 夜雨聆风
夜雨聆风上周我在读一篇英文技术文章,很长,想让 OpenClaw 帮我总结一下。
切回 OpenClaw,把链接丢进去,它确实能抓页面、能总结。但我停下来想了一秒:我明明就在浏览器里盯着这篇文章,为什么还要切出去跑这一圈?
这个痛点不复杂,但足够真实:浏览器是我们阅读内容最密集的地方,而我的 AI 助手就部署在本地,两者之间却没有一条直通的路。
于是我做了 WebClaw——一个连接浏览器与 OpenClaw 网关的 Chrome 扩展。
它解决的核心问题
WebClaw 本身不内置任何模型,也不需要你注册任何云端账号。它只做一件事:把你正在看的网页内容,送进你自己的 OpenClaw 对话流。
扩展通过 Chrome 侧栏工作,不打断你的阅读,随时唤出,随时收起。
三个我每天都在用的场景
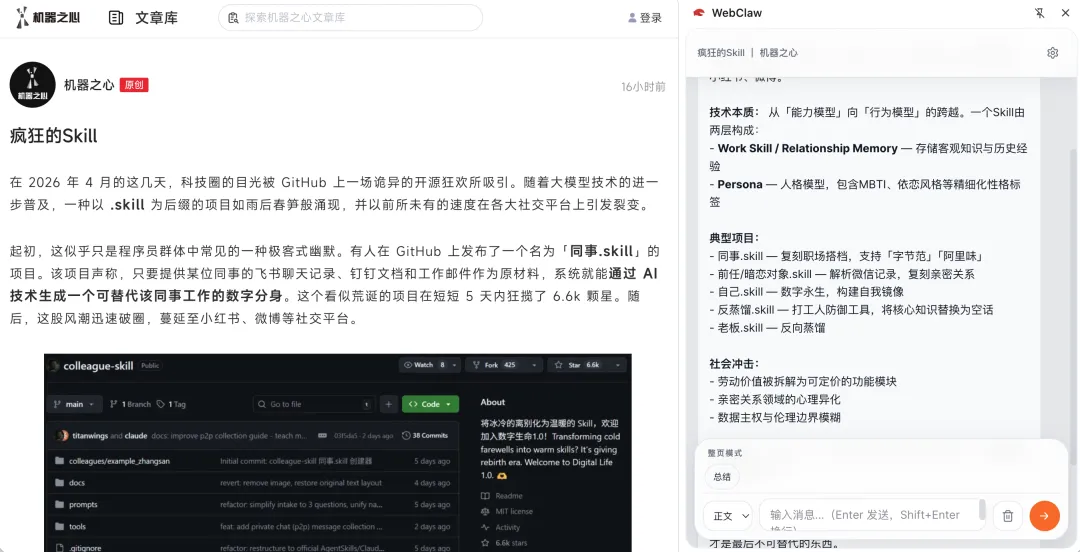
场景一:阅读网页,直接追问
打开一篇文章,侧栏里输入「总结这篇文章的核心观点」,回车。
WebClaw 会用 Readability 提取页面正文,转成干净的 Markdown,作为上下文发给 OpenClaw。不是截图,不是全页 HTML,是可读的结构化文本。
这一步解决的是**「读的成本」**——尤其是英文长文、技术文档、法律条款这类需要反复咀嚼的内容。我现在的习惯是打开文章,侧栏先问一遍「这篇在说什么、结论是什么」,确认值得深读再往下看。
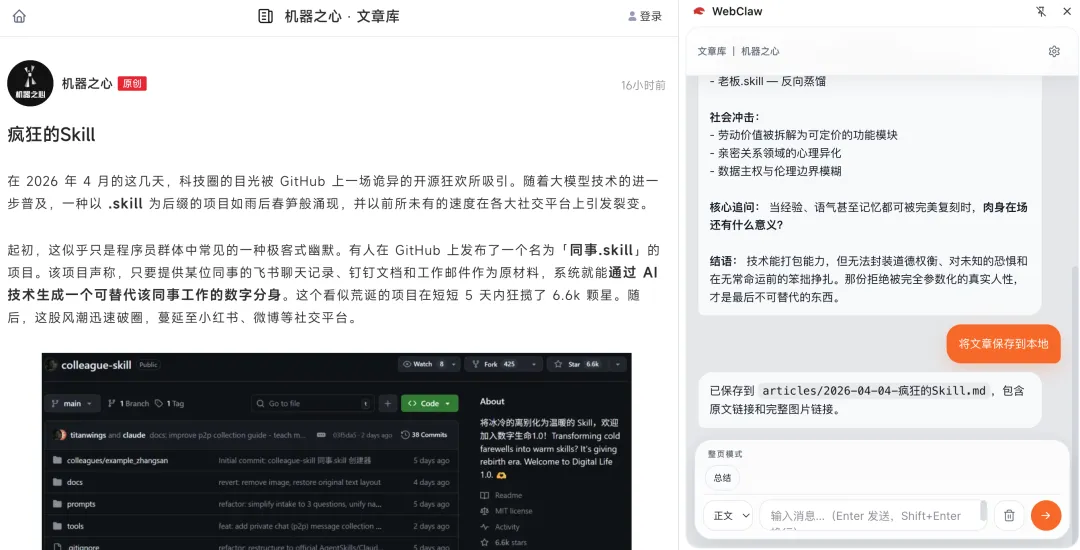
场景二:把网页内容存进本地
光总结还不够。很多时候我想把这篇文章的要点,归档进我的本地笔记。
这是 WebClaw 和普通浏览器插件最大的不同:网关侧的 Agent 可以操作本地文件。
一句话指令:「把这篇文章的摘要和来源 URL,追加到我的 reading-notes.md 里」,OpenClaw 的 Agent 就会完成这个写入动作。浏览器端负责把网页送进来,本地端负责落笔,两边通过同一个对话流打通。
不需要手动复制,不需要切换工具,阅读和归档在同一个动作里完成。

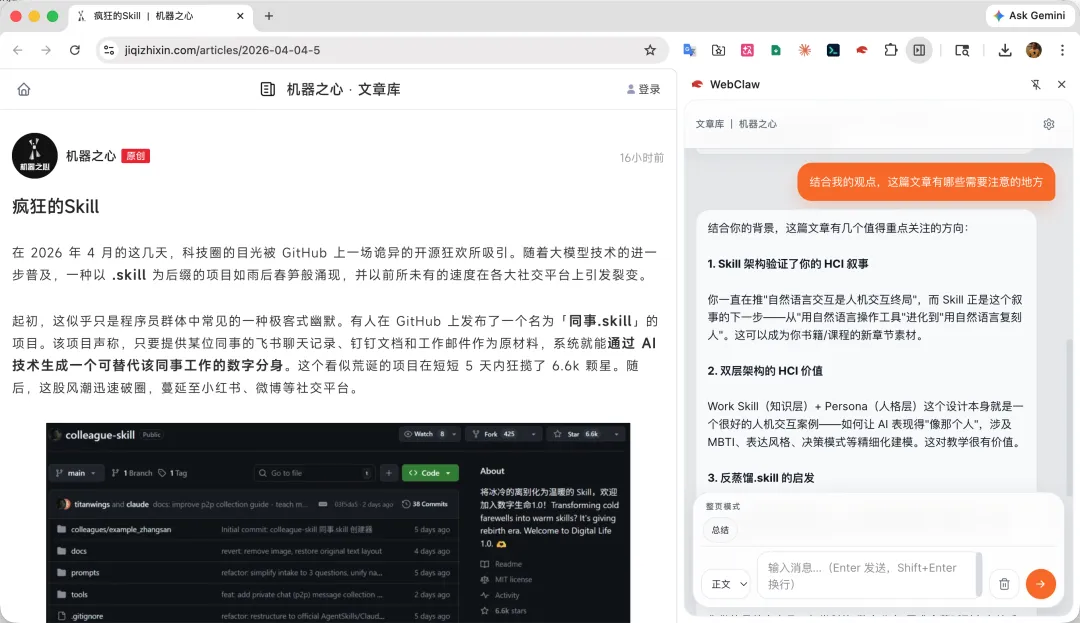
场景三:网页 + 本地知识,一起推理
这个场景是我觉得最有价值的。
比如我在看一个新的技术方案的介绍页,同时我本地有一个 architecture-notes.md,记录了我们项目现有的技术架构。我想知道:这个新方案和我们现有的架构兼容吗?引入它需要改哪些地方?
以前这个问题需要:打开文章读一遍,再打开笔记看一遍,在脑子里对比,然后自己写结论。
现在:侧栏里一句「结合我本地的架构笔记,分析这个方案的适配成本」,Agent 同时拿到网页上下文和本地文件,给出的回答是两边信息融合之后的判断,不是各说各的。
这才是我想要的 AI 阅读体验:不只是帮你读懂一篇文章,而是帮你把新信息和已有知识接起来。
如何使用
前提是你已经在本机跑起来了 OpenClaw。整个安装过程四步:
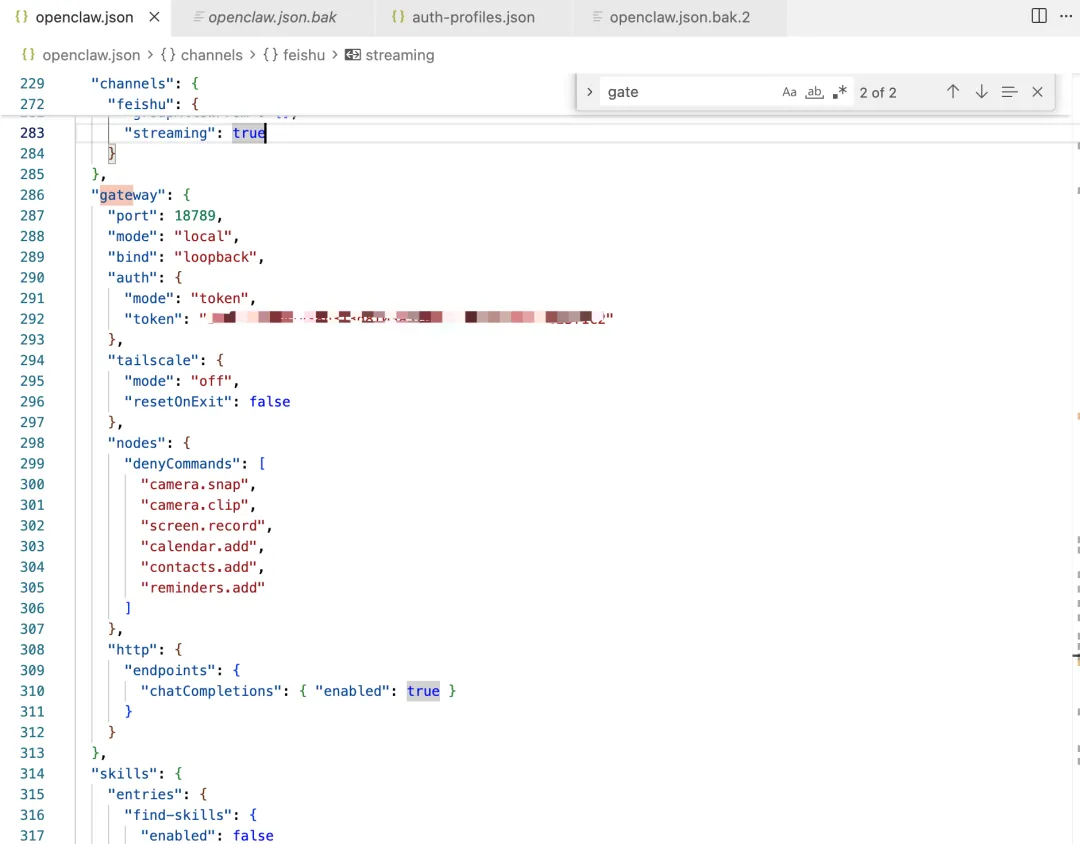
第一步:开启网关的 HTTP 接口
在 OpenClaw 的配置文件 openclaw.json 中加入以下内容,然后重启网关:
{ "gateway": { "http": { "endpoints": { "chatCompletions": { "enabled": true } } } }}这个接口默认是关闭的,WebClaw 依赖它来发送对话请求。
第二步:下载插件
前往 https://github.com/xue160709/WebClaw/releases/ 下载最新版压缩包。
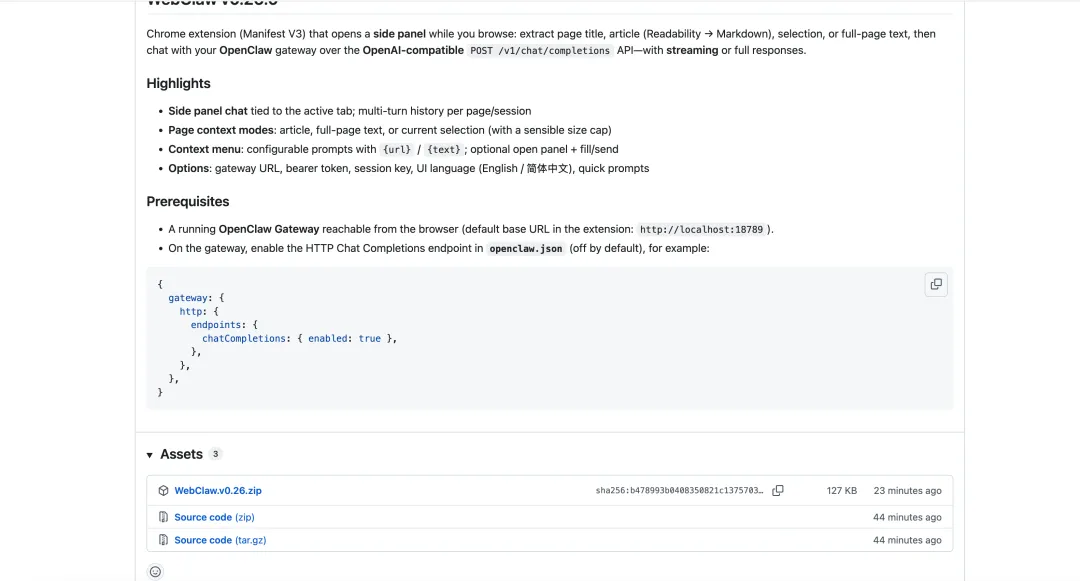
第三步:安装到 Chrome
解压后,打开 chrome://extensions,开启右上角「开发者模式」,点击「加载已解压的扩展程序」,选择解压出来的文件夹即可。
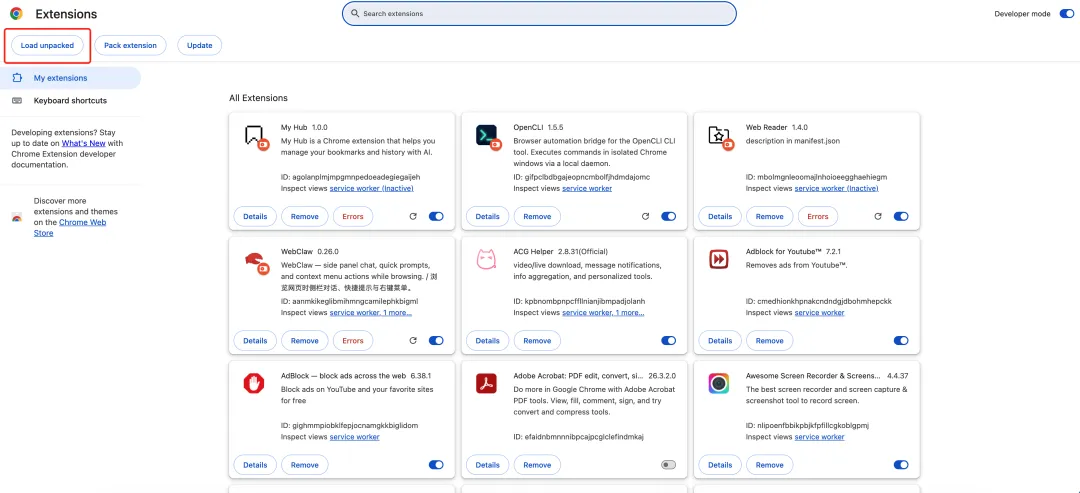
第四步:填写配置
点击插件图标,进入设置页,填入:
- 网关地址
:默认 http://localhost:18789 - Token
:你在 OpenClaw 中设置的鉴权 Token
保存之后,打开任意网页,点击工具栏图标唤出侧栏,就可以开始对话了。
最后说一句
我一直觉得,AI 工具的竞争力不在于模型本身有多强,而在于它能不能融进你真实的工作流。
浏览器是大多数人一天中打开时间最长的软件。如果 AI 助手只能在单独的对话框里工作,它始终是一个需要主动切换过去的工具,而不是一个随时在场的助手。
WebClaw 想做的,就是把这道门打开。
如果你喜欢这个项目,欢迎给WebClaw点一个Star🌟,谢谢
