主 Agent 怎么办?冲突消解机制,以及什么时候该把决定权还给人。
