 夜雨聆风
夜雨聆风为什么要研究 OpenClaw 的架构?
最近 OpenClaw 在开发者社区里突然热了起来。
GitHub Star 数在短时间内快速增长,各个技术群里开始频繁出现它的名字,有人说「终于找到一个能在生产跑的 Agent 框架」,有人在分享自己用它接 Telegram、飞书、Discord 的经验,还有人直接把它部署在家里的 NAS 上当私人助理用。
我起初没太在意——AI Agent 框架这两年多如牛毛,大多数不是过度封装就是停留在 Demo 阶段。
但看到越来越多人认真在用,而不只是 Star 完就走,好奇心上来了:这东西到底哪里不一样?
于是我花了几天时间认真把它的架构拆了一遍。结论是:它火,是有道理的。
OpenClaw(也叫 ClawdBot)是一个开源的 AI Agent 运行时框架,跑在 Node.js 22+ 上,TypeScript ESM 编写。它的价值不在于「又封装了一层 LLM」,而在于它把多用户并发、上下文管理、记忆系统、工具执行这些工程问题,用一套清晰的架构设计逐一解掉了——而且解得相当漂亮。
这篇文章,我带你完整拆一遍它的架构——从顶层设计到每个环节的运行机制。
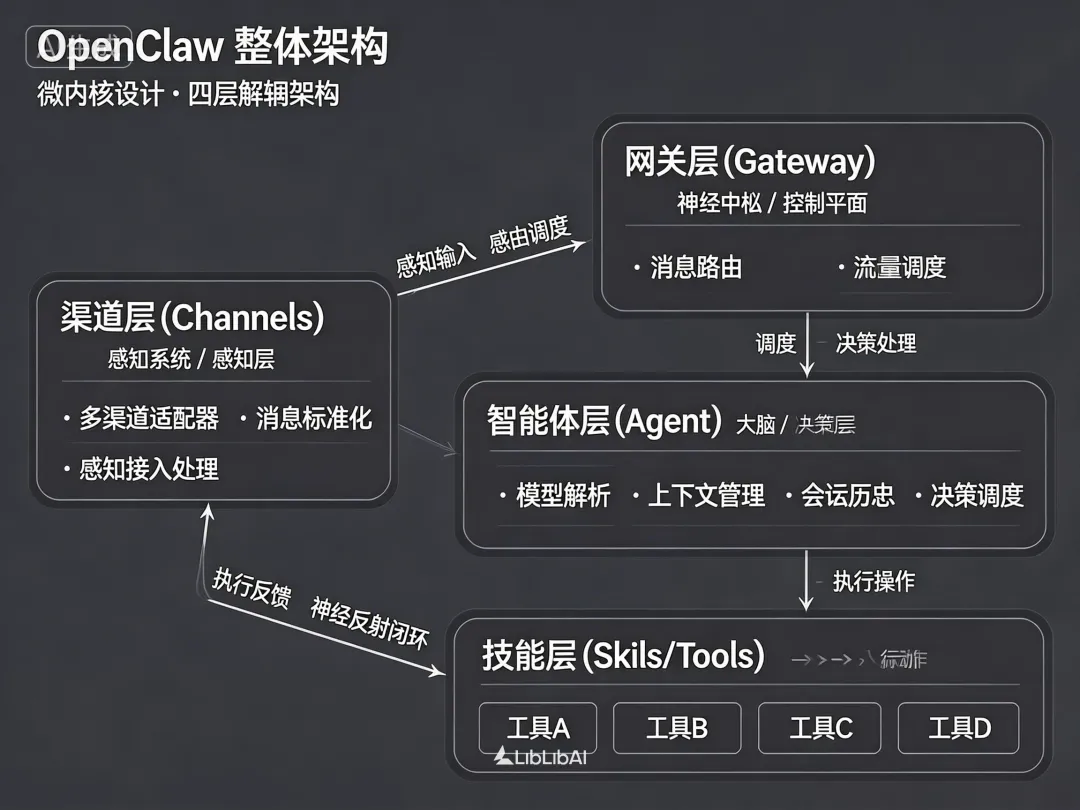
一、整体架构:像操作系统的微内核
先建立一个直觉——OpenClaw 的整体架构,设计灵感类似操作系统的微内核。
它采用四层逻辑架构:
图片由AI生成,供参考,曾在某视频号看到下图,亦可帮助理解。
网关层(Gateway) —— 神经中枢 / 控制平面渠道层(Channels) —— 感官系统 / 感知层智能体层(Agent) —— 大脑 / 决策层技能层(Skills/Tools) —— 执行系统 / 行动层这四层的职责划分极其清晰:感知、路由、决策、执行,各司其职,互相解耦。任何一层出了问题,都能快速定位,不会相互污染。
一条消息从进来到处理完毕,完整走下来,就像一次神经反射回路——从感知到行动,形成闭环。
二、渠道层:感官系统
职责:把外部世界的消息,变成 OpenClaw 能处理的标准格式。
OpenClaw 支持接入的平台包括:Telegram、WhatsApp、Discord、飞书、Teams、微信、Web UI、CLI……每个平台的消息协议都不一样。
渠道适配器做两件事:
1. 消息标准化:把不同平台的原始消息结构,统一转换成内部指令格式 2. 提取附件:图片、语音、文件,统一处理后交给后续流程
每个适配器独立运行,某个渠道挂了,不影响其他渠道,也不影响 Gateway 主循环。这种故障隔离是架构层面保证的,不是靠业务代码小心翼翼地 try-catch 实现的。
三、网关层:整个系统的神经中枢
职责:整个系统的调度核心,所有消息必须经过这里。
Gateway 是 OpenClaw 里设计最精密的一层,有几个细节值得单独展开说。
它在哪里运行?
Gateway 是一个 24/7 持久化 WebSocket RPC 服务器,默认运行在本机 127.0.0.1:18789(回环地址)。
默认只接受本机连接。如果要从远程接入,需要走 SSH 隧道或 Tailscale,配合 Token 认证和设备配对机制——安全边界清晰,不会暴露在公网。
Session Key:并发控制的枢纽
消息进来之后,Gateway 要做一件核心事:生成 Session Key。
格式长这样:
agent:<agentId>:<channel>:<type>:<identifier># 示例:agent:main:telegram:direct:+8613800138000这个 Key 完整编码了「谁在说话」「从哪个渠道来」「是什么对话类型」。不需要额外维护一张状态表,一个 Key 就是完整的上下文定位符。
车道队列:多用户并发的精妙解法
生成 Session Key 之后,消息进入车道队列(Lane Queue)。
这是 OpenClaw 里我觉得设计最克制的部分:
• 同一个 Session Key 的消息:串行处理,进同一条「车道」,先来先处理,不乱序 • 不同 Session Key 之间:并行执行,互不干扰 • 全局并发上限:防止 LLM 并发调用量失控
整套实现是纯 TypeScript + Promise,没有 Redis,没有消息队列中间件,就是几十行代码。它解决的是「多用户并发 + 单用户串行」这个经典矛盾,用的方式极其简单直接。
四、智能体层:大脑
职责:在当前 Session 真正「开始想」之前,把所有上下文准备好;然后驱动 LLM 完成决策。
Agent Runner 内部有三个核心组件。
模型解析器
根据配置和当前任务类型,决定用哪个 LLM。支持 Anthropic、OpenAI、Google Gemini、本地模型,并内置 Failover 降级链——主模型不可用时,自动切换备用模型,上层业务无感知。
System Prompt 构建器:Agent 的「人格装配线」
buildAgentSystemPrompt 按固定顺序,把以下内容逐段注入:
AGENTS.md | ||
SOUL.md | ||
TOOLS.md | ||
IDENTITY.md | ||
USER.md | ||
BOOTSTRAP.md | ||
| 8 | 历史记忆召回 | SQLite 混合搜索 |
第 8 条值得重点说:每次执行前,OpenClaw 会用混合搜索(向量搜索 0.7 权重 + FTS5 关键词搜索 0.3 权重)从本地 SQLite 记忆库里召回最相关的历史内容,注入当前上下文。这是 Agent 能「记住事情」的根本机制。
为什么用 Markdown 文件而不是 JSON/YAML?因为 LLM 天然读写 Markdown。把各部分拆成独立文件,LLM 可以直接用工具读写自己的「配置」,可读性和可维护性远好于一个大 JSON blob。
上下文窗口护栏
当上下文长度接近模型的 Token 上限时,护栏触发记忆刷写(Memory Flush):在正常对话之间插入一次「无声 turn」,先把当前上下文里的重要信息写入记忆库,再对历史对话做压缩处理。全程对用户透明。
很多框架遇到 Context Window 快满的时候,直接截断历史——信息白白丢掉。OpenClaw 选择先归档、再压缩。
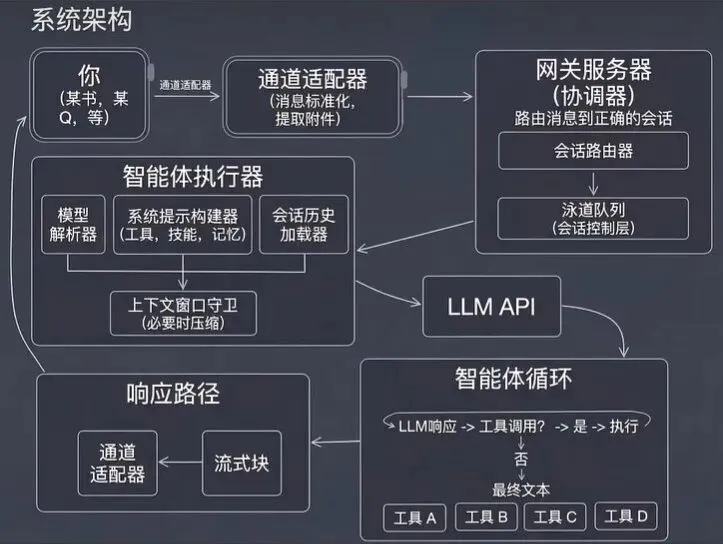
五、完整的运行闭环:一条消息的旅程
把四层串起来,看一条消息从进来到回复的完整过程:
① 消息入口用户通过聊天应用输入指令(比如「帮我搜一下最新 AI 论文」)。渠道适配器捕获消息,转换为标准化的内部指令格式。
② 网关路由Gateway 验证消息来源是否合法,生成 Session Key,将消息放入对应的车道队列,路由给对应的 Agent 处理。
③ 智能体决策Agent 加载当前会话的上下文(历史记录 + 记忆召回),组装 Prompt,发送给 LLM。LLM 返回结构化指令或可执行代码。
④ 技能执行(Agentic Loop)
LLM 响应回来之后,OpenClaw 不会直接把结果返回给用户,而是先判断:
LLM 回复 → 调用工具吗? │ ├─── 是 → 执行工具 → 把结果返回给 LLM → 继续下一轮 loop │ └─── 否 → 生成最终回复文本 → 进入回复路径这是标准的 ReAct 模式:先推理(Reason),再行动(Act),行动结果再喂回给 LLM,循环下去,直到 LLM 认为任务完成为止(响应中不再包含 tool_use block)。
OpenClaw 内置了两类工具:
• 核心工具: read/write/edit(文件操作)、exec(执行系统进程)• 扩展工具: browser(浏览器自动化)、memory_search(记忆检索)、web_fetch/web_search(网络)、canvas(界面渲染)、cron(定时任务)
插件可以注册自定义工具,onToolCall Hook 可以在执行前做拦截——比如危险操作需要人工确认,直接在这里加逻辑。
⑤ 响应反馈Agentic Loop 输出最终文本,通过渠道层发回聊天应用。支持流式返回,LLM 每生成一段,立刻推送出去,用户看到的是逐字出现。Gateway 同步通过 WebSocket 广播给所有订阅方(如 Web 管理面板),全程可观测。
六、记忆系统:Agent 的「长期记忆」
记忆系统贯穿整个流程,单独展开说。
OpenClaw 的记忆分两层:
• MEMORY.md:策展式长期记忆,由 Agent 自主判断哪些信息值得写入,是精华• memory/YYYY-MM-DD.md:每日流水日志,append-only,不做归纳
底层全部存在 SQLite(~/.openclaw/memory/<agentId>.sqlite),两种索引:
• 向量搜索:通过 sqlite-vec扩展,支持本地 GGUF 模型做 Embedding,不依赖云端服务• FTS5 全文搜索:SQLite 内置,关键词精确匹配
召回时加权合并:向量 0.7,FTS5 0.3。语义相关优先,兼顾关键词命中。
Embedding 的降级链:本地 GGUF → OpenAI → Gemini → Voyage → 彻底禁用向量功能。在没有网络或不想用云端 Embedding 的情况下,可以跑纯本地。
七、包结构速览
src/agents/ | |
src/agents/pi-embedded-runner/ | |
src/agents/system-prompt.ts | |
src/agents/model-selection.ts | |
src/memory/ | |
src/routing/ | |
src/hooks/ | |
src/cron/ | |
src/browser/ | |
src/telegram/src/discord/ | |
extensions/ |
依赖方向单向:Channel → Gateway → Agent Runtime。Agent Runtime 对上层一无所知,可以单独抽出来用,不绑定任何渠道。未来替换 Agent 引擎,只改 pi-embedded-runner 这一层,其余模块不动。
八、几点观察
车道队列那几十行代码,解决的是个经典难题。 多用户并发 + 单用户串行,如果上 Redis + 消息队列,运维成本一下就上来了。OpenClaw 用纯 Promise 实现,没有外部依赖,放在生产里跑完全没问题。技术选型的克制,往往比选「最先进」的方案更难。
Gateway 的安全边界设计得很干净。 默认只监听回环地址,外部接入强制走 SSH 隧道或 Tailscale,不会不小心暴露在公网。这种「默认安全」的设计思路,比「功能优先、安全靠后」靠谱得多。
Markdown 作为 LLM-Native 接口,确实比 JSON 好用。SOUL.md、IDENTITY.md、USER.md 这些文件,LLM 直接读得懂,也可以用工具直接写。这个思路在做 Agent 系统时值得借鉴——把 LLM 的配置和记忆设计成它自己能读写的格式。
五个环节,边界清晰到几乎一眼就能定位问题在哪层。 消息没到 Agent?查 Gateway。上下文组装不对?查 system-prompt.ts。工具没执行?查 Agentic Loop 的 onToolCall Hook。这种可观测性,在做了几个月维护之后,你会懂得有多值钱。
如果你要深入看源码
推荐从这几个文件入手:
• src/agents/pi-embedded-runner/run.ts— Agentic Loop 核心• src/routing/resolve-route.ts— 路由解析与 Session Key 生成• src/agents/system-prompt.ts— System Prompt 组装逻辑• src/gateway/server.impl.ts— Gateway 主服务入口
看完这四个文件,一条消息从进来到回复的整条链路,在脑子里就能跑通了。
觉得有用的话,转给同样在做 AI Agent 的朋友。有问题或者你也在研究这块,评论区见。
本文技术内容基于 OpenClaw 开源仓库及官方架构文档,截至 2026 年 4 月。
