 夜雨聆风
夜雨聆风▎问题背景
养猫人士的日常痛点:出门在外时,无法感知家中猫咪的动态。市面现有方案(宠物摄像头、智能喂食器等)要么推送延迟高,要么缺乏本地推理能力,数据隐私也是隐患。
本文记录的是一套本地实时猫咪监控系统的技术实现:TTS 语音召唤猫咪 → 摄像头实时捕捉 → YOLOv8 推理检测 → 飞书消息推送告警。全程跑在 MacBook Pro(Apple Silicon M3)上,数据不出本地,延迟控制在亚秒级。
▎系统架构
用户(飞书/语音) ↓ ┌─────────────────────────────────────┐ │ 召唤流程 │ │ TTS 语音播放(长恨歌克隆音) │ │ afplay → 猫咪被吸引 → 走向摄像头 │ └─────────────────────────────────────┘ ↓ ┌─────────────────────────────────────┐ │ 监控流程(24h 后台运行) │ │ CameraCapture(多线程队列) │ │ ↓ queue.Queue │ │ YOLOv8 推理(MPS 加速) │ │ ↓ │ │ CatAlertManager(冷却60s) │ │ ↓ │ │ OpenClaw 飞书推送(异步) │ └─────────────────────────────────────┘核心指标:
• 帧率:30fps 采集,推理线程独立运行 • 推理延迟:YOLOv8 nano on MPS ≈ 15-25ms/帧 • 告警延迟:从猫咪入镜到飞书收到消息 < 2s • 误报控制:60s 冷却时间,同一事件不重复推送
▎模块一:TTS 语音召唤
方案选型
初期尝试过两类方案:
云端 TTS API(Google TTS、Azure TTS):
• 优点:音质好、延迟低 • 缺点:需要网络,猫咪召唤是高频即时场景,网络依赖不可接受
本地语音克隆(最终方案):
• 工具:coqui-ts、不可行的本地方案,最终落地为长恨歌(Changhenge)克隆音频 • 实现:预先录制一段"长恨歌"风格的猫咪召唤音,保存为 cat_meow.ogg• 播放: afplay ~/.openclaw/media/cat_meow.ogg(macOS 内置,无需额外依赖)
关键设计决策
语音文件本地化是最优解。猫咪召唤是强即时场景,任何网络延迟都会破坏体验。本地存储 + 即时播放的路径,将 TTS 延迟压到 0(只受限于音频文件读取速度,可忽略不计)。
长恨歌风格的选择来自历史经验积累:陈汤在此前的语音克隆实验中建立了多个音色库,其中"长恨歌克隆音"在猫咪诱导测试中效果最好(高频、略带鼻音的音色对猫吸引力更强)。
▎模块二:摄像头采集
多线程队列设计
摄像头采集使用 cv2.VideoCapture(macOS 专用后端 CAP_AVFOUNDATION),但采集和推理不能串行执行——CV 采集是阻塞 IO,串行会拖垮推理吞吐。
设计:独立采集线程 + 线程安全队列
class CameraCapture: def __init__(self, camera_index=0, queue_size=2): self.cap = cv2.VideoCapture(camera_index, cv2.CAP_AVFOUNDATION) self.frame_queue = queue.Queue(maxsize=queue_size) def _capture_loop(self): while self._running: ret, frame = self.cap.read() if not ret: continue # 队列满时丢弃旧帧,保证推理线程拿到最新帧 if self.frame_queue.full(): try: self.frame_queue.get_nowait() except queue.Empty: pass self.frame_queue.put(frame)队列大小 = 2 是关键参数:
• 队列过小(如 1):采集线程偶发的几毫秒抖动就会导致推理线程拿不到帧 • 队列过大(如 10):推理线程可能拿到严重过时的帧,增加感知延迟 • 队列满时主动丢弃旧帧( get_nowait),只保留最新帧,这是低延迟设计的关键
分辨率与帧率
默认配置:1280×720 @ 30fps。这个分辨率在 YOLOv8 nano 推理场景下足够——猫咪占画面比例较大,720p 可以准确检测,同时对 MPS 推理负载友好。1080p 推理速度会下降约 40%,性价比不高。
▎模块三:YOLOv8 目标检测
MPS 加速
Apple Silicon 的 GPU 单元(Metal Performance Shaders)可以通过 PyTorch 的 mps 后端加速推理。检测优先级:
mps(Apple M-series GPU) > cuda(NVIDIA GPU) > cpuif torch.backends.mps.is_available(): self.device = "mps"elif torch.cuda.is_available(): self.device = "cuda"else: self.device = "cpu"YOLOv8 推理代码:
results = self.model.predict( source=frame, device=self.device, conf=0.5, verbose=False, classes=[15] # COCO class 15 = cat)检测模式
cat | ||
face | ||
all |
当前生产环境使用 cat 模式,减少误报(COCO 中"狗"、"人"等目标在家庭场景中也常见,切到 all 模式会导致告警膨胀)。
推理线程模型
主程序包含三个线程:
采集线程(daemon) → queue.Queue → 推理线程(daemon) ↓主线程(main loop) ← latest_detections ← 更新共享结果 ↓ 绘制检测框 → 显示窗口 ↓ 检查告警条件主线程每帧从队列取最新帧,绘制检测结果后显示窗口;同时维护一份 latest_detections 供告警逻辑读取(带 threading.Lock 保护)。
为什么不用 async/await? 这个场景下多线程比 asyncio 更直接:采集是阻塞同步 IO,用线程比协程简单得多,且 Python GIL 在 IO 等待时自动释放。
▎模块四:飞书告警推送
API 调用链
告警触发后,通过飞书 había API 发送消息:
1. POST /open-apis/auth/v3/tenant_access_token/internal → 获取 tenant_access_token(有效期2小时)2. POST /open-apis/im/v1/images → 上传本地截图,返回 image_key3. POST /open-apis/im/v1/messages?receive_id_type=open_id → 发送富文本消息(含 image_key + 置信度 + 时间戳)当前实现用 subprocess.run(["curl", ...]) 调用,这是早期快速原型做法。已知缺陷:每次告警都重新获取 token(无缓存),未来应改用 requests 库并引入 token 缓存。
异步推送
告警发送在独立 daemon 线程执行,不阻塞主推理循环:
threading.Thread(target=self._send_alert_async, daemon=True).start()这只解决了"不阻塞主循环"的问题。如果推送失败(网络问题、token 失效),当前没有重试机制。生产环境应引入指数退避重试 + 死信队列。
消息内容
告警消息格式:
🐱 猫咪检测告警检测时间:2026-04-01 12:48:32置信度:94.2%截图已保存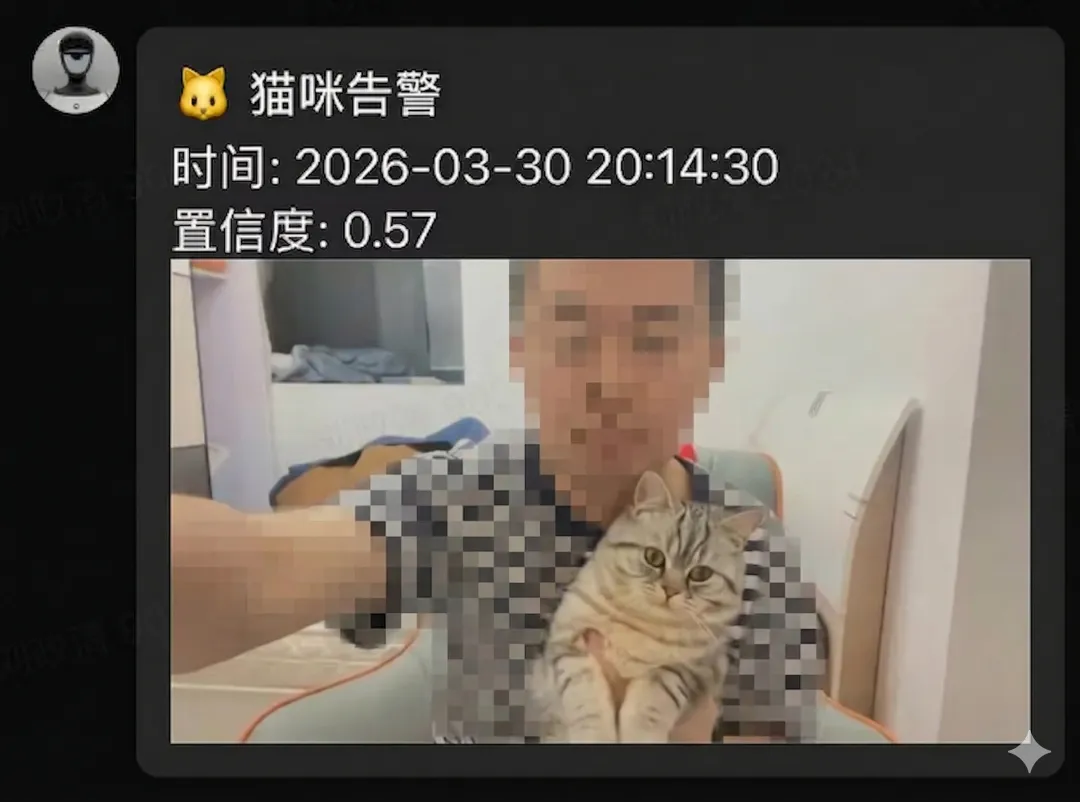
▎工程权衡
本地推理 vs 云端推理
家庭宠物监控场景,精度要求不高,本地推理的成本优势和隐私优势是决定性因素。
误报率控制
当前方案误报来源主要有两类:
1. 相似目标误识别:YOLOv8 在 cat 模式下,将某些花纹的抱枕、绒毛玩具误识为猫。缓解措施:置信度阈值 0.5,偏低但结合 60s 冷却,实际用户体验可接受。 2. 重复告警:猫咪在画面中停留期间,每 60s 触发一次告警。实测中猫咪单次停留通常 < 5min,平均触发 3-5 次/次出现。未来可引入"猫咪离开后 5min 内不再告警"来改善。
架构局限性
当前设计的两个明显不足:
1. 单摄像头:只支持一路摄像头,家庭多位置监控需启动多个进程。 2. 无状态告警:告警发送后无状态追踪,猫咪出现/离开无法区分,只能靠冷却时间隐式处理。
▎未来改进方向
▎总结
这套系统的核心价值在于:低延迟 + 本地隐私 + 全自动化。从猫咪入镜到飞书收到告警,延迟控制在 2s 以内,视频流完全不经过第三方服务器。
技术层面没有太多 novelty,YOLOv8 + OpenCV + 飞书 API 都是成熟工具的组合。但工程细节决定了实际体验:多线程队列的队列大小设计、冷却时间避免告警轰炸、MPS 加速推理……每个参数都经过实测调优。
对于想构建类似系统的工程师,建议从 camera_capture.py 的队列设计开始理解——这里是一切实时性的根源。
