 夜雨聆风
夜雨聆风摘要:Google 深夜发布 Gemma 4,四种规格覆盖手机到工作站,Apache 2.0 完全开源,31B 性能直接干到全球开源第三。这波是真·降维打击。 在第一时间在手机上和 19 年 mac 上进行了试用,在手机上运行的比电脑上还要流畅
01 / 四颗钻石,深夜突袭
北京时间 2026 年 4 月 3 日凌晨,Google 突然发布了新一代开源大模型 Gemma 4。

这次谷歌直接放出了四款不同规格的模型,覆盖了从端侧到云端的全场景:
E2B:20 亿参数,高效版,专为手机和边缘设备设计
E4B:40 亿参数,高效版,平衡性能和功耗
26B A4B:260 亿混合专家(MoE)架构
31B:310 亿稠密模型,主打极致推理性能
最让人惊喜的是,这次 Gemma 4 全系采用 Apache 2.0 协议,彻底放开了商业使用限制。对比上一代 Gemma 3 的自定义协议,这一步跨得相当大。
💡 划重点:Apache 2.0 = 可商用、可修改、可再分发,几乎没有任何限制。
02 / 参数不多,性能炸裂
Gemma 4 最让人震惊的不是参数规模,而是 单位参数的智能水平。
在 Arena AI 排行榜上:
Gemma 4 31B Dense冲到了全球开源模型第三名
Gemma 4 26B MoE排在第六
它们击败了一大堆参数量是自己 20 倍的"巨无霸"
官方数据显示,Gemma 4 带来了这些提升:
✅ 256K 超长上下文,轻松整本书处理
✅ 原生多模态支持,处理文本+图像(小模型还支持音频输入)
✅ 支持 140+ 种语言,中文优化更好
✅ 专为 Agent 工作流优化,更适合构建 AI 智能体
📊 Gemma 4 规格对比表
| E2B | |||
| E4B | |||
| 26B A4B | |||
| 31B |
03 / 端侧狂喜:手机就能跑强模型
这次谷歌重点照顾了端侧场景。Gemma 4 E2B/E4B被称为"最强手机端开源模型"。
根据社区评测,相比同尺寸其他模型,Gemma 4 在这些方面全面领先:
更长上下文:同样参数下能处理更长文本
原生语音支持:直接处理音频输入
推理能力更强:数学、逻辑题准确率更高
唯一短板是图像批量处理稍弱于 Qwen,但整体性价比已经拉满。对于想要做端侧 AI 应用的开发者来说,这基本是目前的最优解。
05 / 开源格局再次改变
Gemma 4 的发布,其实再次印证了一个趋势:开源模型正在快速追赶闭源,而且小而精的路线越来越吃香。
31B 参数就能打到全球第三,干掉很多 400B 级别的模型,这本身就说明架构和训练数据的优化空间还很大。
对于开发者和创业者来说,这是好事:
部署成本更低:不用买好多张 A100 也能玩得起
数据更安全:完全私有化部署,数据不出门
可定制性强:Apache 2.0 想怎么改就怎么改
💎 谷歌这波是直接把"单位参数性价比"拉到了一个新高度。接下来就看社区微调出多少神仙版本了。
05 / 怎么玩?
手机上怎么玩
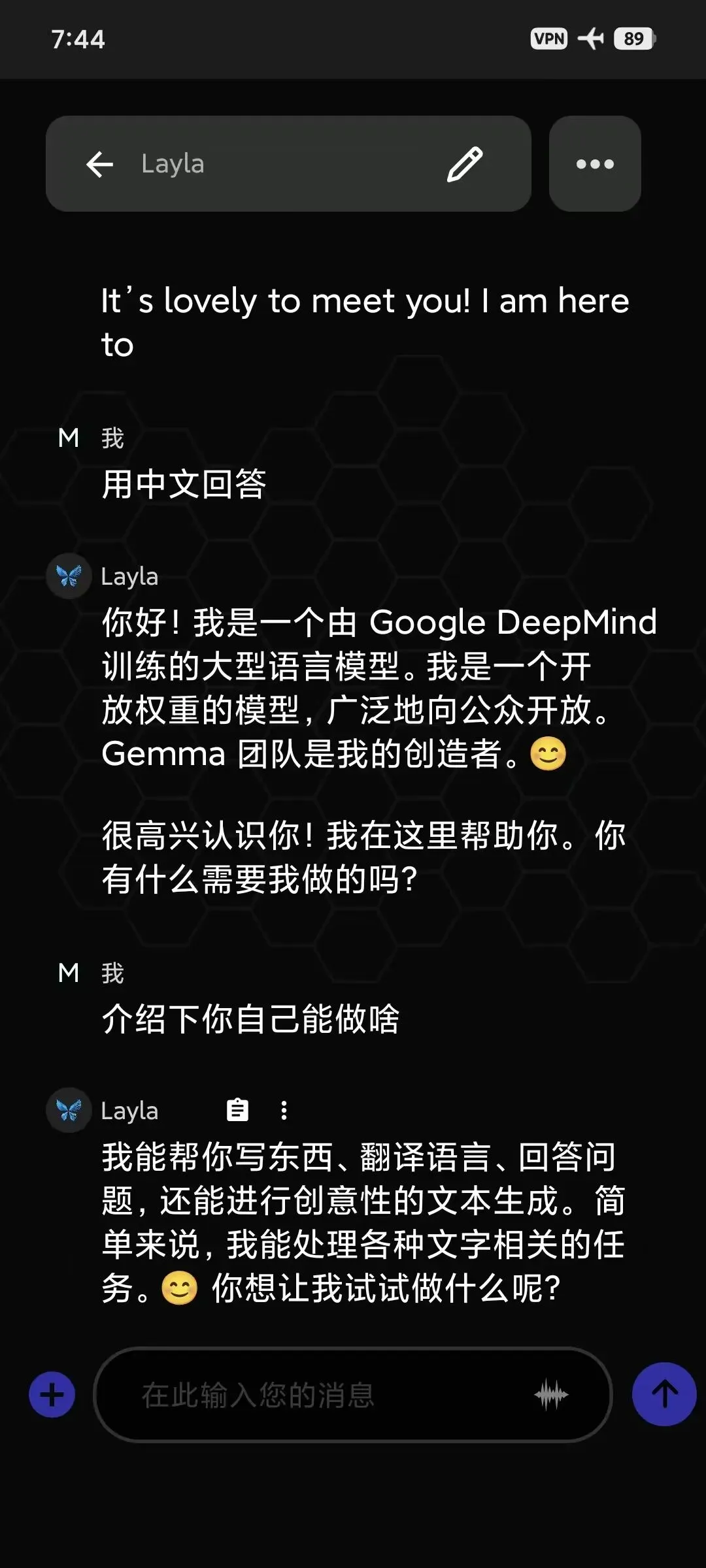
手机选用的不是很高端的 K80,通过 Layla 进行安装,若是你喜欢折腾,也可以通过 termux 安装,更加极客一些,不过为了试用,简单点。
Layla 内置了高度优化的
llama.cpp内核,能够完美调用骁龙 8 Gen 3 的 CPU (Cortex-X4 超大核)对于这个 APP,后面写个专门教程,敬请期待!
这个安装完成之后,也是可以直接点击下载模型,这个里面的是 4b,安装完成之后直接可以对话使用了,这里说下,我在飞行模式下进行的测试,可以看下效果。
电脑上怎么玩
MAC的配置是1.4 GHz 四核Intel Core i5加16G内存。通过 ollama运行,选取调教好的gemma-4-E4B-it运行
ollama run kwmcglon/gemma-4-E4B-it通过 ollama 运行后,对下面截图进行分析,整体运行时长145.9 seconds,内存飙升上去,但是还是可以接受的,对于多模态的理解也是不错的。
结果如下:
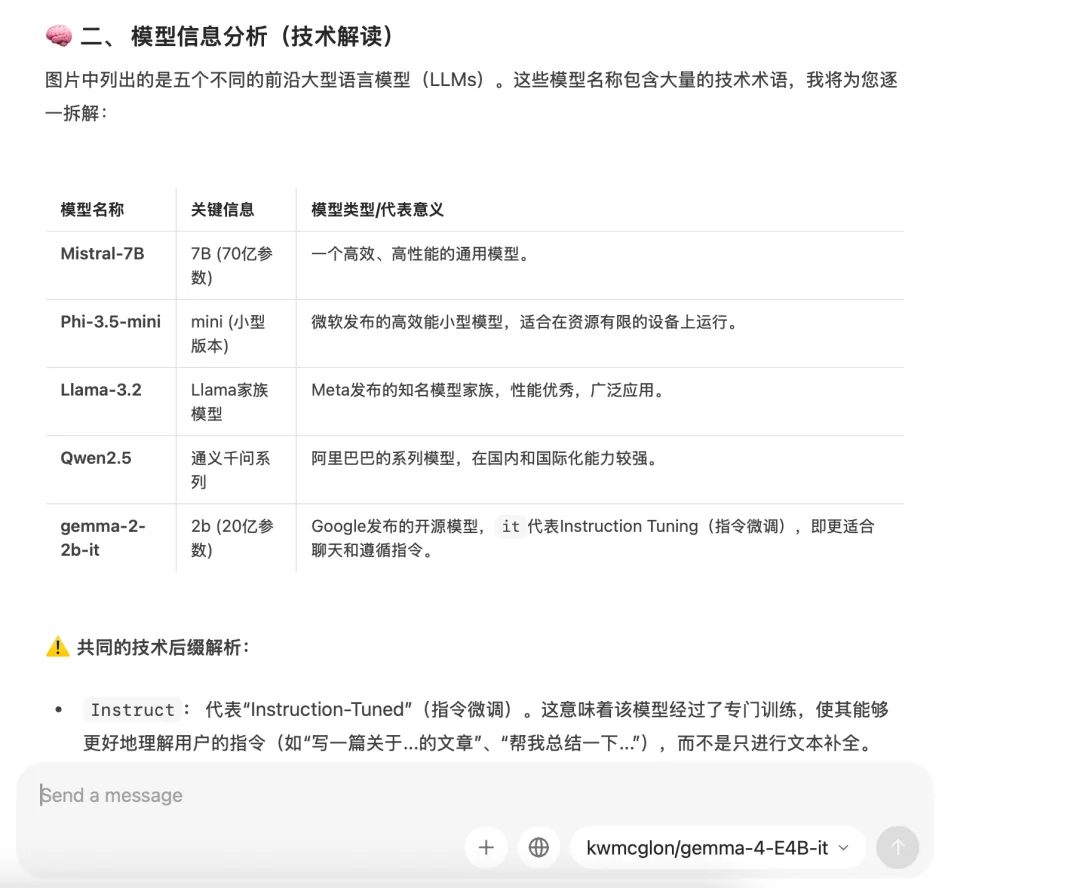
而对于那些信息是需要联网的,他的回答,关注隐私的朋友,这个用起来是没有任何问题的

总结
Gemma 4 不是那种参数堆到几千亿的"暴力美学",而是靠架构优化把"每一块钱的性能"做到极致。 Apache 2.0 协议 + 多规格覆盖 + 惊艳性能,这波谷歌是真的想把开源市场做实。接下来几个月,应该会有一大波基于 Gemma 4 的应用冒出来。
你准备升级了吗?
👇 关注我,获取更多 AI 前沿干货
