OpenClaw成本控制实战手册 | 从月烧$1000到$20,我做对了什么?凌晨三点。手机屏幕亮了。不是女朋友的消息,是OpenAI的账单邮件。我手抖着点开——$1,278.42。那一刻,我感觉自己不是在养AI Agent,是在养一头吞金兽。这绝不是危言耸听。OpenClaw重度用户的日均Token消耗,轻轻松松就能飙到3000万至1亿。按国际顶尖模型的定价计算,单日费用可达900到3000美元。一个月下来,足够在二线城市付个首付了。我见过太多人,一边喊着"AI改变生产力",一边被账单吓得连夜删库跑路。今天这篇文章,我要把Token经济的底裤扒个干净。不是泛泛而谈的成本概念,是实打实的、能直接照搬的省钱攻略。一、先搞懂你在为什么买单
很多人用OpenClaw,压根不知道自己把钱烧在哪了。官方文档里那些"轻量级"、"高效"的形容词,翻译成人话就是:每一行代码、每一次点击、每一个思考步骤,都在按Token计费。根据行业数据,API Token调用占总成本的80%到95%。剩下的5%到20%是什么?是服务器、是带宽、是Gateway的维护成本。但大头,永远在那个你看不见的Token计数器里。Token是什么?简单说,就是AI处理文本的最小单位。一个汉字大约占2到3个Token,一个英文单词大约1到1.5个Token。听起来不多?但OpenClaw的Agent不是聊天机器人,它是持续运行的自动化程序。想象一下:你的Agent要打开一个网页,抓取数据,分析内容,生成报告。每一个步骤,都需要向大模型发送请求。网页内容越长,Token越多;分析越深入,Token越多;如果Agent陷入了"思考循环"——完了,账单开始指数级增长。我见过最惨的案例,是一个做电商数据分析的朋友。他的Agent负责监控竞品价格,本来设计得很好,但遇到某个竞品页面特别长,Agent陷入了无限滚动抓取的死循环。等他发现的时候,3个小时烧了400多美元。二、模型选型:别用牛刀杀鸡
OpenClaw默认推荐Claw-3.5-Sonnet,确实聪明,确实稳定。但聪明是有代价的——它的Token单价是GPT-3.5-Turbo的10倍以上。第一层:GPT-3.5-Turbo或本地Ollama。处理简单任务——数据清洗、格式转换、正则匹配。这些活儿不需要"思考",只需要"执行"。3.5足够用了,Token成本只有Claw的十分之一。第二层:Claw-3.5-Haiku。中等复杂度任务——简单的数据分析、内容摘要、基础决策。Haiku是Claw家族里的"轻量级选手",速度更快,价格只有Sonnet的三分之一。第三层:Claw-3.5-Sonnet或GPT-4。 reserved for真正需要深度推理的场景——复杂逻辑判断、创意写作、多步骤规划。而且,一定要设置Token上限,别让Agent无限思考下去。怎么在OpenClaw里实现这个分级?修改config.yaml里的模型配置,给不同技能(Skill)绑定不同的模型端点。比如,网页抓取用Ollama,数据分析用Haiku,最终报告生成用Sonnet。这一步,每个月能帮你省掉60%到70%的Token费用。三、Token压缩:每一分钱都要榨干价值
Prompt优化是第一战场。我见过太多人的Prompt写得像高考作文——冗长、模糊、充满废话。"请你作为一个专业的数据分析师,以严谨的态度,仔细分析以下数据..." 停。AI不需要你拍马屁,它需要的是指令。优化后的Prompt应该是:"分析以下CSV数据,输出:1.最大值 2.最小值 3.平均值。数据:[内容]"。字数减少50%,效果一样,Token成本直接砍半。上下文裁剪是第二战场。OpenClaw的Agent有"记忆"功能,会保留对话历史。但问题是——每次新请求,都会把历史记录一起发过去。10轮对话后,你的Prompt可能比原始任务还长。解决方案?定期清理上下文。在关键节点使用clear_context命令,或者设计"总结节点"——让Agent把之前的对话压缩成一段摘要,然后清空历史。这样,后续请求只需要携带摘要,而不是完整历史。缓存复用是第三战场。如果你的Agent经常执行相似任务——比如每天抓取同一个网站的数据——别每次都让AI重新理解网页结构。把解析逻辑固化成代码,或者把常见的分析框架预存为模板。第一次用AI生成,后面直接调用模板。Token只用一次,价值反复收割。四、零成本方案:Ollama本地部署实战
如果你连API费用都不想付——本地部署是唯一出路。Ollama是目前最成熟的本地大模型运行框架。支持Llama 3、Mistral、Qwen等一系列开源模型。在Mac上,M1/M2芯片可以直接调用GPU加速;在Windows上,虽然性能打折扣,但跑轻量级任务完全够用。安装Ollama:官网下载安装包,一路Next。
拉取模型:ollama pull llama3:8b(8B参数版本,适合8G内存以上机器)。
配置OpenClaw:修改config.yaml,把API端点指向http://localhost:11434/v1,模型名填llama3。
测试运行:启动OpenClaw,执行简单任务,观察响应速度。
电费是第一个坑。一块RTX 4090跑满负载,功耗450W。一天跑8小时,一个月下来电费轻松过百。如果你的任务量不大,API可能比电费还便宜。硬件折旧是第二个坑。大模型对显卡、内存、SSD都有要求。为了省API钱,花一万块配台机器,值不值?算笔账:如果每月API费用超过300美元,本地部署才划算。五、按次计费:阿里云百炼的隐藏玩法
如果你既不想折腾本地部署,又觉得OpenAI的账单太肉疼——国内云厂商的按次计费方案值得考虑。阿里云百炼推出的Coding Plan,专门针对代码生成和Agent场景。按Token计费,但价格比国际厂商低30%到50%。而且,新用户有免费额度,足够你跑完整个测试阶段。隐藏玩法是什么?错峰调用。百炼的定价分高峰期和非高峰期,非高峰时段(凌晨到上午)有额外折扣。如果你的Agent任务是定时执行的——比如每天生成报表——把执行时间调到凌晨,成本再降20%。最便宜的方案,不是"用免费模型",而是"精准控制上下文长度"。我见过太多人,为了省API钱,去折腾本地部署、去用弱鸡模型、去写复杂的缓存逻辑。结果时间成本、硬件成本、维护成本加起来,比直接付API费还贵。真正的省钱高手,是那些把每一次Token调用都设计得恰到好处的人。他们知道什么时候该用Claw-3.5-Sonnet,什么时候该用GPT-3.5-Turbo,什么时候该直接写代码不用AI。他们不是抠门,是精准。另一个反直觉的真相:本地部署的隐性成本(电费、硬件折旧、维护时间)可能比API更贵。除非你每天有大量调用,否则别轻易上本地。彩蛋
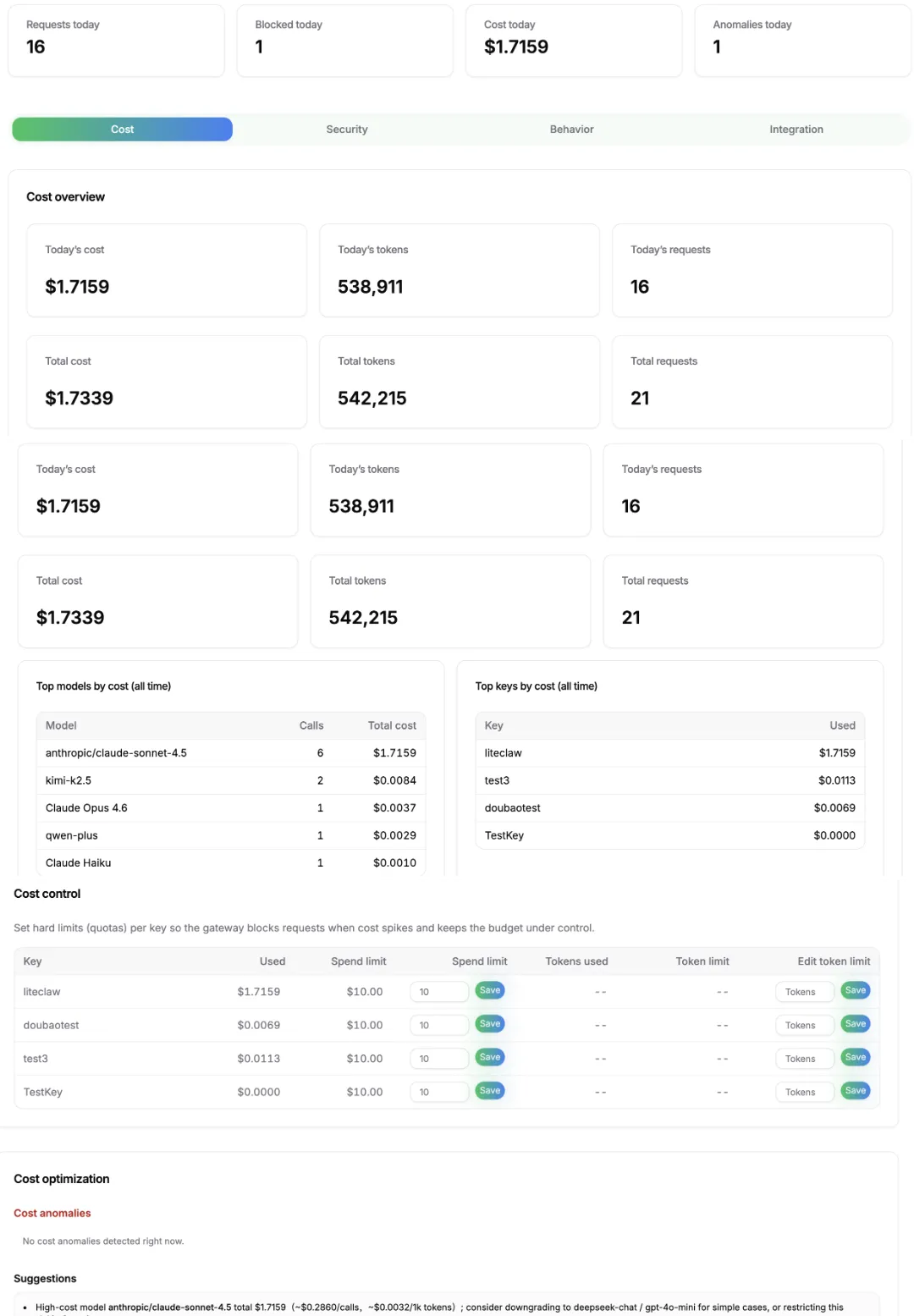
ClawFirewall(https://clawfirewall.ai)不只是个安全网关,它的**成本监控模块**被很多人忽视了。Token预算上限:单日/单周/单月,超支自动告警。
模型降级策略:当Token消耗达到阈值,自动切换到更便宜的模型。
任务熔断机制:当某个任务Token消耗异常(比如陷入死循环),自动中断并通知你。
这不是广告,是血泪教训的结晶。我那个烧了400美元的朋友,如果当时用了熔断机制,损失不会超过10美元。成本控制,本质上是对失控的恐惧的管理。ClawFirewall给了你一个安全网,让你敢用OpenClaw,敢让Agent自动化,而不用每5分钟刷一次账单页面。你可以在这里了解 ClawFirewall:
https://clawfirewall.ai
一个轻量级的 AI Gateway,用于:
控制 AI 成本
监控 Token 使用
保护 API Key
管理 AI Agent 调用
 夜雨聆风
夜雨聆风