 夜雨聆风
夜雨聆风零基础搞定分子对接 I ——数据下载
分子对接的核心前提,是拿到结构准确、匹配度高的受体与配体数据,这一步直接决定后续对接结果的可靠性。本期聚焦分子对接全流程第一步,手把手教你从权威数据库下载受体蛋白、筛选并获取适配配体,避开格式、配体活性等常见坑,快速搞定对接前的核心数据准备。符号、处事方式等组成的其特有的文化形象,简单而言,就是企业在日常运行中所表现出的各方各面。
前期准备:下载所需数据
只需要两类核心数据:受体蛋白结构、配体小分子结构,步骤如下:
下载受体蛋白(以EGFR为例)
1.打开数据库:RCSB PDB(https://www.rcsb.org),这是最权威的蛋白晶体结构数据库,免费可用。
2.搜索目标蛋白:在搜索框输入“EGFR”(表皮生长因子受体),点击搜索。
3.筛选最优结构:优先选「分辨率<3Å、含天然配体、无大量突变」的结构,本文选PDB ID:1M17。
4.下载结构:点击1M17进入详情页,找到“Download Files”,选择“Legacy PDB Format(gz)”,下载后保存为“1M17.pdb”,放在单独文件夹。
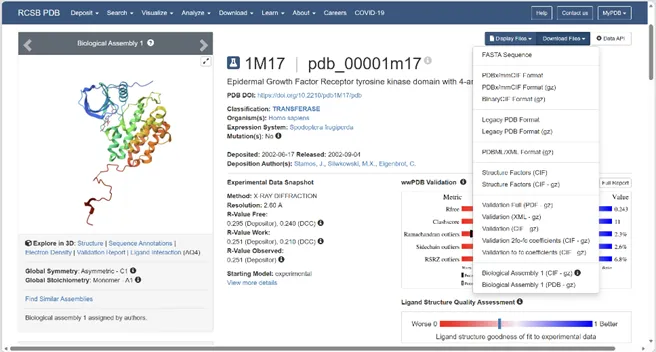
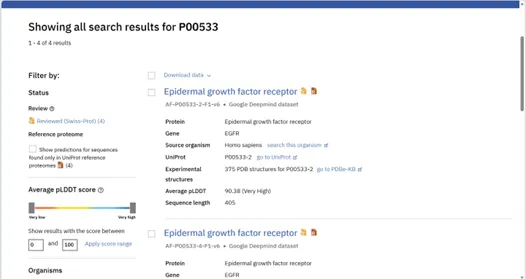
补充:若搜索不到目标蛋白的晶体结构,用AlphaFold DB(官网:https://alphafold.ebi.ac.uk),输入蛋白UniProt ID(如EGFR的ID:P00533),下载预测结构,步骤和上述一致,直接保存为PDB格式即可。
下载配体小分子
核心前提:多数分子对接场景,都是已知受体、筛选适配配体,先通过权威渠道找到能与受体结合的配体,再下载结构,新手按以下4种方法操作,命中率拉满:
▷ 方法1:从受体晶体结构中提取(最靠谱,零踩坑)
若受体是从PDB下载的晶体结构(如本文EGFR的1M17),大概率自带原配体(实验验证过能结合),步骤如下:
进入受体PDB详情页,下拉找到“Ligands”(配体)板块,查看原配体名称(1M17的原配体是厄洛替尼,对应配体ID:AQ4);
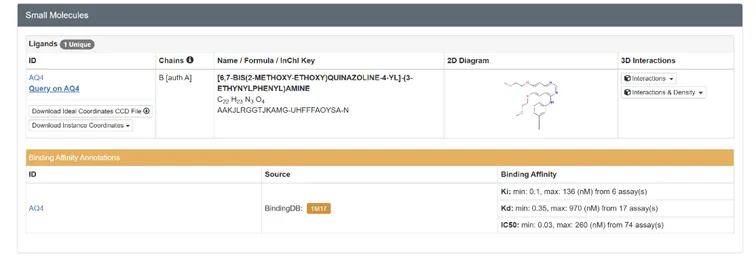
2.点击配体名称,进入配体详情页,下载配体结构,或直接用AutoDockTools从受体PDB文件中提取。
▷ 方法2:用ChEMBL查受体的已知活性配体(批量筛选)
打开ChEMBL数据库
(官网:https://www.ebi.ac.uk/chembl)
搜索框输入受体名称(如“EGFR”),点击搜索;
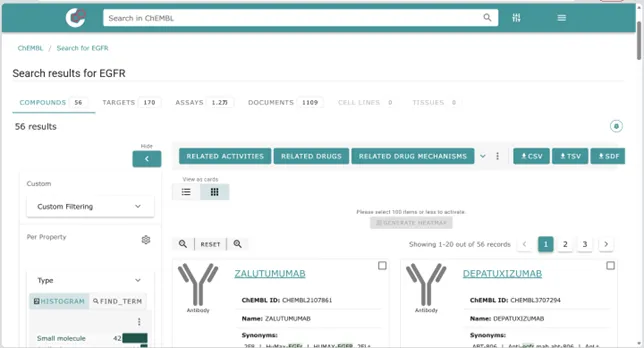
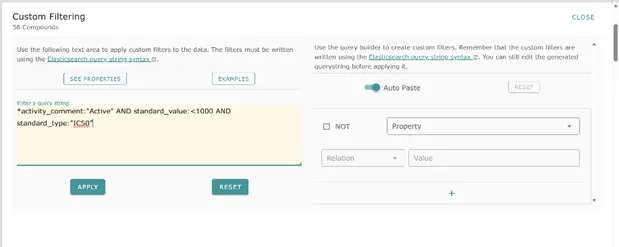
2.筛选条件:左侧点击“Custom Filtering”
activity_comment:"Active" AND standard_value:<1000 AND standard_type:"IC50"
把上面的代码复制,粘贴到左侧黄色的 “Enter a query string” 输入框里点击下方的 “APPLY” 按钮,等待页面刷新筛选完成后,就能看到所有和 EGFR 结合的强活性配体了;
3.选择配体:点击目标配体进入详情页,复制SMILES号,用于后续在PubChem下载结构。
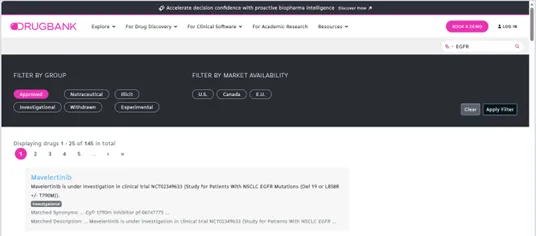
▷ 方法3:用DrugBank查受体的已批准药物(适合药物研发)
1.打开DrugBank数据库(官网:https://go.drugbank.com),输入受体名称(如“EGFR”),筛选“Approved”(已批准药物);
2.这类配体不仅能与受体结合,还具备成药性,直接点击药物名称,下载SDF格式结构即可。
▷ 方法4:PubChem下载配体结构(通用步骤,适配所有配体)
无论用哪种方法找到的配体,都可通过PubChem下载SDF格式,以厄洛替尼为例:
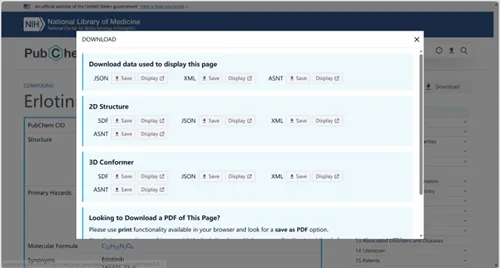
1.打开数据库:PubChem(官网:https://pubchem.ncbi.nlm.nih.gov),免费且化合物种类全,适合新手。
2.搜索小分子:在搜索框输入“Erlotinib”,点击搜索。
3.下载结构:进入厄洛替尼详情页,点击右上角“Download”,选择“3D Conformer” 下的 “SDF” 格式,保存为“Erlotinib.sdf”。
小提醒:文件夹建议命名为“分子对接实操”,文件命名用英文/数字(如1M17.pdb),避免中文导致软件报错。
🎯
本期结尾
好啦,今天的分子对接实操第一步就圆满结束啦。我们不仅精准搞定了1M17 受体蛋白和 AQ4 配体的正确下载,能顺利拿到适配后续操作的.pdb和.sdf文件,已经成功迈出了最关键的第一步!
🔜
下期预告
下一期我们会立刻进入「结构预处理」核心环节,手把手教你给蛋白 “去杂去水”、给配体 “优化构象”,还会解决大家问得最多的「预处理报错」「格式转换失败」等问题,保证让你跟着就能操作!
图文|刘子扬
排版|郑然希
审稿|袁峥嵘

