 夜雨聆风
夜雨聆风2026年,"Agent框架"已经成为一个被过度使用的词。但翻开具体代码,才会发现各个项目想解决的问题差异悬殊——有的要在虚拟城市里跑几千个LLM居民,有的要把自然语言翻译成PDDL形式语言,有的只想给开发者造一把顺手的终端工具。
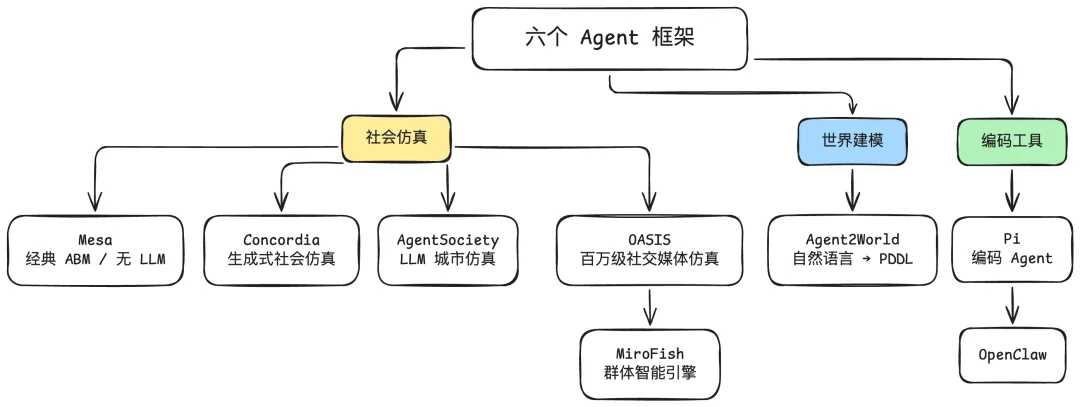
这篇文章拆解六个框架:Mesa、Concordia、AgentSociety、OASIS、Agent2World和Pi。
六个框架大致分成三类。第一类是社会仿真,用Agent建模人类群体行为,Mesa、Concordia、AgentSociety、OASIS都属于这个方向,但各自的切入点截然不同;第二类是形式化世界建模,Agent2World想把LLM的生成能力和符号规划系统对接起来;第三类是开发工具,Pi是一个给开发者日常用的终端Agent。
相关阅读Claude Code、Codex、Gemini CLI 与 OpenClaw 的四维对比
Mesa:不用 LLM 的那个
Mesa 是 Python 生态里历史最长的 Agent-Based Modeling 框架,定位是 NetLogo 和 Repast 的 Python 替代品。核心逻辑极其简单:模型管理一批 Agent,Agent 按照调度器的顺序依次执行步骤。
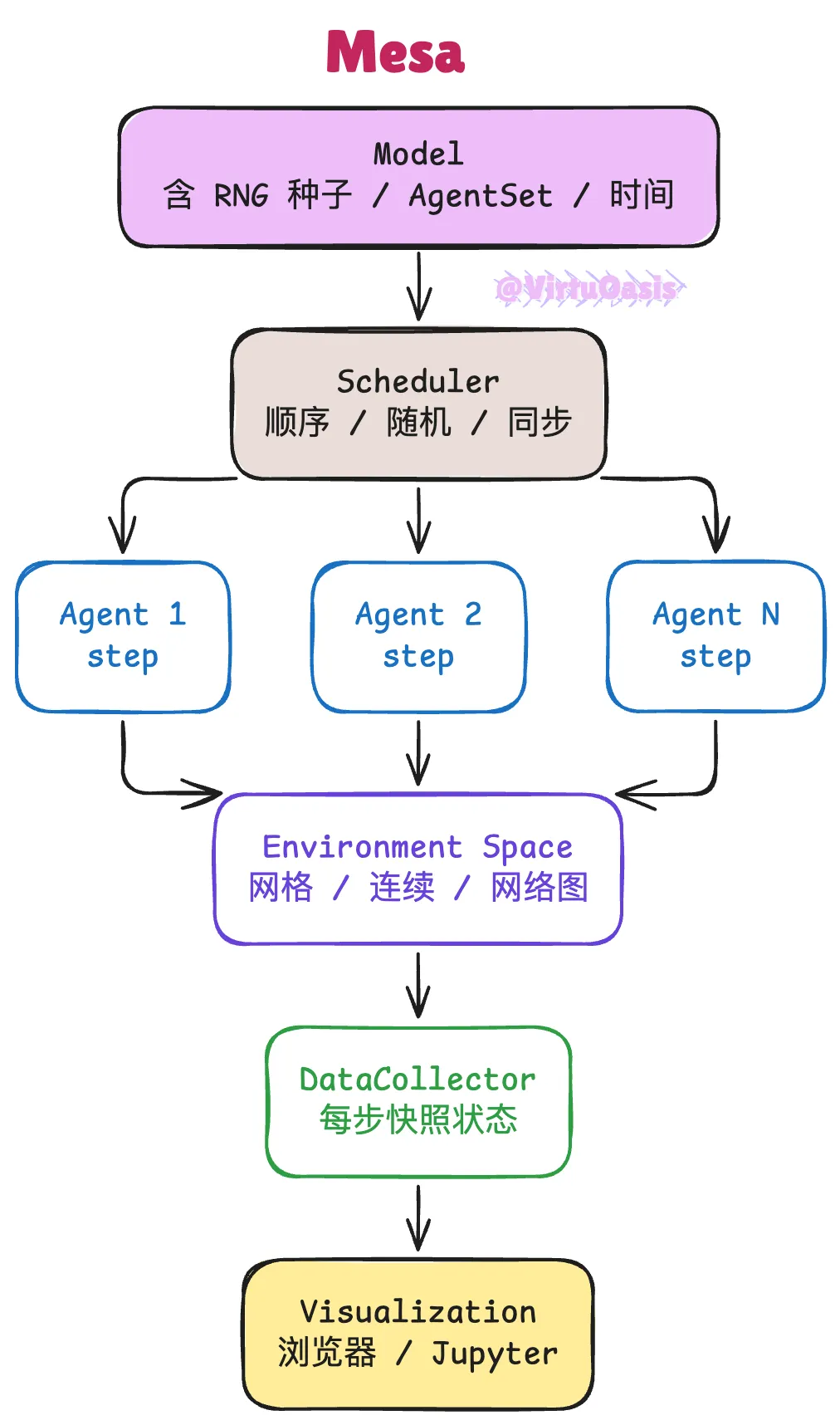
运行逻辑:每次调用 model.step() 时,调度器按照配置的方式(轮询、随机抽取或批量同步)依次激活各 Agent,每个 Agent 执行自己的 step() 方法修改局部状态或与空间交互,DataCollector 在步结束后自动快照所需的模型和 Agent 属性,供后续 pandas 分析。整个过程完全同步、单线程,没有任何异步。
Mesa 4 引入了 Observable 信号系统——模型属性可以标记为 Observable(),UI 组件订阅后能响应式更新,这是从批量轮询向响应式渲染迈出的一步。此外,模型同时持有一个 Python 标准库的 random 和一个 NumPy 的 rng,都在构造时用同一个种子初始化,确保任何用到随机数的地方都可以完全复现。Scenario 类是一个近期加入的功能,允许你把模型参数化,一次性定义多组参数批量运行,适合做参数扫描实验。
Mesa 的设计目标是科学建模,不是对话式 AI。Schelling 隔离模型、捕食者-猎物模型、疾病传播模型,这类规则确定、行为可控的仿真,Mesa 做起来非常干净。它没有接入 LLM,也没有打算接入——科学仿真首先要可复现,引入 LLM 会带来不可解释性,与学术研究的严格性要求相悖。
如果研究问题需要 Agent 像真人一样"读懂"一段文字再决策,Mesa 帮不上忙。
Concordia:把桌游 GM 搬进 LLM
Concordia (google-deepmind/concordia) 来自 Google DeepMind,借用了桌面角色扮演游戏的结构来组织仿真。核心模式:若干玩家 Agent + 一个 Game Master(GM)。Agent 用自然语言描述自己的行动意图,GM 负责判断这个意图在仿真世界里会产生什么结果。
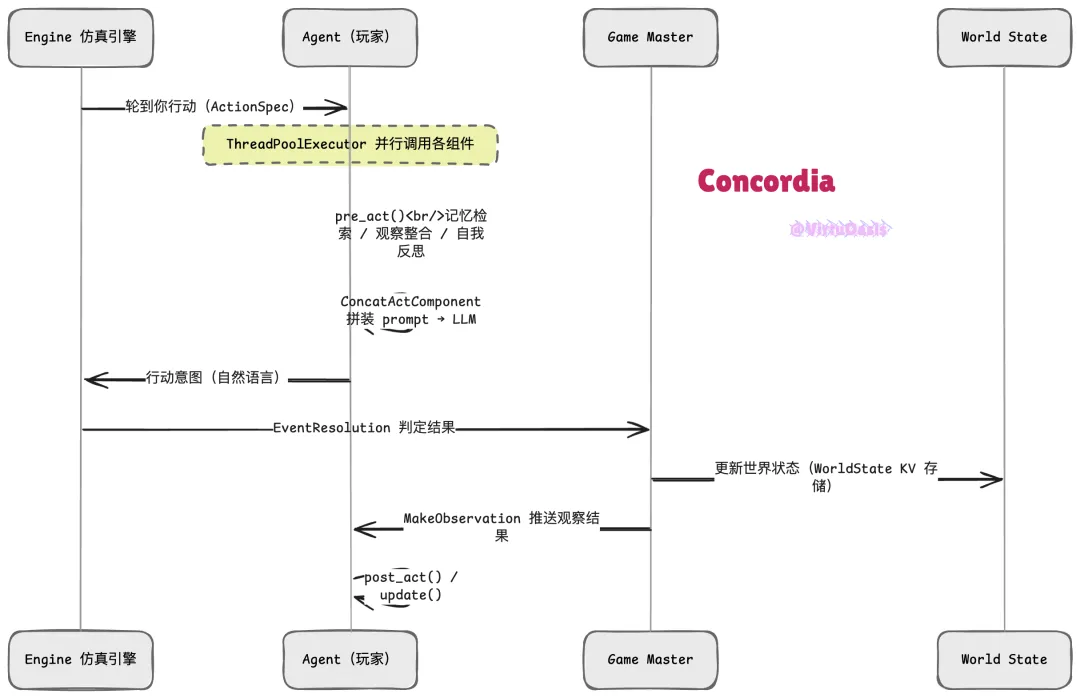
运行逻辑:仿真引擎在每一步调用 NextActing 组件决定下一个出场的 Agent,然后以 ActionSpec(约定返回格式,比如自由文本、选项列表)触发该 Agent 的 act() 方法。act() 内部用 ThreadPoolExecutor 并行调用所有 context 组件的 pre_act(),收集各组件的输出后,ConcatActComponent 把它们拼成一个完整的 prompt 送给 LLM,得到行动文本。GM 的 EventResolution 组件接收这个文本,用另一次 LLM 调用判断物理合理性,更新 WorldState,再由 MakeObservation 把结果异步推送给相关 Agent 的观察队列。
Concordia 对并发安全的处理很细致——act() 和 observe() 方法都用 _control_lock 包住,同一个 Agent 不能同时执行这两个操作,但不同 Agent 之间是可以并发运行的。AssociativeMemory 组件用向量嵌入做语义检索,不仅仅是按时间取最近的记忆,而是按相关性召回——Agent 遇到某个场景时会想起"语义上相似"的过去经历。FormativeMemoriesInitializer 是一个在仿真开始时一次性运行的 GM 组件,它会给每个 Agent 生成有厚度的背景故事和早期记忆,让 Agent 从第一步起就有"历史"。ActionSpecIgnored 类型的组件是 Concordia 设计里一个聪明的细节——这类组件的输出不依赖当前的 ActionSpec,专门用来构建 Agent 的长期自我认知(比如"我是什么样的人"),可以作为 chain-of-thought 的上游节点,其输出被后续决策组件引用。
优势:模块化程度高,适合研究者快速组合不同认知架构做对比实验。支持经济学、社会心理学、AI 安全等多个场景。
劣势:理解组件生命周期和通信机制需要一些时间。大规模仿真时 LLM 调用成本较高,每个 Agent 每步可能触发多次 LLM 请求。
AgentSociety:城市里的 LLM 居民
AgentSociety (tsinghua-fib-lab/agentsociety) 来自清华大学,专门面向城市仿真——交通、经济、社会行为,在一个虚拟城市空间里同时跑大量 LLM 驱动的 Agent。
架构分六层,自上而下分别负责不同粒度的控制:
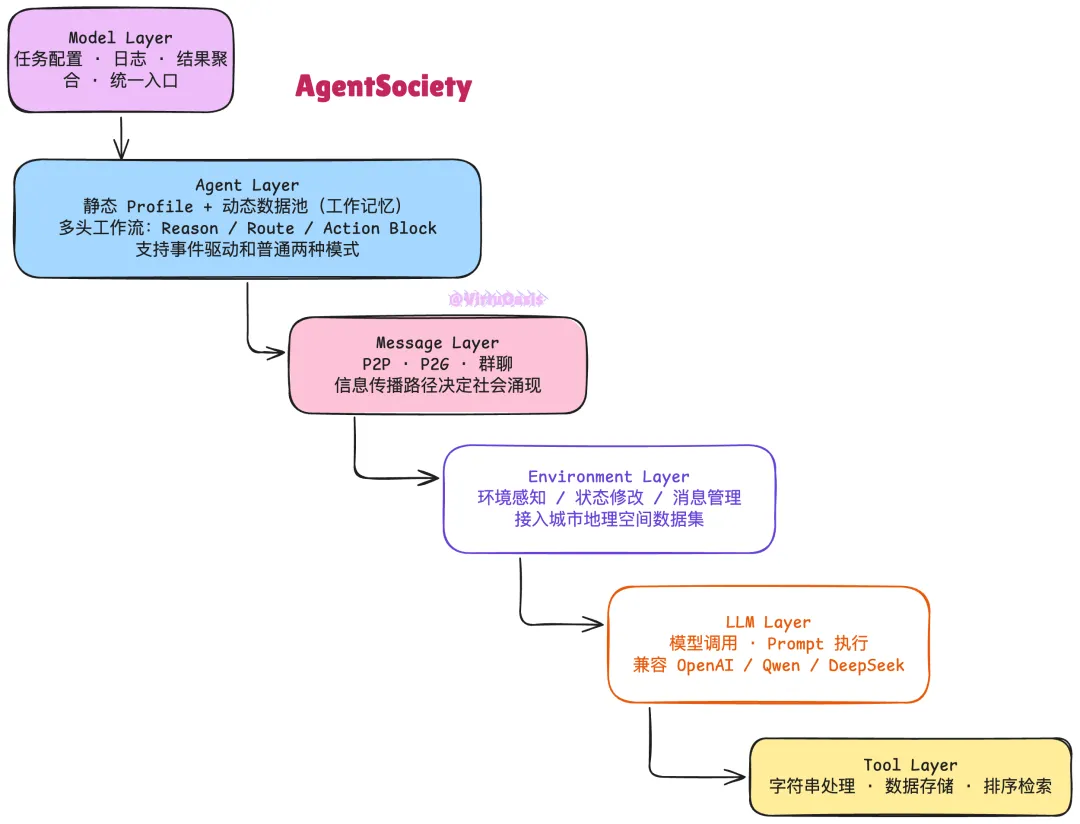
运行逻辑:任务在 Model Layer 配置,包括 Agent 数量、LLM 选型、实验参数、日志策略。Agent 按照"多头工作流"运行:先由 Reason Block 调用 LLM 对当前上下文和可用工具做推理,再由 Route Block 选择下一步执行路径(支持用 LLM 动态路由,也可以用规则静态路由),最后由 Action Block 执行实际操作(移动、发消息、消费、投票……)。支持事件驱动模式,外部事件(如政策变化、突发事件)可以注入并触发特定 Agent 的反应。
Agent 的记忆分两层——静态 Profile 存储不变的人物属性(年龄、职业、居住地、价值观),动态数据池充当工作记忆存储当前状态。内存设计参考了认知科学里"长时记忆 + 工作记忆"的区分,这在 LLM Agent 里并不多见。可以在 Profile 里直接挂载心理学理论约束——比如 Maslow 需求层次理论或计划行为理论——让 Agent 的行为满足理论预测,而不只是凭 LLM 自由发挥。研究人员可以通过内置的 Interview 和 Survey 工具在仿真过程中随时"采访" Agent,记录某时刻的心理状态和决策动机,这对社会科学实验很有价值。框架带了前端可视化界面和 Docker 部署支持,不需要自己搭监控系统。
目标问题:如何在城市规模仿真里让 LLM Agent 产生有理论依据的社会行为,同时保留研究干预(interventions)的能力。但是系统较重,部署依赖城市数据集,迁移到新场景需要较多工作。
OASIS:把一百万个 Agent 塞进社交媒体
OASIS (camel-ai/oasis) 来自 CAMEL-AI,目标是:用 LLM Agent 模拟真实社交媒体平台,支持百万用户规模。它仿照 Twitter 和 Reddit 的机制,让 Agent 可以发帖、评论、点赞、关注、举报,共 23 种行动类型。
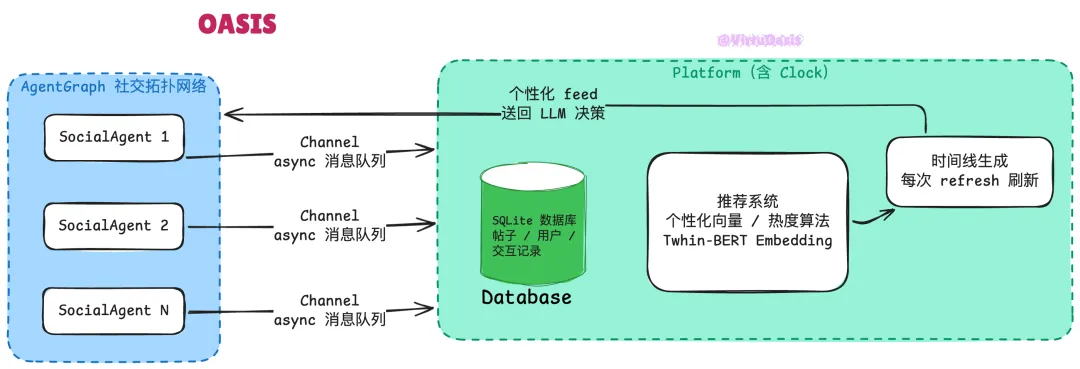
运行逻辑:env.reset() 初始化数据库和 Agent Graph,然后循环调用 env.step(actions)。每一步里,每个 Agent 通过 Channel(异步消息队列)从平台拿到自己的个性化时间线,时间线由推荐系统根据 Agent 的兴趣向量从数据库里筛选。Agent 的 LLM 读到这条 feed,决定执行哪个动作(或者 do_nothing),通过 SocialAction 把操作写回平台。平台同步更新 SQLite 记录,热度分数重新计算,下一次 refresh 时的推荐结果随之改变。整个循环是异步的,多个 Agent 的决策可以并发执行,Platform 端用 asyncio 串行处理写操作以避免数据库冲突。
Platform 里有一个 Clock,默认时间加速因子是 60——仿真里过一秒,现实世界对应一分钟。这个设计让长周期社交行为(比如一条帖子在24小时内的传播曲线)在几分钟内跑完。推荐系统提供四种可选算法:基于 Twhin-BERT 向量化的个性化匹配、带行为轨迹追踪的个性化算法、Reddit 风格的热度排序、随机推荐——对照实验组和实验组可以用不同推荐策略,直接观察算法对群体行为的影响。SocialAgent 继承自 CAMEL 的 ChatAgent,本质上是一个带 UserInfo Profile 和工具集的对话 Agent,工具集就是平台允许的那 23 种动作的 OpenAI function calling 包装。AgentGraph 管理社交网络拓扑,记录关注关系,这影响哪些 Agent 的帖子会优先出现在谁的时间线里——和真实平台的社交图谱逻辑一致。
实际应用:MiroFish(666ghj/MiroFish,45k+ Star,2025年11月上线)在 OASIS 的社会仿真基础上构建了一套"群体智能预测引擎"。它的运行逻辑是:输入一段场景描述 → GraphRAG 提取实体关系 → 生成角色配置 → 在 OASIS 的 Twitter/Reddit 双平台上跑多 Agent 仿真 → 动态记忆更新 → 自动生成预测报告。
MiroFish 把 OASIS 从研究工具变成了预测产品——给它一个商业决策、政策变化或市场场景,它会在仿真世界里跑一遍群体反应,然后告诉你大概率会发生什么。
现实约束:百万 Agent 是设计上限,实际研究中往往用几百到几千个 Agent 跑实验。LLM 调用成本是真实瓶颈,规模放大主要靠降低每个 Agent 的调用频率或用更轻量的模型。
Agent2World:教 LLM 写世界规则
前面四个框架都是拿 Agent 去仿真或执行任务,Agent2World 的角度不同——它想让 LLM 生成可执行的形式化世界模型,主要是 PDDL(规划领域定义语言)格式和可运行的模拟器代码。
LLM 能写出看起来合理的 PDDL,但静态文法验证通过不代表语义正确。一个"能跑"的规划域,在实际规划器执行时可能产生完全错误的行为,只有真正跑一跑才知道哪里出了问题。
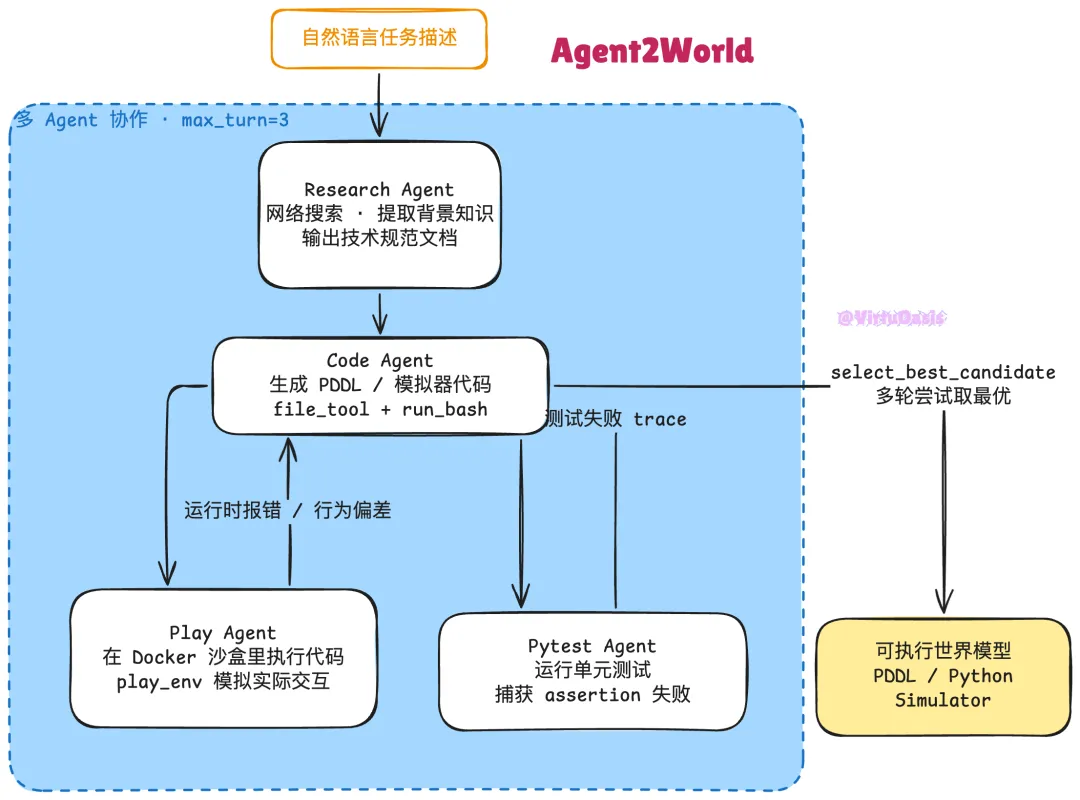
运行逻辑:Research Agent 先对任务做背景调研,通过 web search 生成一份技术规范文档,这份文档随后作为 Code Agent 的 grounding 信息。Code Agent 生成代码后,Play Agent 和 Pytest Agent 并发验证——Play Agent 在 Docker 沙盒里真实执行环境,像玩家一样运行几步看行为是否符合预期;Pytest Agent 跑单元测试看边界条件。两者的失败信息同时返回给 Code Agent 进行修复,这个闭环反复迭代直到验证通过或预算耗尽。select_best_code_candidate() 会在多次尝试之间评分选优,而不是取最后一次。
SandboxToolkit 用 Docker 容器做代码隔离,预装了 tarski(PDDL 解析库)、pddlgym(PDDL 强化学习环境)、pytest 等依赖,每次跑代码都在干净的环境里,避免状态污染。代码库里还有一个 mcts_gen.py,提供了另一条基于蒙特卡洛树搜索(MCTS)的生成路径——在搜索空间较大或需要多步规划的任务上可以替换默认的线性修复流程。每个 Agent 都设置了 max_turn=3 的轮次上限,防止某个 Agent 陷入无限循环。所有对话历史通过 auto_save=True 持久化,方便调试时追溯每次修复的具体内容。
论文报告通过 SFT 微调后在三个基准测试(CWMB、ByteSized32、Text2World)上平均提升 30.95%,这些修复轨迹本身成了有价值的训练数据。
主要劣势:多次 LLM 调用加上 Docker 执行,单个任务的延迟较高。PDDL 的表达力有边界,连续动作空间或高度依赖物理引擎的场景很难用它建模。
Pi:开发者的终端编码搭档
Pi Coding Agent (badlogic/pi-mono) 是一个完全不同类型的框架,定位是开发者日常用的终端编码 Agent。它不做仿真,不做科研,就是帮你在终端里写代码、读文件、执行命令。
Pi 的架构是 TypeScript monorepo,核心分三层:
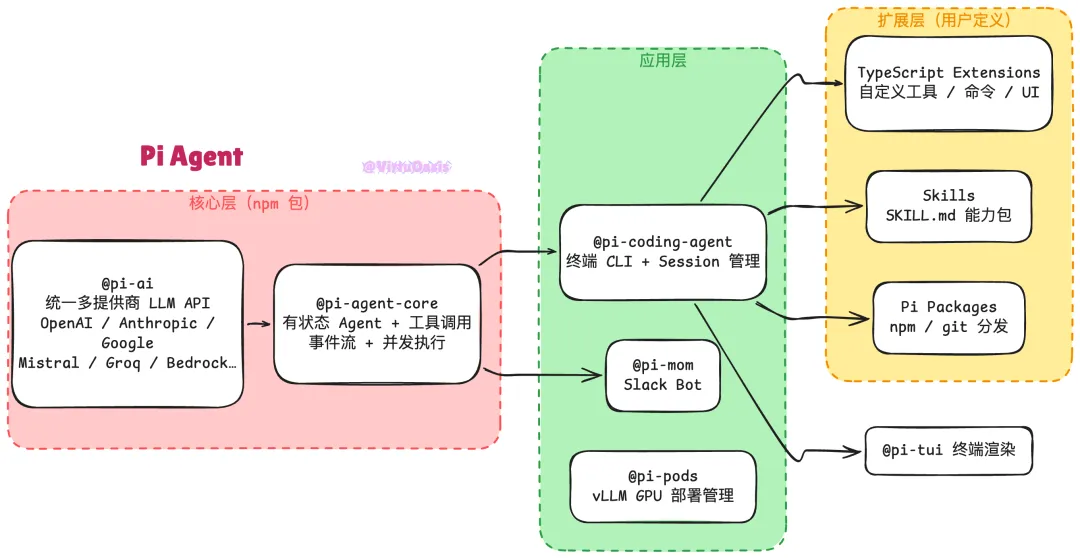
运行逻辑:调用 agent.prompt("...") 后,框架先把用户消息加入 AgentMessage[],经过可选的 transformContext(裁剪旧消息、注入外部上下文)再通过 convertToLlm 过滤转换成 LLM 能理解的格式,送去推理。LLM 如果返回工具调用,框架先并行执行 beforeToolCall 预检(可拦截),然后默认以并行模式跑所有工具,执行完毕后按原始顺序触发 afterToolCall,最后把工具结果作为新的消息继续推理,直到没有更多工具调用为止。整个过程发出细粒度的事件流:agent_start → turn_start → message_start/update/end → tool_execution_start/update/end → turn_end → agent_end,上层 UI 订阅事件流做实时渲染。
Session 以 JSONL 树形结构存储在 ~/.pi/agent/sessions/,每条记录都有 id 和 parentId,这让会话可以在任意节点原地分叉而无需复制文件。/tree 命令让你可以在会话树里任意跳转,切换到之前某个分支继续探索。上下文快满时会自动触发摘要压缩,但完整历史始终保留在 JSONL 文件里,可以随时翻查。steer() 和 followUp() 是两个不常被注意到的机制——steer() 在当前轮工具都跑完后插入消息,相当于"打断重定向";followUp() 在整轮结束后追加消息,相当于"排队追问",两者结合起来让人机交互在 Agent 运行中途也能保持流畅。Pi 支持通过 OAuth 登录接入 Anthropic Claude Pro/Max、OpenAI ChatGPT Plus/Pro 等订阅服务,不一定需要 API key——对于已有订阅的开发者来说,边际成本是零。
Pi 的设计哲学是刻意保持内核最小:不内置 MCP、不内置子 Agent、不内置计划模式、不内置权限弹窗。这些都可以通过 TypeScript Extension 自己实现,或者安装第三方 Pi Package。作者写了一篇博文专门解释为什么这些功能不应该内置,越通用的工具,越容易在每个功能上做一个差不多够用的版本;Pi 宁愿在核心层只保留 read、write、edit、bash 四个工具,让用户根据自己的工作流决定要什么。
实际应用:最直接的一个是 OpenClaw,Pi 的 README 里明确把它列为 SDK 用法的真实案例("See openclaw/openclaw for a real-world SDK integration")。
OpenClaw 是一个 7×24 在线的个人 AI 助手系统——把 Pi 的 agent-core 作为底层执行引擎,在上面叠加了三层持久化记忆(L1 会话上下文 / L2 近期摘要 / L3 跨月知识库)、10+ 消息平台接入、语音唤醒与通话、定时任务(Heartbeat/Cron)和浏览器操控。
Pi 提供状态管理、工具调用、事件流、多模型接入这些基础设施;OpenClaw 在此基础上定义了 Agent 的运行时环境、记忆架构和通信编排。这也是 Pi 那套"薄内核 + 扩展"哲学在生产环境里的一次落地。
相关阅读:OpenClaw 架构解析
Agent 在走向哪里
把这六个框架放在一起看,有几条线索可以串起来。
仿真与现实之间的距离在缩短。 Mesa 代表的那一代 ABM(Agent-based modeling),Agent 的行为是研究者手写的规则,可以精确控制,但表达空间有限。Concordia 和 AgentSociety 引入 LLM 之后,Agent 的决策变得更接近真实人类的模糊性和上下文依赖性——但这种接近是有代价的,可解释性和可复现性都变差了。OASIS 把这个趋势推向了规模边界,百万量级的 Agent 构成的仿真网络,和真实社交平台之间的形态差距已经很小。MiroFish 直接从这里迈出了一步:把仿真产品化,用群体行为预测现实世界的事件走向。这条从学术工具到预测产品的路径,仍然处于早期阶段,但方向很清晰。
从模拟人类行为,到生成人类行为的规则。 Agent2World 解决的问题和前四个框架完全不同——它要让 LLM 生成形式化的行为规则本身,而不只是执行规则。这个方向的挑战在于,LLM 的生成流畅度和符号系统的严格性之间存在天然张力。执行反馈闭环是目前最实用的解法,但它本质上是在用"试错"来弥补 LLM 对形式语言的掌握还不够精准的问题。随着模型对结构化输出的能力提升,这个闭环的迭代次数会减少,这类工具的应用范围才会真正扩大。
基础设施层在快速分化。 Pi 代表的一类框架关注的不是"Agent 应该做什么",而是"Agent 的底层应该长什么样"——状态管理、工具调用、事件流、Session 持久化、上下文压缩。这些东西在两年前还是各个项目里反复重写的样板代码,现在开始有了相对成熟的抽象。Pi 选择把这层做薄,OpenClaw 选择在上面堆厚——两种策略对应了不同的用户群体,但都指向同一个趋势:Agent 的执行基础设施正在从"每个项目各写一套"走向"有人专门维护一层"。
工具形态决定了能解决什么问题。 这六个框架里,有的把 Agent 理解为社会系统里的粒子,有的把它理解为角色扮演里的玩家,有的把它理解为能写代码的程序员,有的把它理解为能自我修复的代码生成器。这些理解上的差异,直接导致了截然不同的架构选择——内存怎么组织、行动空间怎么定义、环境怎么建模、反馈从哪里来。没有哪种理解是普遍正确的,但它们各自解决的问题域非常具体。
Agent 这个词本身太宽泛,真正值得关注的问题是:在某个具体场景里,哪种"Agent 的比喻"最接近你想建模的现实。
